概要
知識グラフは、エンティティ(ノード)、関係(エッジ)、属性(プロパティ)、オントロジー(スキーマ)、推論メカニズムに依存し、機械が情報を理解し表現できるようにする。ナレッジグラフは、データを収集・処理し、エンティティや関係を抽出し、この情報をグラフ形式で構造化し、推論やクエリによる洞察を可能にする。ナレッジグラフは、電子商取引、金融、ヘルスケア、サイバーセキュリティ業界において、検索機能の強化、不正行為の検出、レコメンデーションのパーソナライズ、意思決定の改善などに広く利用されている。
ナレッジグラフとは何か?
知識グラフとは、エンティティ、概念、およびそれらの間の関係を、機械が理解し利用できる方法で結びつけた情報の構造化表現である。人、場所、物などの実体を表すノードと、それらの関係を表すエッジにデータを整理する。これにより、相互接続された情報のセマンティック・ネットワークが構築される。
ナレッジグラフは、検索エンジン、推薦システム、人工知能(AI)アプリケーションで使用され、データ検索を強化し、文脈理解を向上させ、より正確な洞察を提供する。構造化されたデータを活用し、既存の情報とリンクさせることで、ナレッジグラフは機械が人間と同じように知識を処理し、推論するのを助ける。
ナレッジグラフがどのように機能するのか、どのように構築するのか、この資料を読み進めてください。
- ナレッジグラフの主な要素
- ナレッジグラフはどのように機能するのか?
- オントロジーと知識グラフ
- ナレッジグラフの例
- ナレッジグラフの使用例
- ナレッジグラフの利点
- ナレッジグラフの作り方
- 主な要点とその他のリソース
- よくあるご質問
ナレッジグラフの主な要素
ナレッジグラフがどのように機能するかを説明する前に、ナレッジグラフを機能させる要素を説明することが重要です。これらのメカニズムは、ナレッジグラフの基礎を形成し、実世界のエンティティ、その属性、およびそれらの関係を表現することを可能にします。ナレッジグラフを基本的な構成要素に分解することで、それがどのようにデータを整理し、どのような関係を促進するのかをよりよく理解することができます。 セマンティックサーチナレッジグラフは、情報を構造化し分析する強力なツールである。以下は、ナレッジグラフを情報の構造化と分析のための強力なツールとする基本的な要素である。
