データ・メッシュ・アーキテクチャは、ドメイン固有の分析のためにデータ・アクセスを民主化し、ドメイン・エキスパートを各分野の責任者に割り当てることで、組織がAIを大規模に実現するのに役立つ。これにより、以下のようなデータ品質が向上する。 より良い、より正確なAI。
データ・メッシュ・アーキテクチャでは、ビジネス・ドメインがデータをデータ製品として所有・管理し、分析およびモデル・トレーニングのようなAI演習のための品質を保証する。これにより、アナリストやデータサイエンティストは、AIや機械学習アルゴリズムのために、高品質で、徹底的にクレンジングされ、十分に文書化されたデータにアクセスすることができ、精度を確保し、大規模言語モード(LLM)の幻覚のような現象を減らすことができる。
データ・メッシュ・アーキテクチャを探ることで、このコンセプトをより深く検証してみよう。
データメッシュとは何か?
企業の大小を問わず、日々のビジネスを運営する様々なシステムがある。例えば、ほとんどの組織では、営業業務用のCRM、財務管理用のERP、顧客サポート用のヘルプデスクシステム、製品開発用のプロジェクト管理アプリケーションなどがあります。企業のデータが正確かどうかを判断し、プロセスを改善し、ワークフローを合理化するためには、すべての業務にわたってパフォーマンスを正確に把握することが極めて重要です。
問題は、特定のビジネス領域だけが自分たちのデータを詳しく知っているため、分析や品質管理に問題が生じることだ。データのクリーンさと完全性が保証されないため、複数のドメインのデータを一元化されたデータリポジトリにまとめる従来のデータウェアハウスの取り組みが損なわれる可能性がある。そして ますます明白にデータの信頼性が低ければ低いほど、AIの効果も精度も低くなる。
