다음과 같은 소식을 알려드리게 되어 기쁩니다. 카우치베이스 클라우드 1.6 릴리스 발표 에는 특히 데이터 가져오기에서 여러 가지 주요 개선 사항이 포함되어 있습니다.
이러한 기능 개선 사항에는 다음을 사용하여 문서 가져오기가 포함됩니다. 카우치베이스 클라우드 다양한 키 생성 및 구성 옵션을 갖춘 웹 UI. 일반적으로 100MB 미만의 작은 데이터 세트를 다양한 형식으로 빠르게 가져올 수 있는 간편한 방법을 제공합니다. 이것은 익숙한 cbimport 도구로컬 S3 스토리지와 같은 클라우드 네이티브 기술을 더욱 활용합니다.
새로운 가져오기 기능은 백업/복원 및 XDCR에 더해 온프레미스에서 클라우드로의 데이터 마이그레이션 전략의 일부입니다.
이 블로그 게시물에서는 Couchbase Cloud로 가져오기 중 몇 가지 사용 사례와 몇 가지 "문제"를 살펴보겠습니다. 모든 기능을 자세히 살펴보기 위한 것은 아닙니다; 이에 대한 자세한 내용은 카우치베이스 클라우드에 대한 훌륭한 문서를 참조하세요..
기능 개요
Couchbase Cloud 1.6의 기능 목록을 간단히 살펴보겠습니다:
| 기능 | 운영 |
|---|---|
| 사용자 지정 키 생성 표현식 - cbimport 도구와 동일한 친숙한 형식 - 또는 자동 생성된 UUID를 선택합니다. 생성된 키 확인 - 샘플 JSON 문서를 UI에 붙여넣고 생성된 키를 시각적으로 살펴보세요. 구성 옵션 - 문서 건너뛰기 - 문서 제한 - 가져오기 문서의 필드 무시 - 추가 CSV - 필드 유형 유추 - 추가 CSV - 빈 유형 생략 |
비동기 및 동시 가져오기 - 백그라운드에서 데이터를 가져오는 동안 다른 활동을 계속 진행하세요. 이메일 알림 - 가져오기가 완료되면 이메일로 알림을 받습니다. 여러 가지 방법으로 파일 업로드 - 웹 브라우저를 통해 - cURL을 통해 S3로 직접 연결 가져온 파일의 로컬 저장소 - 다시 로드하지 않고 다시 가져오기 활동 내역 가져오기 - 가져오기 활동 감사 가져오기 로그 보존 - 간편한 문제 해결 |
예제 데이터 세트
몇 가지 기능을 설명하기 위해 아주 작고(단 3개), 아주 인위적인 문서를 사용하겠습니다. 가져오기를 사용하면 다양한 파일 형식의 데이터를 가져올 수 있으므로 이러한 파일 형식이 무엇인지 간단히 다시 한 번 살펴보겠습니다:
-
- JSON 목록
- JSON 목록은 쉼표로 구분된 JSON 객체(중괄호로 표시)를 원하는 수만큼 나열한 목록(대괄호로 표시)입니다.
- JSON 라인
- JSON 줄은 각 줄마다 해당 줄에 별도의 완전한 JSON 객체가 있는 파일입니다.
- CSV(쉼표로 구분된 변수)
- CSV 형식은 JSON 데이터를 '플랫화'하며 배열이나 중첩된 값을 지원하지 않습니다.
- 아카이브
- 개별 JSON 문서의 압축 파일
- JSON 목록
이제 세 가지 문서 자체를 살펴보겠습니다:
아이디를 가진 사람 101 |
아이디를 가진 사람 102 |
아이디가 없는 사람 |
| { "id": 101, "short.name": "JS", "%SS%": "091-55-1234", "name":{ "first": "John", "full.name": "존 P 스미스", "last": "Smith" }, "연락처": { "@메일": "john.smith@gmail.com“, "Office": { "cell#": "1-555-408-1234" } } } |
{ "id": 102, "short.name": "JS", "%SS%": "091-55-1234", "name":{ "first": "제인", "full.name": "제인 P 스미스", "last": "Smith" }, "연락처": { "@메일": "jane.smith@gmail.com“, "Office": { "cell#": "1-555-408-2345" } } } |
{ "short.name": "AS", "%SS%": "091-55-0000", "name":{ "first": "아담", "full.name": "아담 스미스", "last": "Smith" } } |
people.json 파일
위의 세 가지 문서로 파일을 만듭니다.
