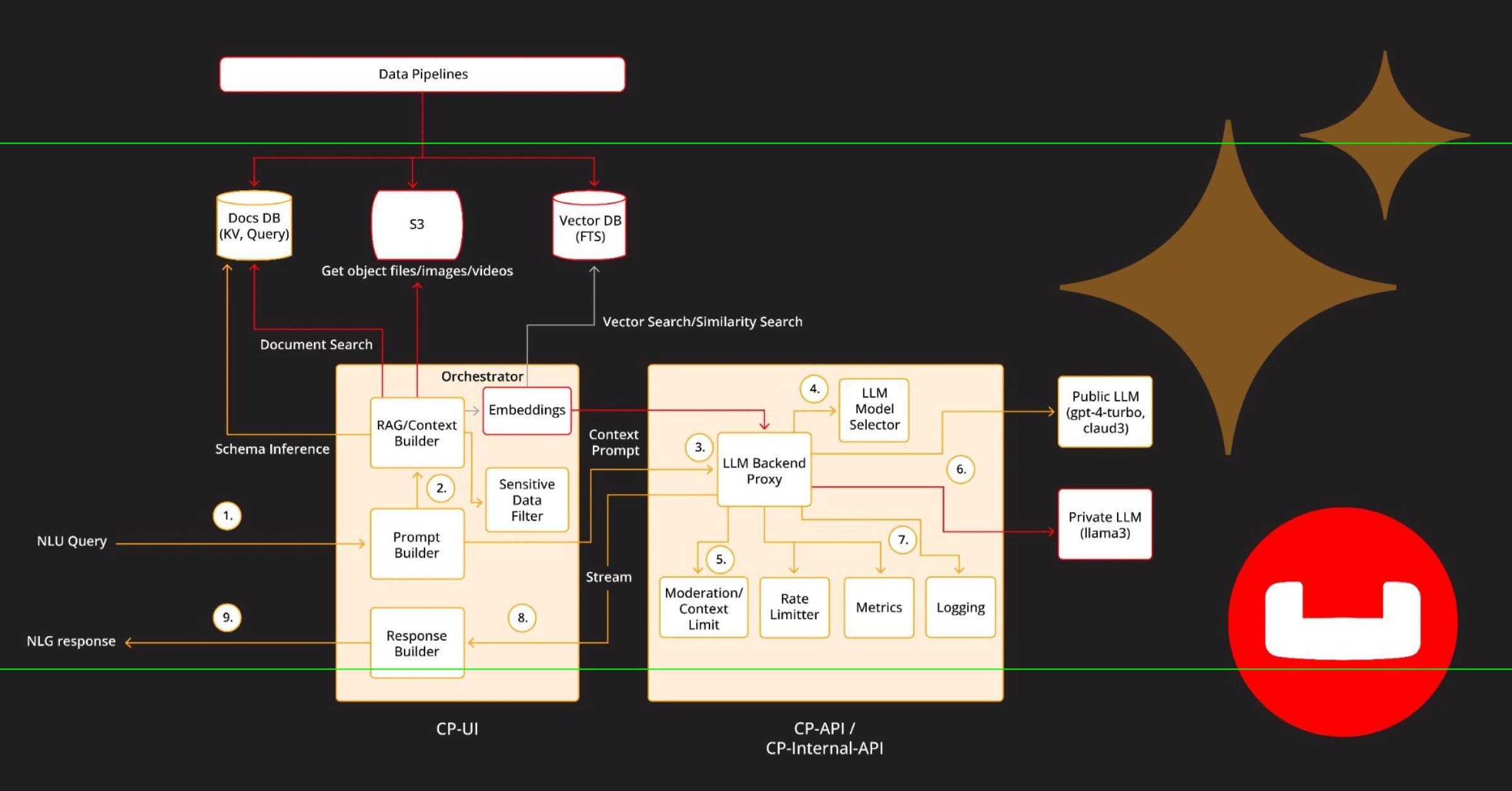
Capella iQ reference architecture
In the rapidly evolving landscape of Artificial Intelligence (AI), the integration of advanced database solutions with generative AI models represents a significant stride forward. This blog presents the architecture of Capella iQ, a Generative AI (Gen AI) application using Couchbase NoSQL database that understands the natural language query prompts to generate SQL++ queries and also code generation in different Couchbase client SDK languages. The Capella IQ is a coding assistant that’s built into the Capella Workbench and popular IDEs to help developers instantly become more productive. See the tutorial on how to work faster with iQ.
