
Eine Data-Mesh-Architektur kann ein Unternehmen dabei unterstützen, KI in großem Umfang zu ermöglichen, indem der Datenzugriff für bereichsspezifische Analysen demokratisiert wird und Experten die Verantwortung für die einzelnen Themenbereiche zugewiesen wird. Dies verbessert die Datenqualität für bessere, genauere KI.
In einer Data-Mesh-Architektur besitzen und pflegen die Geschäftsbereiche ihre Daten als Datenprodukt, um deren Qualität für Analysen und KI-Übungen wie Modelltraining zu gewährleisten. Dies ermöglicht Analysten und Datenwissenschaftlern den Zugriff auf qualitativ hochwertige, gründlich bereinigte und gut dokumentierte Daten für KI- und maschinelle Lernalgorithmen, wodurch die Genauigkeit gewährleistet und Phänomene wie die Halluzinationen des Large Language Mode (LLM) reduziert werden.
Betrachten wir dieses Konzept genauer, indem wir uns die Architektur des Datennetzes ansehen.
- Was ist ein Datennetz?
- Warum Datengitter?
- Grundsätze der Datenvernetzung
- Anwendungsfälle der Datenvernetzung
- Vorteile der Datenvernetzung
- Der Unterschied zwischen Dash Mesh, Data Lake und Data Fabric
- Implementierung einer Datengitterarchitektur
- Die Zukunft der Datengitterarchitektur
Was ist ein Datennetz?
Unternehmen, ob groß oder klein, haben verschiedene Systeme, die das Tagesgeschäft steuern. In den meisten Unternehmen gibt es beispielsweise ein CRM für den Vertrieb, ein ERP für die Finanzverwaltung, ein Helpdesk-System für den Kundensupport, eine Projektmanagement-Anwendung für die Produktentwicklung usw. Es ist von entscheidender Bedeutung, einen genauen Einblick in die Leistung aller Abläufe zu erhalten, um festzustellen, ob die Daten Ihres Unternehmens korrekt sind, um Prozesse zu verbessern und Arbeitsabläufe zu rationalisieren.
Das Problem ist, dass nur bestimmte Geschäftsbereiche ihre Daten bis ins Detail kennen, was zu Problemen bei der Analyse und Qualitätskontrolle führt. Dies kann herkömmliche Data-Warehouse-Bestrebungen untergraben, die Daten aus verschiedenen Bereichen in einem zentralen Datenspeicher zusammenführen, da die Sauberkeit und Integrität der Daten nicht garantiert werden kann. Und wie das immer deutlicher werdendJe weniger vertrauenswürdig die Daten sind, desto weniger effektiv und genau ist die KI.
Eine Data-Mesh-Architektur überwindet diese Herausforderungen, indem sie bereichsspezifische Daten auf einzelne analytische Repositories verteilt und die Verantwortung für jeden Bereich dezentralisiert. Auf diese Weise wird sichergestellt, dass die Daten jedes Bereichs gründlich geprüft und von den jeweiligen Experten sofort verwendet werden können. Außerdem werden unterschiedliche Quellen durch zentral verwaltete Richtlinien und Governance-Standards für die gemeinsame Nutzung von Daten zusammengeführt.
Mit einer Data-Mesh-Architektur behalten die Geschäftsfunktionen die Kontrolle über die für die Analyse verwendeten Daten und bestimmen, wie auf ihre Daten zugegriffen wird. Ein Datengeflecht kann das Datenökosystem eines Unternehmens zwar komplexer machen, bringt aber auch mehr Effizienz, da der Datenzugriff und die Datenqualität verbessert werden, was wiederum die bessere Analyse und KI.