|
1 2 3 4 5 |
[ {"%SS%":"091-55-2345","contact":{"@email":"jane.smith@gmail.com","Office":{"cell#":"1-555-408-2345"}},"id":102,"name":{"first":"Jane","full.name":"Jane P Smith","last":"Smith"},"short.name":"JS"}, {"%SS%":"091-55-1234","contact":{"@email":"john.smith@gmail.com","Office":{"cell#":"1-555-408-1234"}},"id":101,"name":{"first":"John","full.name":"John P Smith","last":"Smith"},"short.name":"JS"}, {"%SS%":"091-55-0000","name":{"first":"Adam","full.name":"아담 스미스","last":"Smith"},"short.name":"AS"} ] |
데이터 가져오기 프로세스
이제 데이터 파일이 준비되었으므로 가져오기 프로세스를 시작하겠습니다. 이 작업을 시작하기 전에 100MB 크기의 버킷 테스트를 만들었습니다. 이 작은 데이터 집합을 가져오기에는 이 정도면 충분합니다. 몇 가지 주의할 점이 있습니다:
-
- 다음이 필요합니다. 관리자 권한이 있습니다.
- 버킷이 존재해야 합니다.
- 버킷 크기는 가져온 데이터 집합을 저장하기에 충분한 크기여야 합니다.
- 이 경우 데이터베이스 사용자.
- 다음을 수행할 필요가 없습니다. 화이트리스트 귀하의 IP.
파일 업로드
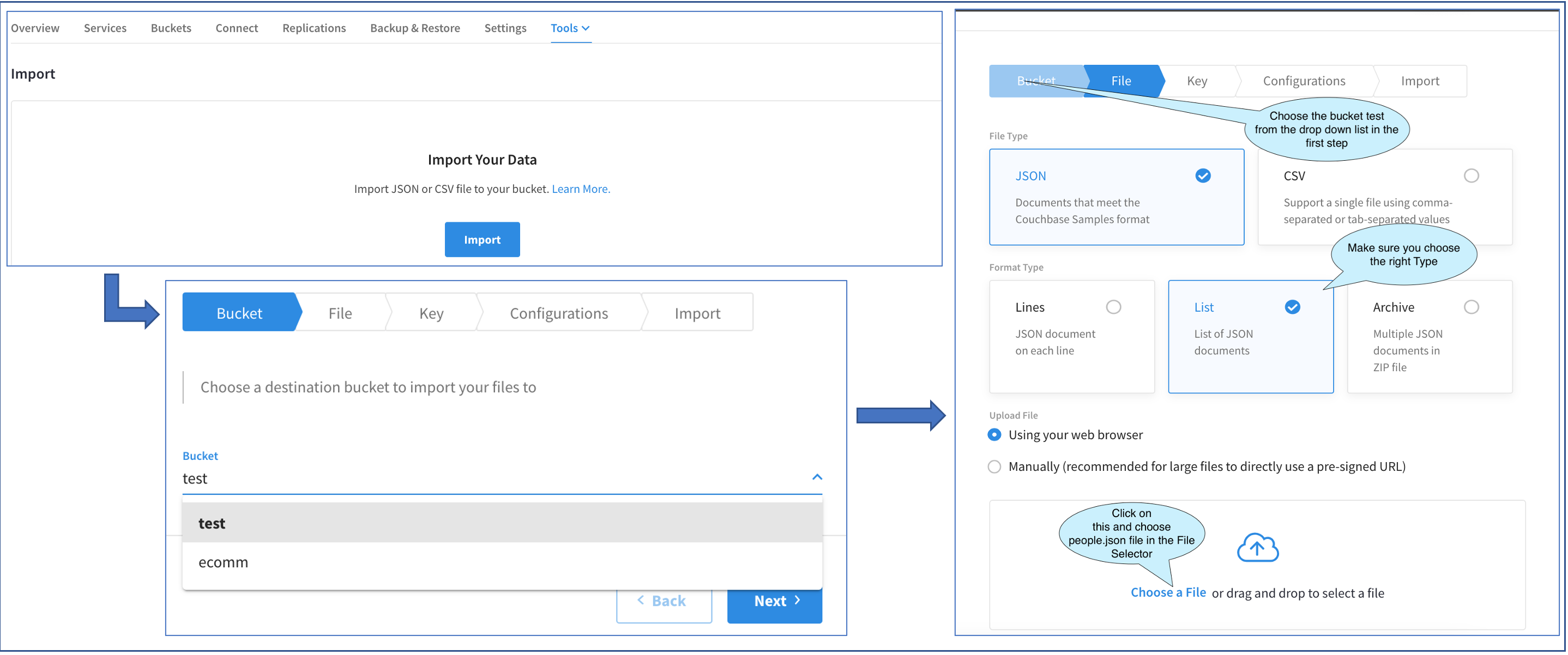
위의 다이어그램은 세 가지 화면의 진행 과정을 보여줍니다. 다음을 통해 첫 번째 가져오기 메인 UI에 액세스합니다. 클러스터 > 도구 > 가져오기.