Overview of the architecture
The architecture depicted in the below provided diagram showcases a robust pipeline that seamlessly integrates various components to deliver Capella iQ, a generative AI solution for the application developers. One of iQ’s primary objectives is to integrate powerful AI models for natural language understanding (NLU) and natural language generation (NLG) with the strengths of the Couchbase NoSQL database, utilizing SQL++ and SDKs for efficient data handling and retrieval. The future iQ section in the diagram will be delivered in the next version of iQ.
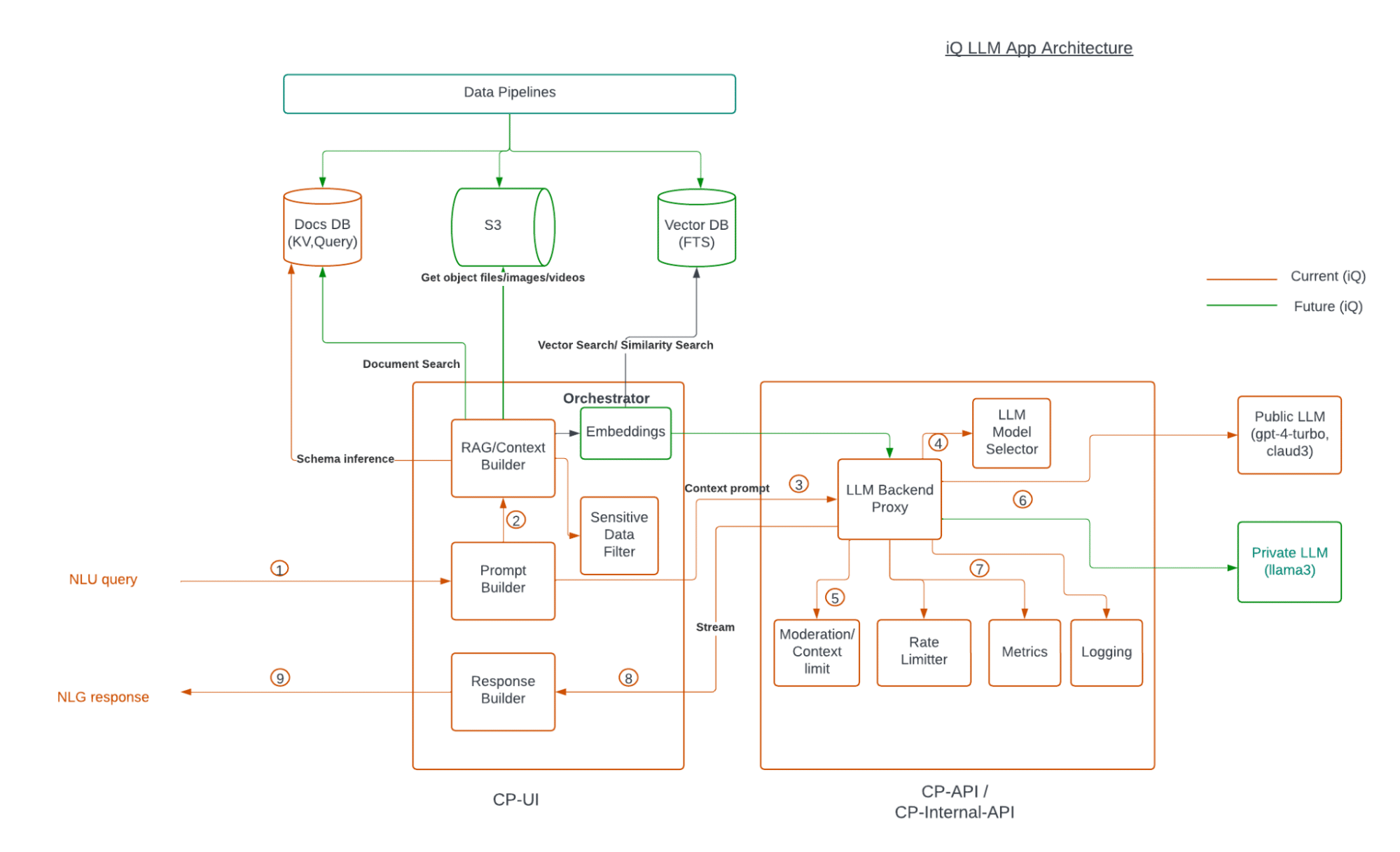
Key components of the architecture
1. Data pipelines
Data pipelines are the lifeblood of any AI-driven application. They are responsible for ingesting data from various sources and preparing it for processing. In this architecture, data pipelines funnel data into multiple storage systems, ensuring that the system is constantly updated with relevant information. This continuous flow of data is crucial for maintaining the accuracy and relevance of AI model outputs.