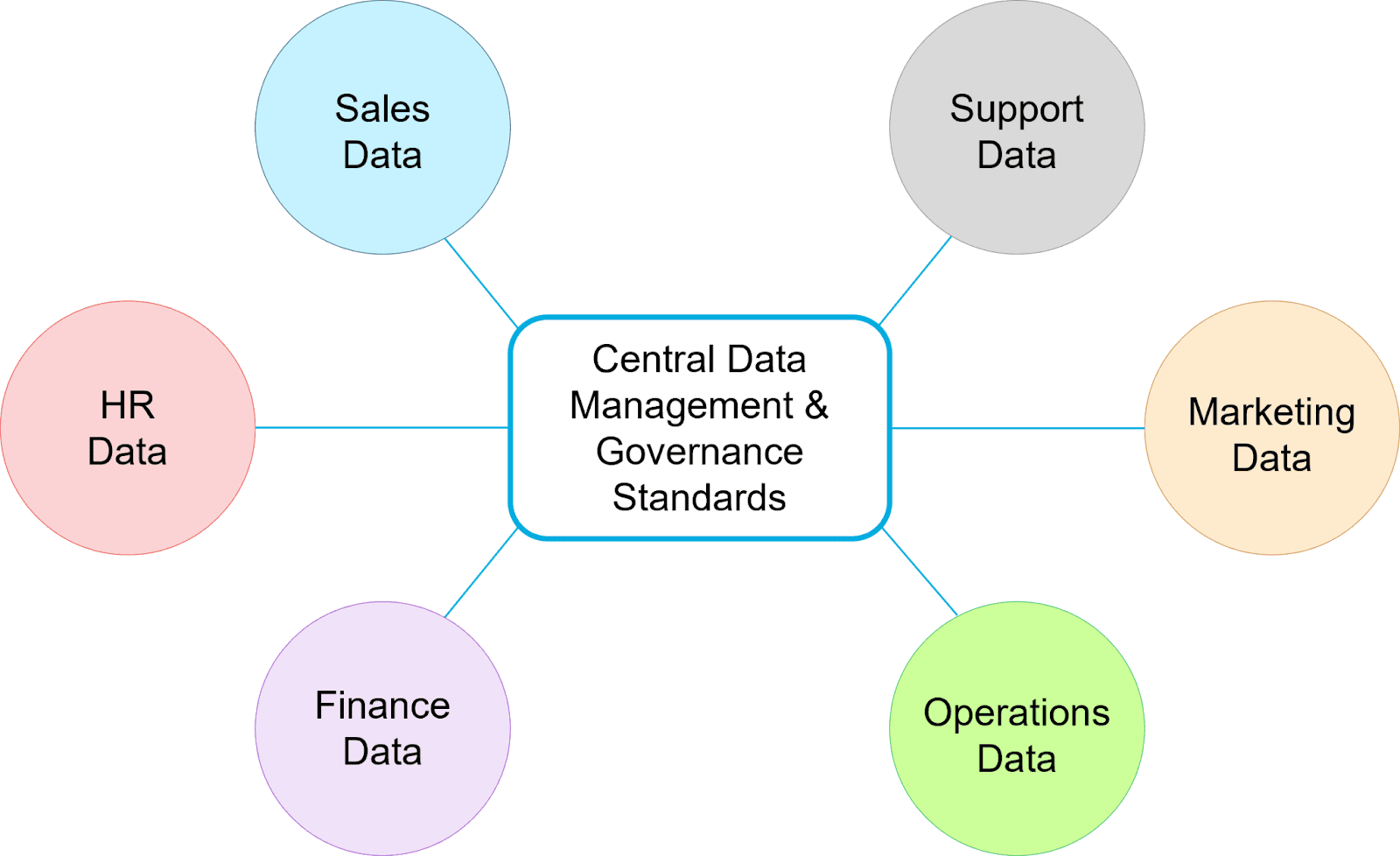
In einer Datennetzarchitektur werden bereichsspezifische Daten unter der Verantwortung der einzelnen Geschäftsbereiche verteilt.
Warum Datengitter?
Die Data-Mesh-Architektur entstand aus dem Bedürfnis heraus, über die traditionellen zentralisierten Data-Warehouse- oder Data-Lake-Implementierungen hinauszugehen, die mit einigen grundlegenden Problemen zu kämpfen haben:
- Die Schaffung einer einzigen Quelle der Wahrheit kann mit herkömmlichen Ansätzen nahezu unmöglich sein, da die Daten der meisten Unternehmen über viele verschiedene Systeme in unterschiedlichen Formaten verteilt sind.