データ・メッシュ・アーキテクチャは、ドメイン固有のデータを個々の分析リポジトリに分散し、各ドメインの所有権を分散させることで、これらの課題を克服する。これにより、各ドメインのデータは徹底的に吟味され、それぞれの専門家が即座に使用できるようになる。また、一元管理されたデータ共有ガイドラインとガバナンス基準により、異種ソースを統合することもできます。
データ・メッシュ・アーキテクチャでは、ビジネス部門は分析に使用するデータのコントロールを維持し、データへのアクセス方法を管理します。データメッシュは企業のデータエコシステムに複雑さを加える可能性がある一方で、データへのアクセスと品質を向上させることで効率化をもたらし、次のような効果をもたらします。 より良い分析 とAI。
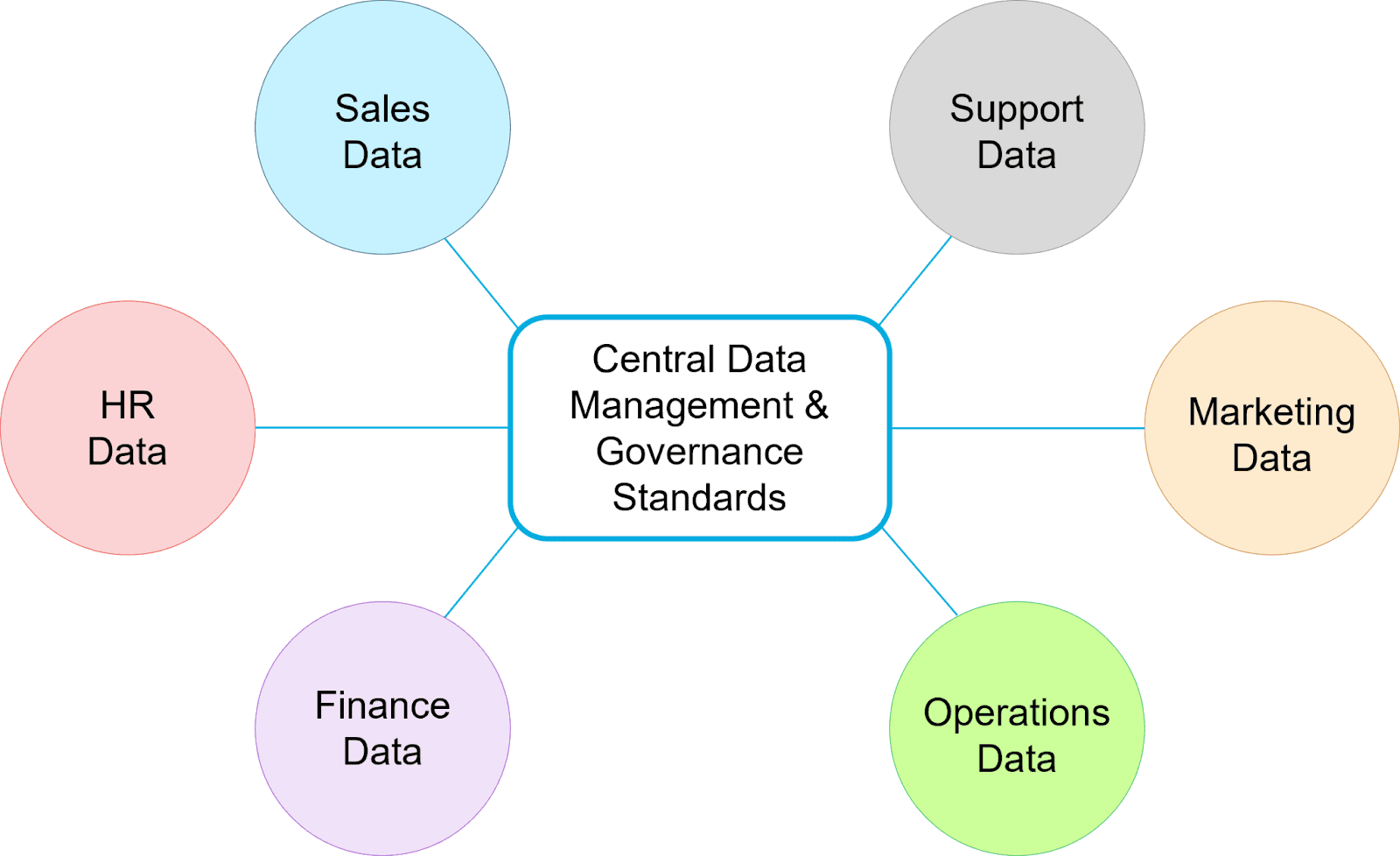
データ・メッシュ・アーキテクチャは、ドメイン固有のデータを各ビジネス・エリアの所有権の下に分散させる。
なぜデータメッシュなのか?
データ・メッシュ・アーキテクチャは、いくつかの基本的な課題に悩まされがちな従来の集中型データウェアハウスやデータレイクの実装を超える必要性から形成された:
- ほとんどの企業のデータの足跡は、様々な形式の多くの異種システムにまたがって断片化されているため、単一の真実のソースを確立することは、従来のアプローチではほぼ不可能である。
- AIの時代となった現在、ドメイン・データへの容易なアクセスに対する要求は、多くの企業におけるデータ量と同様に高まっている。そのため、ストレージとアクセスの処理に課題が生じている。
- データサイエンティストやアナリストは、必要な形式のデータにアクセスする必要がある。データは信頼できるものでなければならず、深い技術的知識やITの介入を必要としないものでなければならない。
一元化された分析システムにすべてのデータをロードすることで、これらの問題を解決しようとすると、独自の問題が発生します:データの質と適時性をどのように確保するか?データの質と適時性をどのように確保するか?新しいデータソースやデータ形式をどう扱うか?