For external Couchbase Gen AI applications, this module can bring the data either directly or stream from other sources using connectors or Couchbase Analytics ingestion services. Specific to Capella iQ, there is no need for an additional pipeline as the data already exists in the Couchbase.
2. Storage solutions
The architecture leverages multiple storage solutions to handle different types of data efficiently:
A) Docs DB (Couchbase Key-Value, Query): This component is responsible for storing documents in a flexible schema, allowing for efficient key-value lookups and complex queries. Couchbase excels in providing these capabilities with low latency. This database is ideal for semi-structured or flexible schema data that requires fast read and write operations.
B) Object Storage (AWS S3/GCP/Azure): Used for storing object files, images, and videos, S3 like objectstore provides a scalable and cost-effective solution for handling large amounts of unstructured data. This component is essential for storing media files and other large objects that do not fit neatly into a traditional database schema.
C) Vector DB (Couchbase Full-Text Search): This database is optimized for vector search and similarity search, enabling the system to perform advanced searches based on embeddings and other vector representations. This is particularly important for applications that require semantic search capabilities, where understanding the meaning of the content is as important as the content itself.
Specific to Capella iQ, the customer data is already stored in the Couchbase Capella cluster document DB. No other specific activity is required in iQ itself.
For the external Gen AI applications, one could store the data and vectors into the Couchbase cluster and Vector search through FTS using the above data pipeline modules.
3. Orchestrator and embeddings
The orchestrator manages the flow of data and operations within the system. It handles embeddings, which are crucial for transforming textual data into numerical vectors that AI models can process. Embeddings are a key component of modern AI systems, as they allow for the representation of words, phrases, and even entire documents in a way that captures their semantic meaning.
Specific to iQ, the UI component is the overall application workflow orchestrator where the conversational interaction, contextual prompt building and also interactions with the iQ backend proxy, which, in turn, communicates to the LLMs. In the current iQ, there are no embeddings generated as there is no similarity search and no private data is being communicated to LLMs. In the future, iQ embeddings generation is planned from the Private LLM embeddings.
The external Gen AI application based on Couchbase can do the workflow orchestration as well as generation of offline embeddings for the documents so that vector indexing can happen automatically during the documents mutation.
4. Context and prompt builders
Below are two important submodules that help in preparation of the contextual prompt building so that it can converse with LLMs.
RAG/context builder
This component assembles relevant context for queries using Retrieval-Augmented Generation (RAG) techniques. RAG enhances the capabilities of generative AI by incorporating private and/or external information into the response generation process, ensuring that the AI model has access to pertinent information for generating accurate responses. This is particularly useful for applications that require dynamic and contextually aware domain specific responses. In Capella iQ, the context contains the schema inference, which is going to be derived from the user selected scope and its collections.
Prompt builder
Constructs prompts that are fed into the AI models, ensuring that the input format aligns with the model’s requirements for optimal performance. The prompt builder takes the raw input from the user and transforms it into a structured format that the AI model can understand and process effectively.
In the current iQ, the flexible schema inference is derived from the user selected bucket, scope and collections and no actual sensitive or private data is sent to the LLMs. There is no RAG in the current iQ implementation. In the future iQ, the plan is to perform Couchbase data vector indexing with auto embeddings generation on the data using private hosted LLMs.
For the external Couchbase based Gen AI applications, this module can automatically do the generation of embeddings for the user prompt and then perform the RAG with similarity or vector search in the Couchbase and finally prepare the contextual prompt that is ready to send it to the LLMs.
5. Sensitive data filter
To ensure compliance with data privacy regulations, this filter scrutinizes data for sensitive information, preventing it from being processed or stored inappropriately. This component is critical for applications that handle personal or sensitive information, as it helps to protect user privacy and maintain compliance with regulations such as GDPR and CCPA.
Specific to the current iQ, only schema inference is sent without any private or sensitive data sending it to LLMs. In the future iQ, the plan is to send private data to the private hosted LLMs within the data plane VPC.
In the external Gen AI applications, the sensitive data should be filtered before sending to public LLMs and private data can be sent directly to private hosted or enterprise LLMs.
