Uma arquitetura de malha de dados pode ajudar uma organização a habilitar a IA em escala, democratizando o acesso aos dados para análise específica de domínio e atribuindo a especialistas de domínio a responsabilidade por cada área temática. Isso melhora a qualidade dos dados para IA melhor e mais precisa.
Em uma arquitetura de malha de dados, os domínios de negócios possuem e curam seus dados como um produto de dados, garantindo sua qualidade para análise e exercícios de IA, como treinamento de modelos. Isso permite que analistas e cientistas de dados acessem dados de alta qualidade, completamente limpos e bem documentados para algoritmos de IA e aprendizado de máquina, garantindo a precisão e reduzindo fenômenos como alucinações de modo de linguagem grande (LLM).
Vamos examinar esse conceito mais profundamente, explorando a arquitetura de malha de dados.
O que é uma malha de dados?
As empresas, grandes e pequenas, têm vários sistemas que administram os negócios cotidianos. Por exemplo, na maioria das organizações, você pode encontrar um CRM para operações de vendas, um ERP para gerenciamento financeiro, um sistema de helpdesk para suporte ao cliente, um aplicativo de gerenciamento de projetos para desenvolvimento de produtos, etc. É fundamental obter uma visão precisa do desempenho em todas as operações para determinar se os dados de sua empresa são precisos, para aprimorar os processos e simplificar os fluxos de trabalho.
O problema é que somente áreas de negócios específicas conhecem seus dados em profundidade, o que causa problemas com a análise e o controle de qualidade. Isso pode prejudicar os esforços tradicionais de data warehouse que combinam dados de vários domínios em um repositório de dados centralizado, pois a limpeza e a integridade dos dados não podem ser garantidas. E como é cada vez mais evidenteQuanto menos confiáveis forem os dados, menos eficaz e menos precisa será a IA.
Uma arquitetura de malha de dados supera esses desafios ao distribuir dados específicos do domínio para repositórios analíticos individuais e descentralizar a propriedade de cada domínio. Isso garante que os dados de cada domínio sejam completamente examinados e adequados para uso imediato por seus respectivos especialistas. Além disso, unifica fontes diferentes por meio de diretrizes de compartilhamento de dados e padrões de governança gerenciados centralmente.
Com uma arquitetura de malha de dados, as funções de negócios mantêm o controle sobre os dados usados para análise e controlam como seus dados são acessados. Embora uma malha de dados possa aumentar a complexidade do ecossistema de dados de uma empresa, ela também traz eficiência ao melhorar o acesso e a qualidade dos dados, o que alimenta melhor análise e IA.