データ・メッシュ・アーキテクチャは、データと分析システムの所有権をドメイン・エキスパートに分散させることで、こうした課題を克服しようとするものである。これにより、分析データのフットプリントが、より小さく、より管理しやすいドメイン固有のシステムに分散され、個々の管理が容易になります。各領域の専門家は自分のデータを最もよく知っており、データメッシュによってデータに直接アクセスできるため、データの品質と整合性が向上し、組織全体でより信頼性の高いデータを簡単に使用できるようになります。
データ・メッシュの原則
データ・メッシュ・アーキテクチャは、これらの一般原則に従っている:
1.データはドメインが所有しなければならない。
ビジネス・ドメインは、中央集権的なチームに所有権を委ねるのではなく、分析やAIのためにデータを管理し、キュレーションする。
2.データは、許可されたユーザーのためのセルフサービスでなければならない。
データアクセスを民主化するために、組織は抽象化によってアクセスを単純化し、厳格なセキュリティを犠牲にすることなく、可能な限り簡単にする必要がある。
3.データガバナンスは分散されなければならない。
データ管理、ストレージ、セキュリティ・ポリシーは一元管理されるが、各ドメインがデータ製品を所有するため、柔軟性と再現性のある構造が保証される。
4.データは製品として扱われなければならない(DaaP)。
上記の原則に従うことで、吟味され、高品質で、完全にクレンジングされたデータ製品が保証され、権限のあるコンシューマーは容易にアクセスして利用することができる。データメッシュアーキテクチャーでは、ドメインが、分析的なデータ製品から供給されたデータ製品を所有する。 オペレーションシステムそして、標準化された管理ガイドラインに従うことで、そのデータをより正確に、組織全体で利用しやすくする。
データメッシュの使用例
データ・メッシュ・アーキテクチャは、さまざまな業界や業種のさまざまなユースケースをサポートすることができる。いくつかの例を挙げよう:
顧客ライフサイクル
顧客エンゲージメントにまたがるシステムからのデータにアクセスすることで、企業はカスタマージャーニーを個別にも全体的にも360度リアルタイムで把握することができる。これにより、適切なオファーや提案で顧客をより迅速にエンゲージし、エンゲージメント全体の成功や失敗の理由を検証するAIを作成することができる。
AIと機械学習
データサイエンティストや高度なアナリストは、データがクリーンで最新かつ正確であることを確信しながら、AIや機械学習モデルに供給するための複数のソースに簡単にアクセスすることができる。
IoT環境モニタリング
データメッシュの分散型アーキテクチャにより、IoTデバイスの導入は、IoTアプリケーションを担当する個々の事業部門によって、より効果的に管理・監視される。
分散データ・セキュリティ・ポリシー
データ・メッシュのような分散モデルでは、データ・セキュリティが最も重要である。データ・プロダクトのセキュリティ・ポリシーの責任を個々のドメイン間で分担することで、データへのアクセスはドメインの専門知識に基づいてより適切に制限される。全体としてより詳細である一方、その粒度においては、一元化された画一的なセキュリティ・ポリシーよりも厳しい。
データ・メッシュの利点
データ・メッシュ・アーキテクチャには多くの利点があるが、中でも最も重要なものは以下の通りである:
データの俊敏性
データ・メッシュ・アーキテクチャは、様々なシステムからのデータへのアクセスを提供するためのITリソースへの依存を減らし、ビジネスチームが品質に集中し、より迅速にデータ製品を提供できるようにする。
AIのための高品質データ
各領域の専門家がデータを管理することで、その文脈と意味をより深く理解することができ、不正確な結果を減らし、より信頼できるデータを作成することができます。 LLM 幻覚。
より迅速なデータ利用
集中型データレイク・アプローチの主なボトルネックは、ソースの追加や更新にかかる時間であり、ソースを管理し、簡単に利用できるようにすることでもある。データ・メッシュ・アーキテクチャでは、データ・プロダクトの配信は順番に行われるのではなく、並行して行われるため、より迅速に行われる。
標準的な中央データガバナンスポリシー
一元化された厳格なガバナンス・ガイドラインに従うという基本原則があるため、データ・メッシュ・アーキテクチャは組織全体のデータ管理基準を設定すると同時に、各ドメインに自律性を与えている。
これらは、多くの組織がデータ・メッシュ・アーキテクチャを採用する理由の一部に過ぎない。
ダッシュメッシュ、データレイク、データファブリックの違い
組織のデータとAIのニーズを評価する際、データレイクやデータファブリックといった代替的なアプローチやアーキテクチャについて耳にすることは避けられない。その違いを簡単に説明しよう:
データレイク
A データレイク データレイクとは、様々なソースやシステムからのデータを一元的に保管するリポジトリのことで、様々なドメインにまたがるソースを集約して分析するために、すべてのデータが収集・保管される。データレイクは、より洗練された集中型データリポジトリであるデータウェアハウスに先行し、それを供給することもある。
データレイクとデータメッシュの基本的な違いは、前者が一元化されていることである。そのため、大規模で複雑な管理が必要となり、通常は専任チームが必要となる。
データファブリック
A データファブリック は、組織的な枠組みではなく技術的な枠組みを採用する点を除けば、データメッシュとコンセプトが似ている。データファブリックは一元化されたデータリポジトリを利用するが、厳密なアクセス制限プロトコルによって各ドメインや対象領域へのアクセスを分離する。これによって、ドメインが独自にドメイン固有のリポジトリを構築する必要性が軽減され、ドメインがデータ・ファブリックに直接関与することがなくなる。 日々のデータ管理.