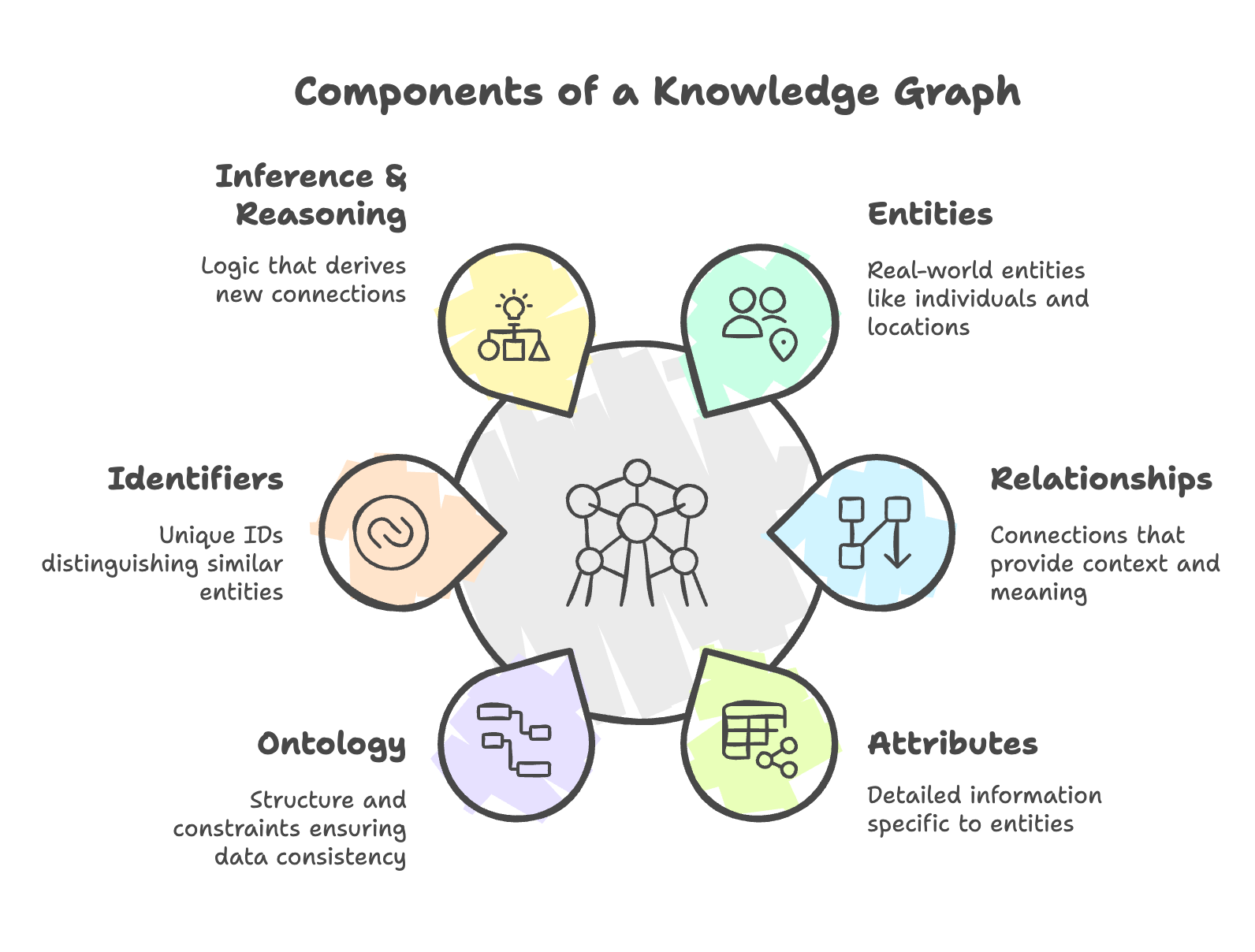
エンティティ(ノード)
エンティティは知識グラフの構成要素であり、人、場所、物などの実世界のエンティティを含む。エンティティは、意味のある情報を持つノードである。例えば、「アルバート・アインシュタイン」は、生年月日や職業などの属性を持つエンティティである。最終的に、エンティティは意味のあるリンクの基盤となる。
関係(エッジ)
関係とは、グラフのエッジを形成する、物事同士のつながりのことである。例えば、"Albert Einstein" → "was born in" → "Germany "のように、リレーションシップは物事が互いにどのように関連しているかを記述する。リレーションシップはデータに文脈を与え、関連する情報のネットワークを私たちに提示する。
属性(プロパティ)
属性はエンティティ固有の情報で、ナレッジグラフの詳細情報を提供する。「Paris "は "Population: 2.1 million "と "Country:属性として "France "があります。属性は、各エンティティの重要な背景情報を提供します。
オントロジー(スキーマまたは構造)
オントロジーはグラフの形を決定し、エンティティのタイプと関係を指定することでグラフを制約する。オントロジーは、何をどのように関連付けることができるかを指定することで、データの一貫性を確保するのに役立つ。例えば、"Person "は "Movie "では "act in "できるが、"City "では "act in "できない。
識別子(ユニークID)
固有のIDは、類似した実体を区別する。例えば、"Apple "という単語は、果物や会社を表すことができるが、どちらもユニークなIDを持っている。識別子はグラフを正しく表示し、混乱を防ぐ。
推論と推理
推論によって、グラフは関係から新しいつながりを作ることができる。例えば、"John "が "Emma "の父親で、"Emma "が "Liam "の妹であれば、グラフは "John "が "Liam "の父親であると推論できる。この推論はグラフを知的なものにする。
これらのコンポーネントが連携することで、整理された有用な情報体が形成され、よりインテリジェントな検索やAIアプリケーションにつながる。
ナレッジグラフはどのように機能するのか?