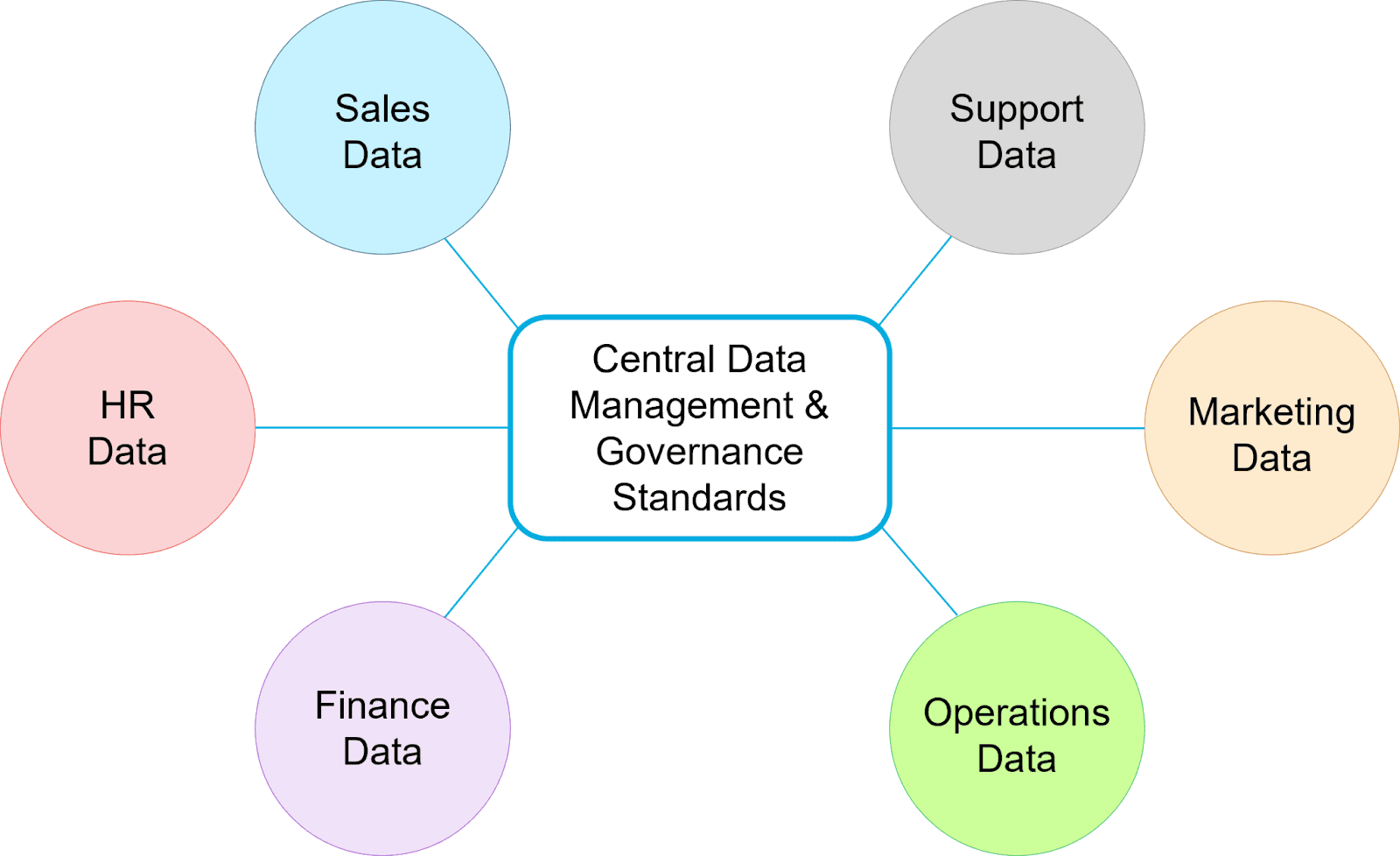
Uma arquitetura de malha de dados distribui dados específicos de domínio sob a propriedade de cada área de negócios.
Por que a malha de dados?
A arquitetura de malha de dados foi formada a partir de uma necessidade de ir além das implementações tradicionais de data warehouse ou data lake centralizados, que tendem a sofrer com alguns desafios fundamentais:
- Estabelecer uma única fonte de verdade pode ser quase impossível com as abordagens tradicionais porque a pegada de dados da maioria das empresas está fragmentada em muitos sistemas diferentes em vários formatos.
- Na era atual da IA, a demanda por acesso mais fácil aos dados de domínio está aumentando, assim como o volume de dados na maioria das empresas. Isso cria desafios no manuseio do armazenamento e do acesso.
- Os cientistas e analistas de dados precisam ter acesso aos dados nos formatos necessários. Os dados devem ser confiáveis e não exigir conhecimento técnico profundo ou intervenção de TI.
A tentativa de resolver esses problemas carregando todos os dados em um sistema de análise centralizado cria seus próprios problemas: Como garantir a qualidade e a atualidade dos dados? Como lidar com dados que mudam rapidamente? Como você lida com novas fontes e formatos de dados?
A arquitetura de malha de dados se esforça para superar esses desafios distribuindo a propriedade dos dados e dos sistemas analíticos para especialistas no domínio. Isso distribui a pegada de dados analíticos para sistemas específicos de domínio menores e mais gerenciáveis, que são mais fáceis de gerenciar individualmente. Como cada especialista de domínio conhece melhor seus dados e tem acesso direto a eles com a malha de dados, a qualidade e a integridade dos dados são aprimoradas, permitindo que eles sejam usados de forma mais confiável e fácil em toda a organização.
Princípios da malha de dados
A arquitetura de malha de dados segue esses princípios gerais:
1. Os dados devem ser de propriedade de seus domínios.
Os domínios de negócios selecionam e gerenciam seus dados para análise e IA, em vez de delegar a propriedade a equipes centralizadas.
2. Os dados devem ser de autoatendimento para usuários autorizados.
Para democratizar o acesso aos dados, as organizações precisam simplificar o acesso por meio da abstração e torná-lo o mais fácil possível sem sacrificar a segurança rigorosa.