가져오기를 처음 수행하기 때문에 기본 가져오기 UI에는 가져오기 버튼을 클릭합니다. 이를 클릭하면 플라이아웃 가져오기. 나머지 작업은 이 플라이아웃에서 수행됩니다.
플라이아웃의 첫 번째 화면에서 버킷을 선택할 수 있습니다. 버킷이 두 개 있습니다. 버킷을 선택하겠습니다. 테스트 버킷.
다음 화면에서 파일 유형을 선택하라는 메시지가 표시됩니다. 샘플 파일은 JSON 파일이며 파일 유형은 목록. 이를 선택한 후에는 파일을 업로드할 수 있는 몇 가지 옵션이 있습니다. 브라우저를 통해 업로드하거나 다음과 같이 업로드할 수 있습니다. 수동으로 URL을 통해 접속합니다.
일반적으로 100MB 미만의 파일은 브라우저를 통해 업로드할 수 있습니다. 이제 해당 옵션을 선택해 보겠습니다. 를 클릭하고 파일 선택 는 파일 선택기 (여기에는 표시되지 않음). 이것이 표준 파일 선택기입니다. 계속해서 다음을 선택해 보겠습니다. people.json.
파일이 100MB보다 큰 경우 URL을 통해 수동으로 로드하는 방법을 선택했을 것입니다. 해당 옵션을 클릭하면 텍스트 상자에 cURL 명령을 복사하여 노트북의 터미널 창에서 실행했을 것입니다.
파일 업로드 방식에 관계없이 나머지 프로세스는 동일합니다.
키 생성
파일을 선택했으면 키 생성 섹션으로 넘어가겠습니다. 지금은 파일이 아직 실제로 업로드되지 않은 상태입니다. 이는 몇 단계 더 진행하면 됩니다.
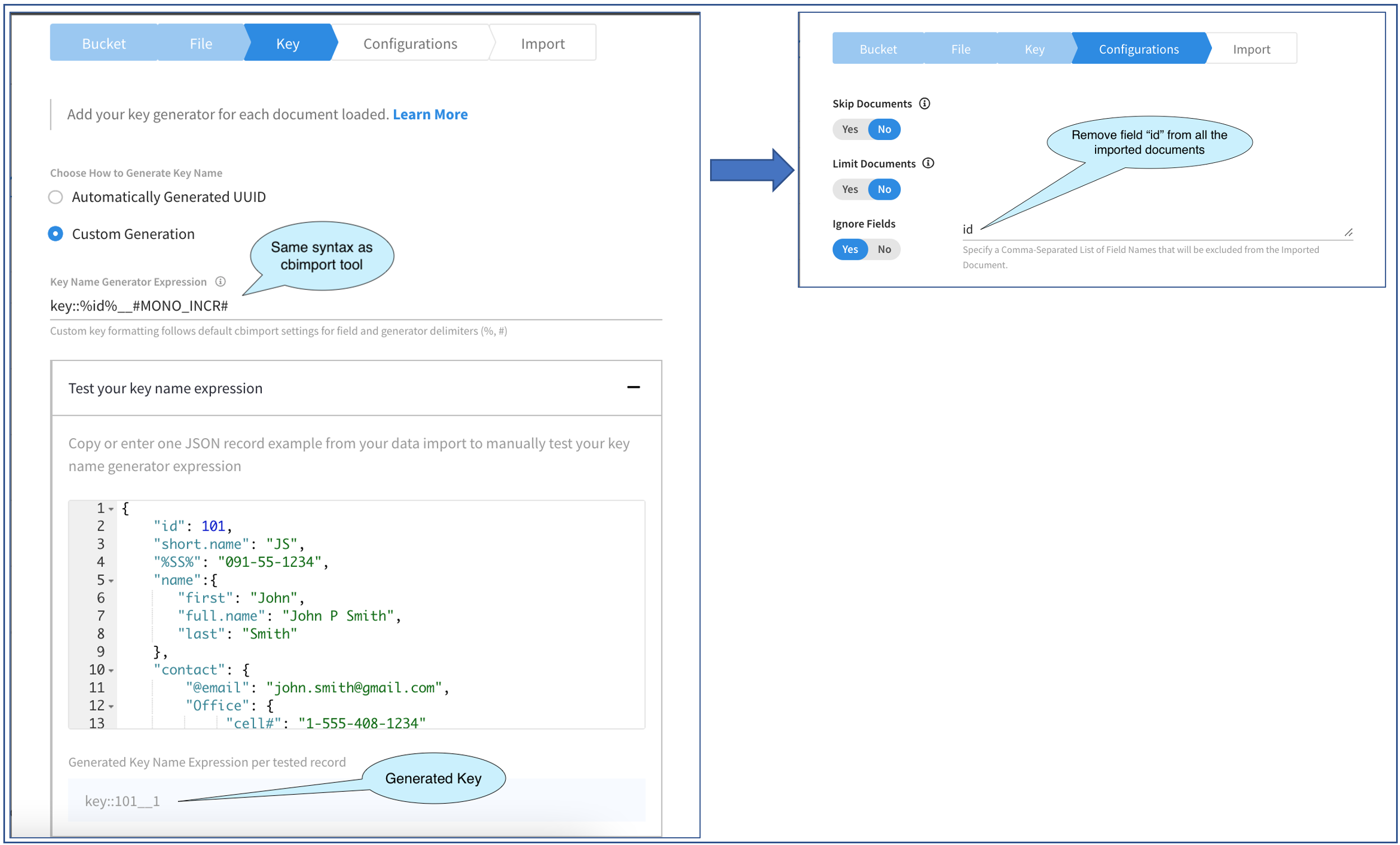
위 그림은 가져오기 플라이아웃의 두 화면을 통한 진행 상황을 보여줍니다.