- Im Zeitalter der künstlichen Intelligenz (KI) steigt die Nachfrage nach einem einfacheren Zugriff auf Domaindaten, ebenso wie das Datenvolumen in den meisten Unternehmen. Dies führt zu Herausforderungen bei der Handhabung von Speicherung und Zugriff.
- Datenwissenschaftler und Analysten benötigen Zugang zu Daten in den von ihnen benötigten Formaten. Die Daten müssen vertrauenswürdig sein und dürfen keine tiefen technischen Kenntnisse oder IT-Eingriffe erfordern.
Der Versuch, diese Probleme zu lösen, indem alle Daten in ein zentrales Analysesystem geladen werden, führt zu eigenen Problemen: Wie stellen Sie die Qualität und Aktualität der Daten sicher? Wie gehen Sie mit sich schnell ändernden Daten um? Wie geht man mit neuen Datenquellen und -formaten um?
Die Data-Mesh-Architektur versucht, diese Herausforderungen zu überwinden, indem sie die Verantwortung für Daten und Analysesysteme auf Fachleute verteilt. Dadurch werden die Analysedaten auf kleinere, besser verwaltbare bereichsspezifische Systeme verteilt, die sich leichter einzeln verwalten lassen. Da jeder Fachbereichsexperte seine Daten am besten kennt und mit dem Datengeflecht direkten Zugang zu ihnen hat, werden Datenqualität und -integrität verbessert, so dass sie im gesamten Unternehmen zuverlässiger und einfacher genutzt werden können.
Grundsätze der Datenvernetzung
Die Architektur des Datennetzes folgt diesen allgemeinen Grundsätzen:
1. Die Daten müssen den jeweiligen Bereichen gehören.
Geschäftsbereiche kuratieren und verwalten ihre Daten für Analysen und KI, anstatt die Verantwortung an zentralisierte Teams zu delegieren.
2. Die Daten müssen für autorisierte Benutzer zur Selbstbedienung zur Verfügung stehen.
Um den Datenzugriff zu demokratisieren, müssen Unternehmen den Zugriff durch Abstraktion vereinfachen und so einfach wie möglich gestalten, ohne dabei auf strenge Sicherheit zu verzichten.
3. Die Datenverwaltung muss verteilt werden.
Die Richtlinien für Datenverwaltung, -speicherung und -sicherheit werden zentral verwaltet, aber jeder Bereich ist Eigentümer seiner Datenprodukte, was Flexibilität und eine wiederholbare Struktur gewährleistet.
4. Daten müssen wie ein Produkt behandelt werden (DaaP).
Die Einhaltung der oben genannten Grundsätze gewährleistet geprüfte, qualitativ hochwertige und vollständig bereinigte Datenprodukte, auf die autorisierte Nutzer problemlos zugreifen und sie nutzen können. In einer Data-Mesh-Architektur sind die Domänen Eigentümer ihrer Datenprodukte, die aus analytischen und operative SystemeDurch die Befolgung standardisierter Verwaltungsrichtlinien werden diese Daten genauer und für das gesamte Unternehmen zugänglich.
Anwendungsfälle der Datenvernetzung
Eine Data-Mesh-Architektur kann viele verschiedene Anwendungsfälle in einer Vielzahl von Branchen und vertikalen Bereichen unterstützen. Einige Beispiele sind:
Lebenszyklus des Kunden
Durch den Zugriff auf Daten aus kundenübergreifenden Systemen erhalten Unternehmen einen 360-Grad-Blick auf die Customer Journey, sowohl einzeln als auch in ihrer Gesamtheit, in Echtzeit. Dies ermöglicht es dem Unternehmen, KI zu entwickeln, die Kunden schneller mit relevanten Angeboten und Vorschlägen anspricht und die Gründe für Erfolge oder Misserfolge bei der allgemeinen Kundenbindung untersucht.
KI und maschinelles Lernen
Datenwissenschaftler und fortgeschrittene Analysten können problemlos auf verschiedene Quellen zugreifen, um KI- und maschinelle Lernmodelle zu füttern, und sich darauf verlassen, dass die Daten sauber, aktuell und genau sind.