データメッシュとデータファブリックの主な違いは、前者が分散モデルではなく技術的なフレームワークであることだ。対照的に、後者はデータ所有者としての組織ドメインに焦点を当てている。
データ・メッシュ・アーキテクチャの実装
分散型モデルだからだ、 リアルタイムの業務データ処理・分析プラットフォーム はデータ・メッシュ・アーキテクチャに最適な実装である。
このブログ は、Couchbase Capella™がデータメッシュ実装に最適なクラウドデータベースを提供する方法を説明します。一言で言えば、Couchbaseは以下を提供します:
多目的クラウドNoSQLデータベース
Couchbase Capellaは、ビルトインのキャッシュ、JSONドキュメントストレージ、SQLサポート、検索、イベント、モバイル同期を備えた多目的、開発者フレンドリーなデータベースです。これらの機能を組み合わせることで、組織は他の運用データベース技術を1つのソリューションに置き換えることができ、運用入力を減らすことでデータメッシュを簡素化できる。
即座の業務洞察
Capellaはまた、内蔵の 列分析サービス あらゆるオペレーション・データをリアルタイムで分析できる。その結果、データ・メッシュをループすることなく、その場で洞察を得ることができる。Capellaは特定のオペレーション・データを即座に分析し、その結果をより深い分析とAIのためにメッシュにフィードするために使用できるため、これはメッシュ全体をスピードアップします。
より迅速な洞察から行動へ
Capellaはイベント機能とユーザー定義機能を提供し、メッシュから分析的洞察を取得して運用レイヤーに戻すルーチンをスクリプト化できます。データレイクメッシュ上の機械学習アルゴリズムが過去のデータに基づいて新たな顧客分類を開発した場合、その分類を営業アプリに引き戻してターゲットを絞ったマーケティングを行うことができます。
開発の加速
カペラによって、組織は以下のことが可能になる。 膨大な業務データをデータベースに統合 SQL++(JSON用SQL)のサポート、豊富なSDK、そして完全にホストされたDBaaSにより、開発の摩擦が軽減されます。SQL++(JSON用SQL)のサポート、豊富なSDK、バックエンド管理サービス、そして完全にホストされたDBaaSは、開発の摩擦を軽減します。
データ・メッシュ・アーキテクチャの未来
業界全体のデジタル化に後押しされ、AIへの投資と開発によって加速されたデータ製品は、ほとんどの企業にとってますます重要になり、ドメインの所有とキュレーションの原則を遵守することで、データによって促進される将来のイノベーションの基礎を築くことができる。
試す Couchbase カペラ あなたのデータ・メッシュ・アーキテクチャ構想にどれだけ簡単に組み込めるか、実際に試してみてください。
を見ることもできる。 ハブ および以下の追加リソースで、データ・アーキテクチャに関連する一般的な概念について詳しく学ぶことができる:
データプラットフォームとは何か?
データ集約型アプリケーションのアーキテクチャ例
Couchbaseにおけるマイクロサービスアーキテクチャの4つのパターン