첫 번째 화면에서는 문서 키를 생성하는 방법을 지정할 수 있습니다. 여기에는 몇 가지 선택 사항이 제공됩니다: 다음 중 하나를 선택합니다. 자동 생성 키를 사용하거나 표현식 에서 제공합니다. 첫 번째 옵션은 간단하며 문서 키가 중요하지 않은 소규모 테스트 케이스에 사용할 수 있습니다. 이제 두 번째 옵션을 선택하여 특정 패턴으로 문서 키를 생성해 보겠습니다.
키 이름 생성기 표현식에서 표현식을 지정해야 합니다. 이것은 문자열이며 다음과 같습니다. 키 생성기의 구문과 동일한 구문입니다.. 생성된 키는 다음과 같습니다. 정적 텍스트 또는 필드 값 문서에서 생성기 기능 같은 MONO_INCR 또는 이 세 가지를 조합한 UUID를 입력합니다.
표현식을 작성할 때 주의해야 할 몇 가지 사항이 있습니다:
-
- 필드 이름은 항상 "%"로 묶습니다.
- 생성기 기능은 항상 "#"로 묶여 있습니다.
- "%" 또는 "#"로 래핑되지 않은 텍스트는 정적 텍스트이며 생성된 모든 키의 결과에 포함됩니다.
- 정적 텍스트에 "%" 또는 "#"가 포함되어야 하는 키는 이중 "%" 또는 "#"를 제공하여 이스케이프 처리해야 합니다(예: "%%" 또는 "##").
- 키 생성기에 지정된 필드가 문서에 없기 때문에 키를 생성할 수 없는 경우 해당 키는 건너뜁니다.
이 예제에서 선택한 표현식은 다음과 같습니다: key::%id%__#MONO_INCR#. 이는 곧:
-
- %id%를 문서에서 'id' 필드의 값으로 바꿉니다.
- #MONO_INCR#를 1로 시작하는 단조롭게 증가하는 숫자로 바꿉니다.
- 나머지는 키의 정적 텍스트로 처리합니다.
이 화면에서는 표현식 구문과 표현식에 의해 생성된 실제 키를 확인할 수 있는 멋진 방법도 제공합니다.