IoT-Umgebungsüberwachung
Die verteilte Architektur in einem Datennetz ermöglicht es den einzelnen Geschäftsbereichen, die für IoT-Anwendungen zuständig sind, IoT-Geräte effektiver zu verwalten und zu überwachen.
Verteilte Datensicherheitspolitik
In einem verteilten Modell wie dem Datennetz ist die Datensicherheit von größter Bedeutung. Durch die Aufteilung der Verantwortung für die Sicherheitsrichtlinien für Datenprodukte auf die einzelnen Bereiche wird der Zugriff auf die Daten auf der Grundlage des Fachwissens der Bereiche angemessener eingeschränkt. Sie ist zwar insgesamt detaillierter, aber in ihrer Granularität auch strenger als eine zentralisierte, einheitliche Sicherheitsrichtlinie.
Vorteile der Datenvernetzung
Es gibt viele Vorteile einer Datenverflechtungsarchitektur, zu denen einige der wichtigsten gehören:
Beweglichkeit der Daten
Die Data-Mesh-Architektur reduziert die Abhängigkeit von IT-Ressourcen, die den Zugriff auf Daten aus verschiedenen Systemen ermöglichen, so dass sich die Geschäftsbereiche auf die Qualität konzentrieren und Datenprodukte schneller bereitstellen können.
Hochwertige Daten für AI
Da die Daten von einzelnen Fachleuten verwaltet werden, führt ihr tieferes Verständnis des Kontexts und der Bedeutung der Daten zu besser kuratierten, vertrauenswürdigeren Daten, was entscheidend ist, um ungenaue Ergebnisse zu reduzieren und LLM Halluzinationen.
Schnellere Datenverfügbarkeit
Ein Hauptengpass des zentralisierten Data-Lake-Ansatzes ist die Zeit, die benötigt wird, um Quellen hinzuzufügen und zu aktualisieren, geschweige denn sie zu verwalten und leicht verfügbar zu machen. Mit einer Data-Mesh-Architektur erfolgt die Bereitstellung von Datenprodukten parallel und nicht nacheinander, was zu einer schnelleren Bereitstellung führt.
Zentrale Standardrichtlinien zur Datenverwaltung
Aufgrund ihres Kernprinzips, zentralisierte, strenge Governance-Richtlinien zu befolgen, setzt die Data Mesh-Architektur einen Standard für die Datenverwaltung im gesamten Unternehmen und bietet gleichzeitig jedem Bereich Autonomie.
Dies sind nur einige der Gründe, warum viele Unternehmen eine Datengitterarchitektur einsetzen.
Der Unterschied zwischen Dash Mesh, Data Lake und Data Fabric
Wenn Sie die Daten- und KI-Anforderungen Ihres Unternehmens bewerten, werden Sie unweigerlich von alternativen Ansätzen und Architekturen hören, wie z. B. einem Data Lake oder einer Data Fabric. Hier sind die Unterschiede in aller Kürze:
Datensee
A Datensee ist ein Begriff, der sich auf ein zentrales Repository für Daten aus verschiedenen Quellen und Systemen bezieht, in dem alle Daten gesammelt und für aggregierte Analysen gespeichert werden, die die Quellen über verschiedene Bereiche hinweg umfassen. Ein Data Lake geht manchmal einem Data Warehouse, einem verfeinerten zentralen Datenspeicher, voraus und speist dieses.
Ein grundlegender Unterschied zwischen einem Data Lake und einem Data Mesh besteht darin, dass ersteres zentralisiert ist, was die Verwaltung massiv und komplex macht - in der Regel sind spezielle Teams erforderlich - und es schwierig macht, es aktuell zu halten.
Datengewebe
A Datenstruktur ist vom Konzept her ähnlich wie ein Datengeflecht, nur dass hier ein technischer Rahmen anstelle eines organisatorischen Rahmens verwendet wird. Ein Datengeflecht nutzt einen zentralen Datenspeicher, isoliert aber den Zugang zu den einzelnen Bereichen und Themengebieten durch strenge Zugangsbeschränkungsprotokolle. Dadurch müssen die Domänen keine eigenen domänenspezifischen Repositories einrichten und sind nicht mehr direkt in die alltägliches Datenmanagement.