ナレッジグラフは、多様なソースからの情報を統合し、エンティティとその関係の包括的かつ相互接続されたネットワークを作成します。ここでは、ナレッジグラフがどのように機能するかについて説明する:
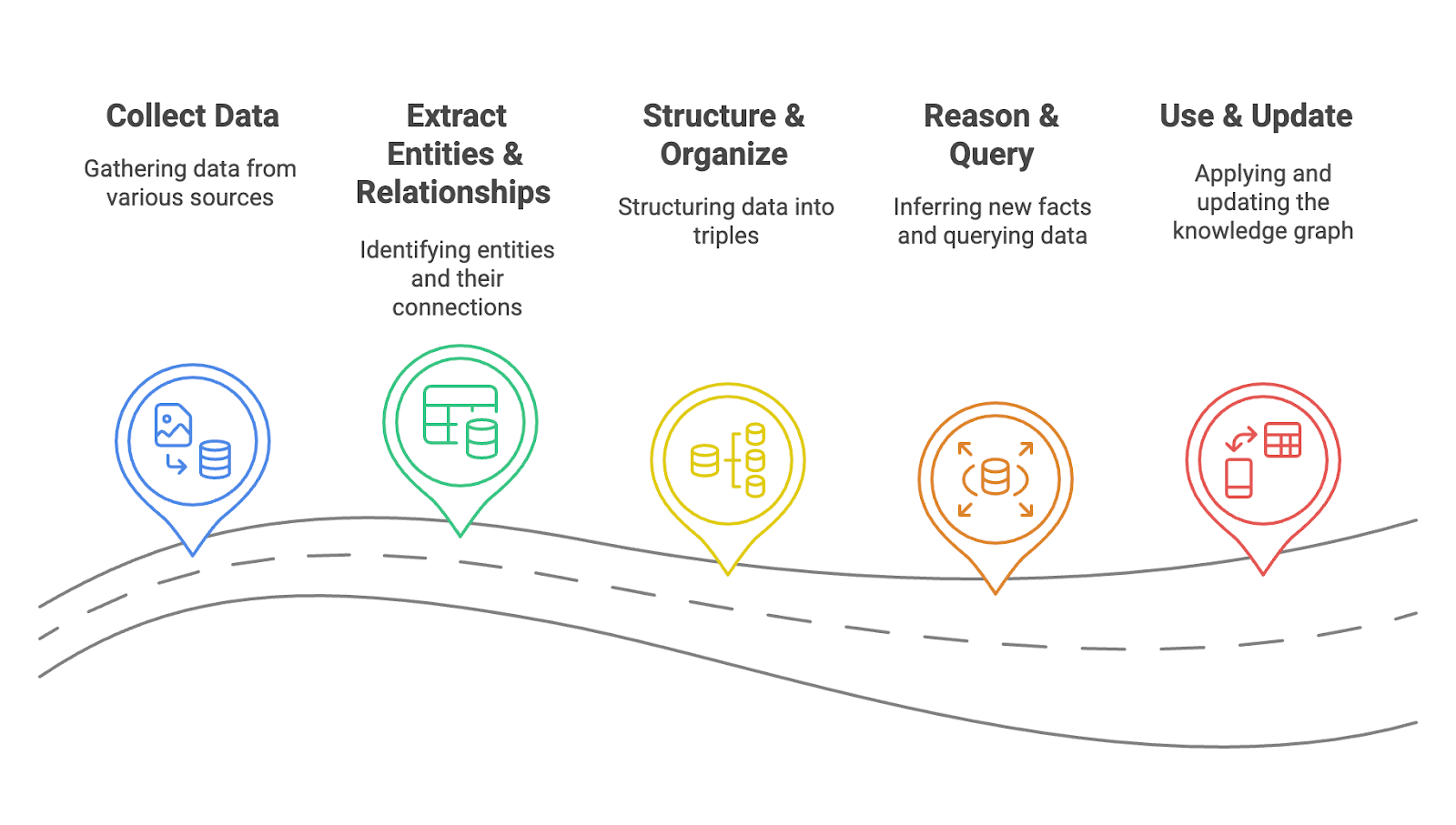
ステップ1:データの収集
ナレッジグラフは、データベース、テキストファイル、API、ウェブサイトなどのソースからのデータ収集から始まります。データは、構造化されたもの (スプレッドシートなど) または 不定形.目的は、できるだけ多くの情報を収集し、幅広い知識ベースを構築することである。
ステップ 2: エンティティと関係の抽出
次に、システムは、名前付きエンティティ認識(NER)や関係抽出のような技術を使用して、重要なエンティティ(例えば、人、場所、組織)とその関係を識別する。例えば、"Barack Obama "が個人であり、"United States "と "was President of "のような関係を持つことを抽出する。
ステップ3:構造化と組織化
検索されると、情報は構造化された形式で返される:(主語、述語、目的語)。この例は、(Paris, isCapitalOf, France)である。スキーマやオントロジーも、一貫性があり意味的に解釈できるように、エンティティや関係を分類するために作成される。
ステップ4:理由と問い合わせ
整理された知識グラフは、論理的ルールに基づいて新しい事実を推論することができる。例えば、"AはBの親である"、"BはCの親である "といった場合、グラフは "AはCの祖父母である "と推論することができる。ユーザーは、SPARQLのようなプログラミング言語を使ってグラフに問い合わせを行い、焦点となる情報を取得することができる。
ステップ5:使用と更新
最後に、ナレッジグラフは、検索エンジン、レコメンデーションシステム、チャットボットに力を与え、以下のものを統合する。 ハイブリッド検索, ベクターサーチそして 大規模言語モデル(LLM) よりスマートでコンテキストを意識した応答のために。定期的な更新により、知識の構造化とアクセスの正確性と動的性が維持されます。
このステップ・バイ・ステップのプロセスにより、生データは相互接続されたインテリジェントな知識の網へと変換される。
オントロジーと知識グラフ
オントロジーとは何か?