이를 위해 샘플 문서를 샘플 문서에 붙여넣어야 합니다. JSON 편집기. 보시다시피 그렇게 했습니다. 파일에 있는 세 문서 중 처음 두 문서에만 id 필드가 있는 문서를 선택하는 데 신중을 기했습니다. 물론 이 유효성 검사기는 CSV 문서가 아닌 JSON 문서에서만 작동합니다. 마지막으로, 위 그림에서 볼 수 있듯이 JSON 문서를 '예쁘게' 만들었습니다. 이것은 편의를 위한 것입니다. 문서를 한 줄로 붙여넣었어도 작동했을 것입니다. 표현식을 입력하면 생성됨 키가 하단에 표시됩니다. 매우 인터랙티브하며 표현식을 가지고 놀면서 생성된 키를 즉시 확인할 수 있습니다.
만족하면 다음 단계로 넘어갈 수 있습니다. 구성 옵션을 선택하면 바로 이 작업을 수행합니다. 이 화면에는 세 가지 옵션이 있으며 이 중 마지막 옵션에 관심이 있습니다, 필드 무시. 이 옵션을 사용하면 파일에 있는 모든 문서를 가져오되 문서에 지정된 필드는 가져오지 않을 수 있습니다. 이 옵션을 사용하면 쉼표로 구분하여 여러 필드를 지정할 수 있습니다.
여기 예제에서는 다음과 같은 값을 만들었으므로 id 의 일부가 문서 키에 포함되어 있으므로 문서에도 동일한 정보가 필요하지 않으므로 제거해 보겠습니다. 이를 위해 문자열을 다음과 같이 입력했습니다. id. 이것은 일반 텍스트이므로 필드 이름을 "%" 안에 묶어서는 안 된다는 점에 유의하세요.
키 생성 예시
| 키 생성 표현식 | 생성된 키 |
|---|---|
| key::%id%::#MONO_INCR# | key::102::1 |
| key::%id%::#UUID# | key::102::29ee002c-06e4-4dbf-bb5b-b2f148167536 |
| key::%id%::###UUID# | key::101::#3c671afe-fb02-48aa-a027-d74a8d38bcbc |
key::%short.name%_%%%SS%%% |
key::AS_091-55-0000 |
키::%이름.full.name% |
key::아담 스미스 |
| key::%contact.@email% | key::jane.smith@gmail.com |
| key::%%%contact.@email% | key::%jane.smith@gmail.com |
| contact##::%contact.@email% | contact#::jane.smith@gmail.com |