6. LLM backend proxy: the heart of model interaction
The LLM Backend Proxy is a pivotal component in the architecture of a generative AI application. It acts as the central hub through which all interactions with large language models (LLMs) are routed, ensuring efficient communication, appropriate model selection, and adherence to operational constraints. Let’s delve deeper into its functionalities and significance.
Responsibilities of the LLM backend proxy
Model selection
Dynamic model selection
The LLM Backend Proxy dynamically selects the appropriate language model for each task based on criteria such as query complexity, user preferences, model availability, and performance metrics. For instance, a simple factual query may be routed to a lightweight model, while a more complex query requiring nuanced understanding could be directed to an advanced model like GPT-4 Turbo or a specialized private LLM like Llama 3.
Context-aware selection
The proxy evaluates the context of the user query and chooses a model that has been fine-tuned or specialized for the specific domain, ensuring that responses are both accurate and contextually relevant.
Moderation
Content moderation
The proxy ensures all responses generated by the LLM adhere to predefined guidelines and ethical standards. It performs content filtering to prevent the generation of harmful, offensive, or inappropriate content, which is crucial for maintaining trust and safety in user-facing applications.
Context limits
The proxy enforces context limits by ensuring that the input context provided to the LLM does not exceed the model’s maximum token limit, optimizing performance and preventing errors or the truncation of important information.
Rate limiting
Request throttling
The LLM Backend Proxy implements rate limiting to control the flow of requests sent to the LLMs. This helps manage system resources efficiently and prevents overloading the models, ensuring responsiveness even under heavy load.
User-Specific limits
The proxy can apply rate limits on a per-user basis, such as limiting tokens and calls, to prevent system abuse or misuse. For example, a user may be restricted to a certain number of calls per minute to ensure fair usage.
Logging and monitoring
Comprehensive logging
The proxy maintains detailed logs of all interactions with the LLMs, including query parameters, response times, and any errors encountered. These logs are essential for troubleshooting, auditing, and improving system reliability.
Real-time monitoring
The proxy provides real-time monitoring of system performance, allowing administrators to track key metrics such as response times, query volumes, and model utilization, facilitating proactive management and quick issue resolution.
Integration with metrics and analytics
Service metrics
The proxy collects and aggregates data on errors and status codes from the LLMs, providing insights into model efficiency, accuracy, and resource consumption. These metrics are critical for continuous optimization and improving service reliability.
User interaction analytics
The proxy tracks user interactions and feedback, helping to understand user behavior and preferences. This data can be used to refine model responses and enhance the overall user experience.
7. Public and private LLMs
The current iQ system integrates popular public LLMs (e.g., GPT-4 Turbo, Claude 3) for carrying out the Gen AI operations. The future iQ plan is to integrate private hosted LLMs (e.g., Llama 3, ), providing flexibility in choosing the best model for specific use cases.
The public LLMs offer powerful capabilities and are ideal for general-purpose applications, while private LLMs can be customized and fine-tuned for specific tasks, providing greater control and potentially better performance for specialized applications.
8. Moderation and rate limiting
Moderation and context window limit
This component ensures that AI-generated content adheres to predefined guidelines and stays within contextual window limits. In the current iQ implementation, moderation checks are in place to prevent the generation of harmful or inappropriate responses, though no additional moderation is applied to generated content at this time. To avoid errors related to exceeding the LLM’s context window, content is trimmed from the beginning to fit within the model’s context size. In future iQ versions this component might also handle tasks like caching, feedback management, and sandbox-style execution of LLM-generated content. In external generative AI applications this module can provide similar moderation, ensuring a safe content generation process.
Rate limiter
The rate limiter manages the flow of requests to prevent system overload, ensuring smooth and responsive operations. It helps maintain performance and stability even under heavy load by controlling the number of requests. Rate limiting is applied at multiple levels: the number of calls per minute per user, the number of tokens used per day per user, and the number of tokens used over a month at the tenant level.
9. Metrics and logging
Metrics
Metrics are collected to monitor and optimize the system’s efficiency and effectiveness. They provide valuable insights into system performance, enabling continuous improvement and optimization. The SRE management system includes a dedicated dashboard for collecting metrics data and visualizing it through charts.
Logging
Logs are maintained for troubleshooting, auditing, and enhancing the system’s reliability. Logging is crucial for diagnosing issues, tracking system behavior, and ensuring accountability and transparency.