3. A governança de dados deve ser distribuída.
As políticas de gerenciamento, armazenamento e segurança de dados são gerenciadas centralmente, mas cada domínio é proprietário de seus produtos de dados, garantindo flexibilidade e estrutura repetível.
4. Os dados devem ser tratados como um produto (DaaP).
A adesão aos princípios acima garante produtos de dados examinados, de alta qualidade e totalmente limpos que os consumidores autorizados podem acessar e usar facilmente. Em uma arquitetura de malha de dados, os domínios são proprietários de seus produtos de dados, provenientes de fontes analíticas e sistemas operacionaisE, seguindo as diretrizes de gerenciamento padronizadas, eles tornam esses dados mais precisos e acessíveis em toda a organização.
Casos de uso de malha de dados
Uma arquitetura de malha de dados pode suportar muitos casos de uso diferentes em uma ampla variedade de setores e verticais. Alguns exemplos são:
Ciclo de vida do cliente
Por meio do acesso a dados de sistemas que abrangem o envolvimento do cliente, as organizações obtêm uma visão de 360 graus das jornadas do cliente, individualmente e em conjunto, em tempo real. Isso permite que a empresa crie uma IA que envolva os clientes mais rapidamente com ofertas e sugestões relevantes e examine os motivos dos sucessos ou fracassos no envolvimento geral.
IA e aprendizado de máquina
Cientistas de dados e analistas avançados podem acessar facilmente várias fontes para alimentar modelos de IA e aprendizado de máquina, confiantes de que os dados são limpos, atuais e precisos.
Monitoramento do ambiente de IoT
A arquitetura distribuída em uma malha de dados permite que as implementações de dispositivos de IoT sejam gerenciadas e monitoradas com mais eficiência pelas unidades de negócios individuais responsáveis pelos aplicativos de IoT.
Política de segurança de dados distribuídos
A segurança dos dados é fundamental em um modelo distribuído como a malha de dados. Ao dividir a responsabilidade pelas políticas de segurança de produtos de dados entre domínios individuais, o acesso aos dados é restringido de forma mais adequada com base na experiência do domínio. Embora mais detalhada em geral, ela também é mais rigorosa do que uma política de segurança centralizada e de tamanho único em sua granularidade.
Benefícios da malha de dados
Há muitos benefícios de uma arquitetura de malha de dados, entre os quais alguns dos mais importantes são:
Agilidade de dados
A arquitetura de malha de dados reduz as dependências dos recursos de TI para fornecer acesso aos dados de vários sistemas, permitindo que as equipes de negócios se concentrem na qualidade e forneçam produtos de dados mais rapidamente.
Dados de alta qualidade para IA
Como os especialistas em domínios individuais gerenciam os dados, sua compreensão mais profunda do contexto e do significado resulta em dados mais confiáveis e com melhor curadoria, o que é fundamental para reduzir resultados imprecisos e LLM Alucinações.
Disponibilidade de dados mais rápida
Um dos principais gargalos da abordagem de lago de dados centralizado é o tempo necessário para adicionar e atualizar fontes, sem falar em gerenciá-las e torná-las facilmente disponíveis. Com uma arquitetura de malha de dados, o fornecimento de produtos de dados ocorre em paralelo, e não em sequência, e, portanto, é mais rápido.
Políticas de governança de dados centrais padrão
Devido ao seu princípio fundamental de seguir um conjunto centralizado de diretrizes rígidas de governança, a arquitetura de malha de dados define um padrão para a custódia de dados em toda a organização e, ao mesmo tempo, proporciona autonomia a cada domínio.
Esses são apenas alguns dos motivos pelos quais muitas organizações adotam uma arquitetura de malha de dados.
A diferença entre dash mesh, data lake e data fabric
Ao avaliar as necessidades de dados e IA da sua organização, você inevitavelmente ouvirá falar de abordagens e arquiteturas alternativas, como um data lake ou um data fabric. Aqui estão as diferenças em poucas palavras:
Lago de dados
A lago de dados é um termo que se refere a um repositório centralizado de dados de várias fontes e sistemas, onde todos os dados são coletados e armazenados para análise agregada que abrange as fontes em vários domínios. Um data lake às vezes precede e alimenta um data warehouse, um repositório de dados centralizado mais refinado.