| Tel##:%contact.Office.cell#% | Tel#:1-555-408-1234 |
가져오기 확인 및 실행
이제 키가 만족스럽게 생성되었고 데이터 가져오기가 다음을 무시하도록 구성되었으므로 id 필드에 입력한 후 다음 단계인 가져오기 확인 및 실행을 진행합니다.
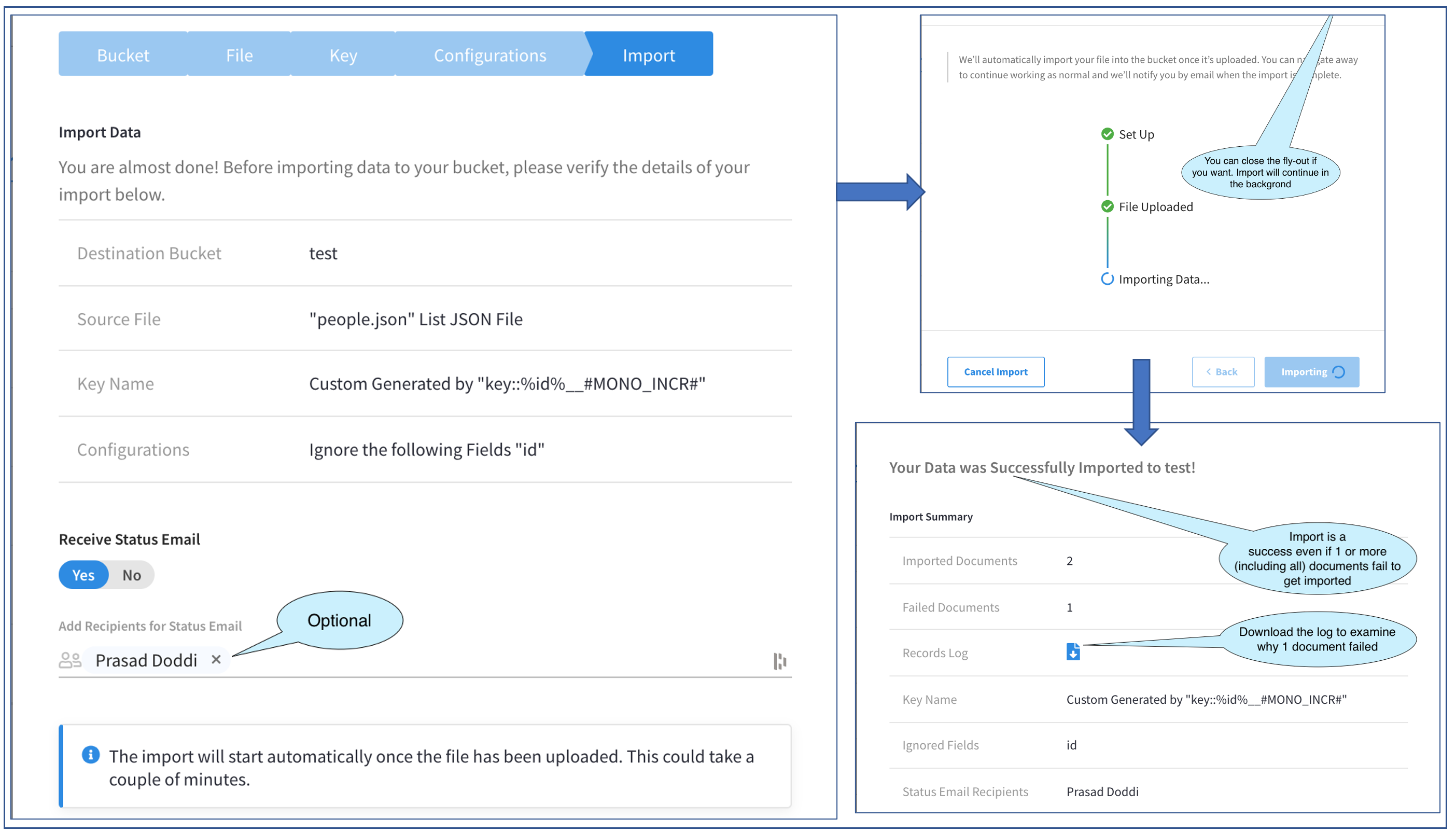
위 그림은 플라이아웃의 세 화면을 통한 진행 상황을 보여줍니다.
첫 번째 화면부터 시작하겠습니다. 이 화면에서는 수행하려는 작업을 확인하고 놓친 부분이 있는 경우 다시 돌아갈 수 있습니다. 또한 가져오기가 완료된 후 확인 이메일을 받을 사용자 목록을 지정할 수 있습니다. 다른 작업으로 넘어가는 동안 백그라운드에서 실행할 수 있는 대용량 가져오기 파일에 매우 편리합니다. 물론 이것은 선택 사항입니다. 저는 확인 이메일을 받도록 저를 추가하기로 선택했습니다. 선택기에 표시되는 사용자 목록은 다음과 같습니다. 수신자 추가 는 프로젝트의 일부인 관리자입니다.
다음 화면에서 실제 가져오기가 시작됩니다. 가져오기는 배경 플라이아웃이 열려 있을 필요가 없습니다. 플라이아웃을 닫을 수 있습니다. X 를 클릭합니다(사진에는 보이지 않음). 또한 다음과 같은 옵션이 제공됩니다. 취소 가져오기를 클릭합니다. 이 예제에서는 완료될 때까지 열어 두겠습니다.
완료되면 위 그림의 세 번째 화면이 표시됩니다. 메인 가져오기 페이지에서도 이 화면으로 이동할 수 있으며, 이에 대해서는 나중에 다시 살펴보겠습니다.
세 번째 화면에는 가져오기 결과. 이 시점에서 확인 이메일도 받게 됩니다. 여기 예제에서는 이 화면에서 문서 두 개를 성공적으로 가져왔고 한 개는 실패했음을 알려줍니다. 전체 상태는 가져오기 성공입니다.
여기서 주의해야 할 중요한 점은 가져오기의 전반적인 성공 여부가 문서의 전체, 일부 또는 일부 데이터 가져오기의 성공 여부에 달려 있지 않다는 것입니다. 가져오기 프로세스의 성공 여부는 프로세스가 충돌 없이 완료되었다는 것입니다.
다시 예시로 돌아와서 한 문서에서 발생한 이 오류에 대해 좀 더 자세히 살펴봅시다. To 문제 해결 이 실패하면 다음과 같은 유용한 버튼이 제공됩니다. 다운로드 의 레코드 로그 그리고 이것이 우리가 할 일입니다.