オントロジーとは、特定の関心分野における概念、オブジェクト、およびそれらの相互関係を記述した形式的な構造である。オントロジーは、データの分類と解釈に役立つルール、クラス、カテゴリーを提供する。
オントロジーとナレッジグラフの関係は?
ナレッジグラフはオントロジーを使ってデータを構造化し、一貫性と意味性をもたらす。オントロジーはナレッジグラフの骨格となるもので、エンティティがどのように分類され、リンクされているかを規定する。
例
映画のナレッジグラフは、オントロジーに従って記述される:
- 俳優が映画に出演できる
- 監督は映画を監督できる
- 映画にはジャンルがある
主な違い
| 特徴 | オントロジー | ナレッジグラフ |
|---|---|---|
| 目的 | ルールと関係を定義する | 実世界のデータを保存し、接続する |
| 構造 | 概念モデル(抽象) | データ・ネットワーク(実用的) |
| 使用方法 | 意味と推論を提供する | AIによる検索と分析が可能 |
ナレッジグラフの例
知識グラフの有名な例をいくつか紹介しよう:
- Googleのナレッジグラフ: この知識ベースは、エンティティ(人、場所、物など)間の関係を学習することで、検索結果を強化する。有名人やランドマークに関するナレッジパネルのように、検索結果に直接的な答えや、より詳細で文脈に応じた情報を提供します。
- リンクトインのナレッジグラフ この知識ベースは、人、役割、スキル、企業間の関係をマッピングします。あなたのプロフィールとネットワークに基づいて、おすすめの仕事、プロフェッショナルな関係、コンテンツを提供するのに役立ちます。
- フェイスブックのエンティティグラフ: このグラフは、ユーザー、ページ、投稿、「いいね!」、インタラクションを結びつけ、関連性の高いコンテンツや広告の配信に役立ちます。また、行動に基づいて関連性の高い投稿、グループ、イベントをレコメンドすることで、ユーザーエクスペリエンスを向上させます。
- アマゾンの製品グラフ: このグラフは、商品、レビュー、顧客の嗜好情報を整理したものです。閲覧履歴や購入履歴を通じて、類似商品や関連商品を提案することで、アマゾンのレコメンデーションエンジンの原動力となっている。
それぞれのグラフは、パーソナライズされた、コンテキストを考慮したレコメンデーションにより、より良いユーザー体験を可能にする。
ナレッジグラフの使用例
ここでは、ナレッジグラフを業界横断的に活用する方法をいくつか紹介する:
- 推薦システム: Eコマースやストリーミング・プラットフォームは、ナレッジ・グラフを次のように利用している。 パーソナライズ・レコメンデーション.アマゾンはユーザーの行動に基づいて商品を提案し、ネットフリックスは視聴パターンを分析してコンテンツを推薦する。
- 不正検知とリスク分析 金融機関は、取引における疑わしい関係や隠れたパターンを特定することで、不正行為を検知します。ナレッジグラフは、信用リスクの評価やコンプライアンスの改善にも役立ちます。
- ヘルスケアと生物医学研究: 医療関係者はナレッジグラフを患者記録、薬物相互作用、臨床試験のリンクに利用している。研究者は、創薬や治療法の革新を加速するためにナレッジグラフを活用しています。
- サイバーセキュリティと脅威インテリジェンス サイバーセキュリティチームは、ナレッジグラフを使用して攻撃パターンと悪意のあるエンティティを分析します。ナレッジグラフは、脅威の検出、脆弱性の特定、セキュリティ防御の強化に役立ちます。
- スマートアシスタントと自律システム: 自動運転車やスマートシティは、ナレッジグラフを使って空間データやIoTデータを構造化している、 リアルタイムの意思決定を可能にする そして自動化。
ナレッジグラフの利点
ナレッジグラフは、複雑なデータを整理、接続、推論できるようにすることで、AIアプリケーションに利益をもたらす。ナレッジグラフの具体的な活用方法を紹介しよう:
- 検索と発見の強化: ナレッジグラフは、関連する概念をリンクし、情報の断片間のつながりを推測することで、セマンティック検索とインテリジェントなクエリ応答を可能にします。この機能により、ウェブや内部検索エンジンのユーザーエクスペリエンスが向上します。
- パーソナライゼーション: ナレッジグラフは、ユーザーの行動や嗜好を理解することで、パーソナライゼーションを可能にする。この機能により、アプリケーションはパーソナライズされたレコメンデーションを行い、ターゲットを絞った広告活動を改善することができる。
- 自然言語処理(NLP): 知識グラフは、固有表現認識、質問応答(QA)、テキスト要約などの自然言語処理アプリケーションを可能にする。これらの機能は、機械が人間のような回答を理解し、生成することを可能にし、次のような機能を強化する。 チャットボットとバーチャルアシスタント.