Uma diferença fundamental entre um lago de dados e uma malha de dados é que o primeiro é centralizado, o que o torna massivo e complexo de gerenciar - normalmente exigindo equipes dedicadas - e difícil de manter atualizado.
Tecido de dados
A tecido de dados é semelhante em conceito a uma malha de dados, exceto pelo fato de empregar uma estrutura técnica em vez de uma estrutura organizacional. Uma malha de dados utiliza um repositório de dados centralizado, mas isola o acesso a cada domínio e área temática por meio de protocolos rígidos de restrição de acesso. Isso alivia a necessidade de os domínios estabelecerem seus próprios repositórios específicos e elimina seu envolvimento direto com o repositório de dados. gerenciamento diário de dados.
A principal diferença entre uma malha de dados e um tecido de dados é que o primeiro não é um modelo distribuído, mas uma estrutura técnica. Por outro lado, o segundo concentra-se em domínios organizacionais como proprietários de dados.
Implementação de uma arquitetura de malha de dados
Devido ao seu modelo descentralizado, uma plataforma de análise e processamento de dados operacionais em tempo real é a implementação ideal para a arquitetura de malha de dados.
Este blog explica como o Couchbase Capella™ fornece um banco de dados em nuvem ideal para implementações de malha de dados. Em poucas palavras, o Couchbase fornece:
Um banco de dados NoSQL multiuso na nuvem
O Couchbase Capella é um banco de dados multiuso e amigável ao desenvolvedor com cache integrado, armazenamento de documentos JSON, suporte a SQL, pesquisa, eventos e sincronização móvel. Com esses recursos combinados, uma organização pode substituir outras tecnologias de banco de dados operacionais por uma única solução, simplificando a malha de dados ao reduzir as entradas operacionais.
Insights operacionais instantâneos
O Capella também oferece um serviço de análise colunar para análise em tempo real de qualquer dado operacional. Os resultados podem fornecer insights no fio sem passar pela malha de dados. Isso acelera a malha geral, pois o Capella pode ser usado para análise instantânea de dados operacionais específicos e, em seguida, alimentar esses resultados na malha para uma análise mais profunda e IA.
Insight-to-action mais rápido
O Capella oferece recursos de eventos e funções definidas pelo usuário, permitindo a capacidade de criar rotinas que capturam insights analíticos da malha e retornam às camadas operacionais. Isso permite efetivamente a ação sobre os insights - se os algoritmos de aprendizado de máquina em uma malha de data lake desenvolverem uma nova classificação de clientes com base em dados históricos, você poderá puxar essa classificação de volta para o aplicativo de vendas para marketing direcionado.
Desenvolvimento acelerado
O Capella permite que uma organização consolidar a dispersão de dados operacionais em um banco de dados que é fácil para os desenvolvedores trabalharem. O suporte ao SQL++ (SQL para JSON), os SDKs avançados, os serviços gerenciados de back-end e um DBaaS totalmente hospedado reduzem o atrito no desenvolvimento - não há dores de cabeça com instalação ou manutenção de servidores e não há novas linguagens para os desenvolvedores aprenderem.
Futuro da arquitetura de malha de dados
Conforme impulsionados pela digitalização em todos os setores e acelerados por investimentos e desenvolvimento de IA, os produtos de dados se tornarão cada vez mais importantes para a maioria das empresas, e a adesão a seus princípios de propriedade e curadoria de domínio pode estabelecer a base para futuras inovações impulsionadas por dados.
Tente Couchbase Capella e veja como ele pode se encaixar facilmente em sua iniciativa de arquitetura de malha de dados.
Você também pode visualizar nosso centro e estes recursos adicionais para saber mais sobre conceitos gerais relacionados à arquitetura de dados:
O que é uma plataforma de dados?
Exemplos de arquiteturas para aplicativos com uso intensivo de dados
4 padrões para arquitetura de microsserviços no Couchbase
Iniciar a construção
Confira nosso portal do desenvolvedor para explorar o NoSQL, procurar recursos e começar a usar os tutoriais.
Experimente Capella gratuitamente
Comece a trabalhar com o Couchbase em apenas alguns cliques. O Capella DBaaS é a maneira mais fácil e rápida de começar.
Couchbase para ISVs
Crie aplicativos avançados com menos complexidade e custo.