레코드 로그 관련 문제 해결
제가 다운로드한 레코드 로그입니다. (몇 줄을 잘라냈습니다.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
사용자 지정 생성기 키: 키::%id%__#MONO_INCR# 사용자 args: --verbose --무시-필드 id ======================= 2021-06-03T01:50:07.322+00:00 (휴식) GET http://cb:8091/pools/default 200 2021-06-03T01:50:07.322+00:00 (계획) 실행 중 전송 계획 ... 2021-06-03T01:50:07.330+00:00 (휴식) GET http://cb:8091/pools/default/버킷 200 2021-06-03T01:50:07.331+00:00 (휴식) GET http://cb:8091/pools/default/nodeServices 200 2021-06-03T01:50:07.356+00:00 오류: 키 세대 에 대한 문서 실패, 필드 id does not 존재 -- jsondata.(*병렬 처리기).... 2021-06-03T01:50:07.376+00:00 오류: 데이터 전송 실패: 일부 오류 발생 동안 전송 데이터, ... 2021-06-03T01:50:07.376+00:00 (계획) 전송 계획 실패 만기 에 오류 일부 오류 발생 동안 전송 데이터, ... 2021-06-03T01:50:07.376+00:00 JSON 가져오기 실패: 2 문서 는 가져온, 1 문서 실패 에 be 가져온 2021-06-03T01:50:07.376+00:00 JSON 가져오기 실패: 일부 오류 발생 동안 전송 데이터, 참조 로그 에 대한 더 보기 세부 정보 JSON 가져오기 실패: 2 문서 는 가져온, 1 문서 실패 에 be 가져온 JSON 가져오기 실패: 일부 오류 발생 동안 전송 데이터, 참조 로그 에 대한 더 보기 세부 정보 |
오류 줄은 다음과 같습니다: 오류: 문서에 대한 키 생성에 실패했습니다. 필드 ID가 존재하지 않습니다.. 일부 문서에 'id' 필드가 존재하지 않는다는 오류 메시지가 표시됩니다. 물론 이것은 맞으며 이 문서를 가져오지 못한 이유입니다.
가져온 문서 확인
가져오기가 완료되었고 약간의 문제 해결도 수행했으니 이제 실제 가져온 문서를 확인해 보겠습니다.
올바른 키 형식을 가진 두 개의 문서가 있어야 하며 문서에 다음과 같은 형식이 없어야 합니다. id 필드를 무시하도록 가져오기를 구성했기 때문입니다. 확인하려면 도구 > 문서 뷰어.
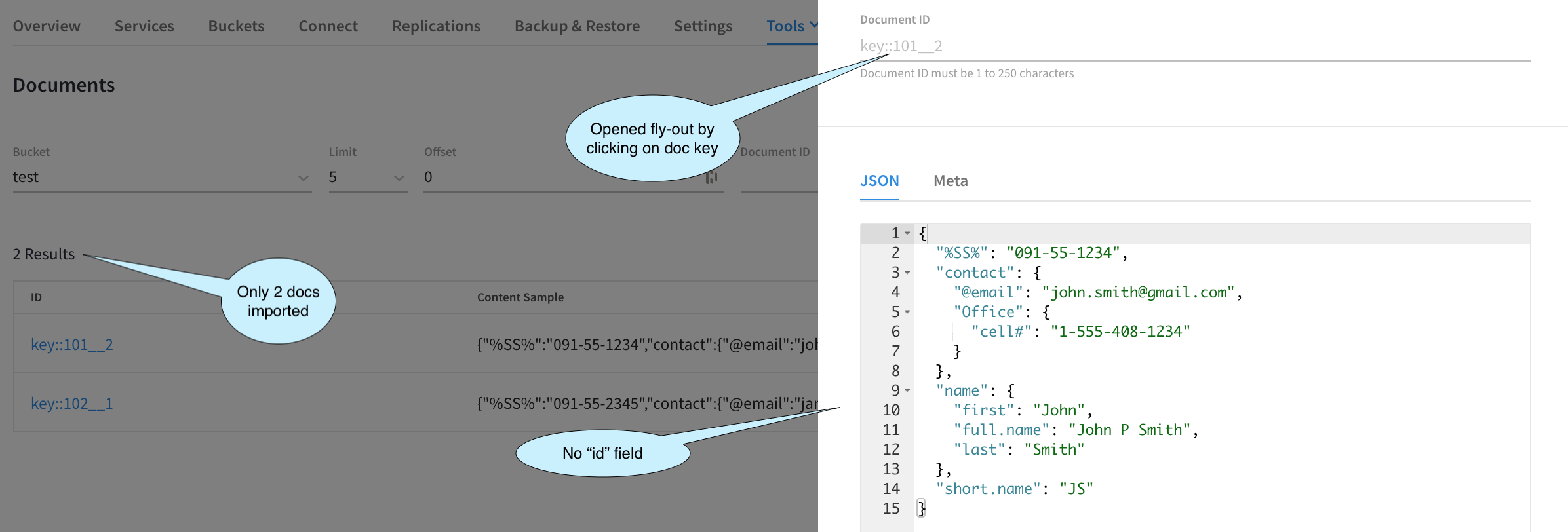
위의 이미지에서 원하는 결과를 얻었음을 확인할 수 있습니다.