ナレッジグラフの作り方
ナレッジグラフの構築には以下のステップがある:
1. 目的と範囲を明確にする: アプリケーションに関連するドメイン、主要エンティティ、およびリレーションシップを特定する。
2. データを収集し、処理する: 構造化データ(データベースやAPI)と非構造化データ(文書やテキスト)を収集し、それをクレンジングして正規化する。
3. エンティティと関係を識別する: NLPを使用してデータ内の主要概念を特定し、それらをグラフ形式で構造化する。
4. グラフデータベースに保存する: Neo4jやAmazon Neptuneのようなデータベースを使って、データのリレーションシップを保存・管理する。
5. クエリーと分析 Cypher、Gremlin、SPARQLのような言語を使用して、洞察力を得て、データのパターンを発見する。
6. 可視化し、展開する: Gephi、Linkurious、GraphXなどのソフトウェアを使用して、データの関係を視覚化し、アプリケーションに展開する。
主な要点とその他のリソース
この資料で、私たちは次のことを学んだ:
- ナレッジグラフは、データをエンティティや関係性に構造化し、検索機能を向上させ、AIアプリケーションを強化し、意思決定を支援する。
- ナレッジグラフは、検索エンジンやレコメンデーションシステムに力を与え、金融機関が不正を検出することを可能にし、医療専門家が患者のケアを改善することを可能にし、サイバーセキュリティの専門家が脆弱性を検出してセキュリティを強化することを支援する。
- ナレッジグラフの構築には、スコープの定義、データの収集、エンティティの特定、グラフデータベースの利用、洞察のクエリ、結果の視覚化が含まれる。
- Neo4jやAmazon Neptuneのようなグラフ・データベースは、ストレージと分析によく使われる。
- クエリにはCypher、Gremlin、SPARQLが使われ、GephiやLinkuriousのような可視化ツールは関係性の探索に役立つ。
AIに関連するコンセプトについてもっと知りたい方は、以下をご覧ください。 ハブ そして、以下のリソースをご覧ください:
その他のリソース
- コンセプトからコードへ:CouchbaseとLLM + RAG
- CouchbaseとジェネレーティブAIの仕組み
- LLMエンベッディングの手引き
- 知識ベース集団 (KBP) - スタンフォード自然言語処理グループ
よくあるご質問
AIにおける知識グラフとは何か? AIにおいて、知識グラフとは、機械による理解、推論、意思決定を可能にするために、実体、概念、およびそれらの関係を結びつけるデータの構造化表現である。
ナレッジグラフは何に使うのか? 知識グラフは、検索、推薦システム、データ統合、人工知能、自動推論を改善するために使用される。
グラフデータベースとナレッジグラフの違いは? グラフ・データベースは、ノードとエッジを使用して接続されたデータを保存および管理する。一方、知識グラフは、知的推論のためにオントロジー、関係、文脈理解を組み込むことによって意味的な意味を付加する。
トリプルストアとは? トリプルストアは、主語-述語-目的語のトリプルでデータを格納・管理するように設計されたデータベースであり、知識グラフにおける効率的なクエリや意味関係の検索を可能にする。
ChatGPTはナレッジグラフを使っていますか? ChatGPTは知識グラフを直接使用していませんが、テキストデータで訓練された大規模言語モデル(LLM)に依存しています。