Der Hauptunterschied zwischen einem Data Mesh und einer Data Fabric besteht darin, dass ersteres kein verteiltes Modell ist, sondern einen technischen Rahmen darstellt. Im Gegensatz dazu liegt der Schwerpunkt bei letzterem auf organisatorischen Bereichen als Dateneigentümer.
Implementierung einer Datengitterarchitektur
Aufgrund seines dezentralen Modells, eine Plattform zur Verarbeitung und Analyse von Betriebsdaten in Echtzeit ist die optimale Implementierung für die Datengitterarchitektur.
Dieser Blog erklärt, wie Couchbase Capella™ eine Cloud-Datenbank bietet, die sich ideal für Data-Mesh-Implementierungen eignet. Kurz gesagt, Couchbase bietet:
Eine vielseitig einsetzbare NoSQL-Datenbank für die Cloud
Couchbase Capella ist eine entwicklerfreundliche Mehrzweckdatenbank mit integriertem Caching, JSON-Dokumentenspeicher, SQL-Unterstützung, Suche, Eventing und mobiler Synchronisation. Mit diesen kombinierten Funktionen kann ein Unternehmen andere betriebliche Datenbanktechnologien durch eine Lösung ersetzen und das Datengeflecht durch die Reduzierung der betrieblichen Eingaben vereinfachen.
Sofortige betriebliche Einblicke
Capella bietet auch eine integrierte kolumnarer Analysedienst für die Echtzeitanalyse beliebiger Betriebsdaten. Die Ergebnisse können sofortige Einblicke liefern, ohne dass eine Schleife durch das Datennetz gezogen werden muss. Dies beschleunigt das gesamte Netz, da Capella für die sofortige Analyse spezifischer Betriebsdaten verwendet werden kann und diese Ergebnisse dann für eine tiefere Analyse und KI in das Netz eingespeist werden können.
Schnellerer Einblick in das Geschehen
Capella bietet Eventing- und benutzerdefinierte Funktionsmerkmale, die es ermöglichen, Routinen zu skripten, die analytische Erkenntnisse aus dem Netz und zurück in die operativen Schichten erfassen. Dies ermöglicht die Umsetzung von Erkenntnissen - wenn maschinelle Lernalgorithmen in einem Data-Lake-Mesh eine neue Kundenklassifizierung auf der Grundlage historischer Daten entwickeln, können Sie diese Klassifizierung für gezieltes Marketing zurück in die Vertriebsanwendung ziehen.
Beschleunigte Entwicklung
Capella ermöglicht es einer Organisation ihre wuchernden Betriebsdaten in einer Datenbank zu konsolidieren die für Entwickler einfach zu handhaben ist. Die Unterstützung von SQL++ (SQL für JSON), umfangreiche SDKs, Backend-verwaltete Dienste und eine vollständig gehostete DBaaS verringern die Reibungsverluste bei der Entwicklung - es gibt keine Probleme bei der Serverinstallation oder -wartung und die Entwickler müssen keine neuen Sprachen lernen.
Die Zukunft der Datengitterarchitektur
Im Zuge der Digitalisierung in allen Branchen und beschleunigt durch KI-Investitionen und -Entwicklung werden Datenprodukte für die meisten Unternehmen immer wichtiger, und die Einhaltung der Grundsätze des Domäneneigentums und der Kuratierung kann die Grundlage für künftige datengestützte Innovationen bilden.
Versuchen Sie Couchbase Capella und sehen Sie selbst, wie einfach es sich in Ihre Data-Mesh-Architektur-Initiative einfügen kann.
Sie können auch Folgendes sehen unser Zentrum und diese zusätzlichen Ressourcen, um mehr über allgemeine Konzepte im Zusammenhang mit der Datenarchitektur zu erfahren:
Was ist eine Datenplattform?
Beispielarchitekturen für datenintensive Anwendungen
4 Muster für Microservices Architektur in Couchbase