메인 화면 가져오기: 활동 목록
가져오기 플라이아웃이 닫히면 메인 화면으로 돌아옵니다. 이제 모든 데이터 가져오기 활동 목록이 표시됩니다. 아래 예제에서는 활동 UI를 설명하기 위해 여러 가져오기를 수행하고 하나를 취소했습니다.
가져오기 플라이아웃을 닫았다면( X), 그 다음 상태 로 표시될 것입니다. 진행 중.
이 화면은 감사 로그의 역할을 할 뿐만 아니라 다른 활동도 수행할 수 있습니다.
여기서 아무 줄이나 클릭하면 가져오기 결과 플라이아웃. 를 클릭하면 점 3개 버튼 를 클릭하면 로그 파일 등을 다운로드할 수 있는 메뉴가 나타납니다.
더 흥미로운 메뉴 항목 중 하나는 다시 가져오기. 이제 업로드한 파일이 클라우드 스토리지(예: AWS의 경우 S3)에 있으므로 노트북에서 파일을 업로드하는 초기 단계를 거치지 않고 동일한 파일을 가져올 수 있습니다. 이 버튼을 클릭하면 가져오기 단계가 다시 한 번 진행되지만 이번에는 가져온 파일을 다시 사용할 수 있고 파일 유형, 키 표현식 등 이전에 선택했던 모든 항목을 그대로 유지할 수 있습니다. 물론 언제든지 변경할 수 있습니다. 프로세스는 거의 동일하므로 이 데모에서는 이 과정을 다시 거치지 않겠습니다.
모범 사례 및 "잡았다!"
다음은 프로젝트에 고려해야 할 몇 가지 모범 사례와 피해야 할 몇 가지 일반적인 "잡았다!"입니다:
-
- 가져오기 중 파일 유형 확인
- 혼동하지 마세요
라인그리고목록JSON 파일을 입력합니다. - 가져오기가 성공한 것으로 표시될 수 있지만 문서가 없거나 문서 하나(마지막 문서)만 가져올 수 있습니다.
- 혼동하지 마세요
- 사용자 지정 키 생성 표현식을 사용할 때는 가능하면 생성된 키를 확인하세요.
- 필드 구분 기호 %에 특히 주의하세요.
- 예를 들어 사용자 지정 키를 놓쳐서
key::id대신key::%id%데이터 가져오기 프로세스가 끝나면 키가 다음과 같은 문서 하나만 표시됩니다.key::id
- 버킷의 크기가 가져온 문서를 담을 수 있는 크기인지 확인하세요.
- 3노드 클러스터가 있고 버킷 크기로 100MB를 지정하고 자동 생성된 UUID와 같이 긴 키 이름이 포함된 2GB 파일을 가져오기로 결정하면 버킷이 메타데이터로 빠르게 채워집니다.
- 모든 카우치베이스 클라우드 버킷은 모두 밸류 이젝션 전용이라는 점을 기억하세요.
- 일반적으로 100MB를 초과하는 대용량 파일을 가져오려면 cURL을 사용합니다.
- 이를 통해 업로드할 때마다 cURL이 달라질 수 있으므로 이전 cURL 명령을 재사용하지 마세요.
- 가져오기 중 파일 유형 확인
결론
지금까지 Couchbase Cloud로 데이터를 가져오는 동안 몇 가지 사용 사례와 몇 가지 "문제"에 대해 자세히 살펴보았습니다. 이 문서에서 새로운 퍼블릭 API 등을 포함한 Couchbase Cloud 1.6의 다른 새로운 기능에 대해 자세히 알아보세요..
아직 카우치베이스 클라우드 무료 체험판 지금 바로 사용해 보세요!