Benefits of using Couchbase for docs and vector storage
Couchbase’s NoSQL database along with Vector DB feature provide several advantages in this architecture:
Scalability: Handles large volumes of data with ease, supporting horizontal scaling. This is particularly important for AI applications that require processing vast amounts of data in real-time.
Flexibility: Supports various data models (key-value, document) and complex queries. Couchbase’s flexibility allows it to handle a wide range of data types and structures, making it ideal for dynamic and evolving AI applications.
Performance: Offers low latency and high throughput, essential for real-time AI applications. Couchbase’s performance ensures that the system can deliver fast and responsive interactions, even under heavy load.
Integration with AI models: Couchbase’s ability to integrate seamlessly with AI models and handle complex queries makes it a powerful backend solution for generative AI applications. Its support for full-text search and vector search enhances the system’s ability to perform advanced searches and deliver accurate results.
Summary of Gen AI building steps
The generative AI application’s workflow begins with an NLU query input from the user interface (CP-UI) and ends with generation of content, following through these generic steps below:
- Prompt Building: The initial NLU query is transformed into a structured prompt by the Prompt Builder. This step involves parsing the user input and constructing a format that the AI model can understand and process effectively.
- Context Building: Relevant context is gathered using the RAG/Context Builder. This step involves retrieving external information that is relevant to the query, enhancing the AI model’s ability to generate accurate and contextually appropriate responses.
- Sensitive Data Filtering: Ensures the prompt and context data are free from sensitive information. This step is critical for maintaining user privacy and compliance with data protection regulations. Next, it interacts with the LLM backend proxy REST endpoint with all necessary contextual payload.
- Model Selection and Proxy: The LLM Backend Proxy selects the appropriate model based on the query and forwards the prompt. This step involves choosing the best model for the task, considering factors such as model capabilities, performance, and specific use case requirements.
- Moderation and Rate Limiting: The query is moderated and rate-limited to ensure compliance and performance. This step involves checking the content for appropriateness and ensuring that the system is not overwhelmed by excessive requests.
- Response Generation: The selected LLM generates a response, which is then streamed back to the backend proxy. This step involves processing the prompt and context to generate a natural language response that addresses the user’s query.
- Response Building: The processed response is structured and formatted for the user. This step involves transforming the raw AI-generated response into a format that is easy for the user to understand and use.
- Response Delivery: The final NLG response is delivered to the user through the CP-UI. This step involves presenting the response to the user in a clear and user-friendly manner.
Conclusion
Integrating Couchbase database with a generative AI application architecture offers a powerful solution for modern AI needs. This architecture not only leverages the flexibility and scalability of Couchbase but also ensures robust data handling, efficient processing, and accurate response generation. By adopting this architecture, developers can build advanced AI applications that meet the demands of today’s dynamic learning data environments.
The combination of Couchbase’s robust database capabilities and the advanced features of generative AI models provides a solid foundation for building innovative and efficient AI applications. Whether you are developing customer support bots, content generators, semantic search or advanced data analysis tools, this architecture offers the flexibility, performance, and scalability needed to succeed in the competitive AI landscape.
Next steps
Explore the potential of Couchbase and generative AI to revolutionize your applications. By leveraging the strengths of this powerful architecture, you can build AI-driven solutions that deliver exceptional performance, accuracy, and user satisfaction. Whether you are a developer, data scientist, or business leader, the integration of Couchbase and generative AI provides the tools and capabilities needed to drive innovation and achieve your goals.
Take the first step towards building the next generation of AI applications by embracing this architecture. Harness the power of Couchbase’s NoSQL and vector database and the advanced capabilities of generative AI models to create solutions that meet the demands of today’s dynamic data environments. By doing so, you can unlock new opportunities, improve operational efficiency, and deliver exceptional value to your users.
References
- AI Cloud Services, Capella iQ, and Vector Search
- Docs: Work Faster with Capella iQ
- Docs: Couchbase connectors
- Couchbase Analytics Adds Real-time Data Service
Acknowledgements
Thanks to the Capella iQ team (Keshav M, Steve Y, Dhinu S, Kamini J, Ravi K, Rob A, Piotr N, Elliot, Eben H, Sriram R, Nimiya J, Shaazin S, Bo-Chun, Sean C, Tyler M). Special thanks to Mohan V for helping on extra reviews and creating a good reader experience. Thanks to others who helped directly or indirectly!
Deixe um comentário
Você precisa fazer o login para publicar um comentário.