Don’t you love reading other people’s commit messages? No? Well, I do and as I was reading a very insightful commit message, I realized all the untapped content living in various Git logs (assuming the dev you follow are writing useful messages, of course). So, wouldn’t it be great if you could ask questions to a repo? Let’s see how this can be achieved doing RAG with Couchbase Shell.
TL;DR
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# with bash, extract your commit history to json source git–log–json.sh && git–log–json > commitlog.json # with cbsh, create scope, collection and collection Primary Index scopes create gitlog; cb–env scope gitlog;collections create commits; cb–env collection commits; query “CREATE PRIMARY INDEX ON `default`:`cbsh`.`gitlog`.`commits`” # Import the doc in selected collection open commitlog.json | wrap content | insert id { |it| echo $it.content.commitHash } | doc upsert # Enrich the document with default model query “SELECT c.*, meta().id as id, c.subject || ‘ ‘ || c.body as text FROM `commits` as c” | wrap content| vector enrich–doc text | doc upsert # Create a Vector Index vector create–index —similarity–metric dot_product commits textVector 1536 # Run RAG vector enrich–text “gemini” | vector search commits textVector —neighbors 20| select id |doc get| select content | reject –i content.textVector | par–each {|x| to json} | wrap content| ask “when and in which commit was gemini llm support added” |
Couchbase Shell configuration
The initial step is to install and configure cbsh. I am going to use my Capella instance. To get the config you can go under the Connect tab of your Capella cluster and select Couchbase Shell. This is the config under [[cluster]]. To configure the model, take a look at what’s under [[llm]]. I have chosen OpenAI but there are others. You need to define the model used for the embedding (that’s what turns text into a vector) and one for the Chat. This one takes the question and some additional context to answer the question. And of course you will need an API key.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
version = 1 [[llm]] identifier = “OpenAI” provider = “OpenAI” embed_model = “text-embedding-3-small” chat_model = “gpt-3.5-turbo” api_key = “sk-proj-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx” [[cluster]] identifier = “capella” connstr = “couchbases://cb.xxxxxxx.cloud.couchbase.com” user-display-name = “Laurent Doguin” username = “USER” password = “PASSWORD” default-bucket = “cbsh” default-scope = “gitlog” |
You also need Git installed, then you should be all set.
Import Git commit log
The first step is to get all the commits of the repo in JSON. Being lazy and old, and by old I mean not used to asking an AI, I searched for this on Google, found a number of Gists, that linked to other Gists, and I finally settled on this one.
I downloaded it, sourced it, went into my local couchbase-shell git repo and called it.
|
1 |
source git–log–json.sh && git–log–json > commitlog.json |
But, for the benefit of the reader wondering if I made the right decision, let’s ask the configured model. Cbsh has an ask command allowing you to to this:
|
1 2 3 4 5 6 |
👤 Laurent Doguin 🏠 capella in ☁️ cbsh.gitlog.commits > ask “get the full commits in json for a git repo” To get the full commits in a Git repository as JSON, you can use the following command: git log —pretty=format:‘{%n “commit”: “%H”,%n “author”: “%an <%ae>”,%n “date”: “%ad”,%n “message”: “%f”%n},’ —date=iso —reverse —all > commits.json |
This command will output each commit in the repository as a JSON object with the commit hash, author name and email, commit date, and commit message. The --all flag ensures all branches are included. The --reverse flag lists the commits in reverse chronological order. Finally, the output is redirected to a commits.json file.
Please make sure you run this command in the root directory of the Git repository you want to get the commits from.
And as it turns out, it does not work out of the box (shocking I know). And it did not have all the info I needed, like the body part of the message. Of course we could spend time tuning this, but it’s very specific, with lots of edge cases.
In any case I now have a list of commits in JSON format:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
[ { .... }, { “author”: { “name”: “Michael Nitschinger”, “email”: “michael@nitschinger.at”, “date”: “Thu, 20 Feb 2020 21:29:20 +0100”, “dateISO8601”: “2020-02-20T21:29:20+01:00” }, “body”: “”, “commitHash”: “7a0d269fffd10045a63d40ca460deba944531890”, “commitHashAbbreviated”: “7a0d269”, “committer”: { “name”: “Michael Nitschinger”, “email”: “michael@nitschinger.at”, “date”: “Thu, 20 Feb 2020 21:29:20 +0100”, “dateISO8601”: “2020-02-20T21:29:20+01:00” }, “encoding”: “”, “notes”: “”, “parent”: “”, “parentAbbreviated”: “”, “refs”: “”, “signature”: { “key”: “A6BCCB72D65B0D0F”, “signer”: “”, “verificationFlag”: “E” }, “subject”: “Initial commit”, “subjectSanitized”: “Initial-commit”, “tree”: “3db442f3ef0438de58f72235e2658e5368a6752b”, “treeAbbreviated”: “3db442f” }] |
So what can you do with a JSON array of JSON objects? You can import it through the Capella UI or you can import them with Couchbase Shell. I first create the scope and collection and select them with cb-env, then create the SQL++ Index.
|
1 |
scopes create gitlog; cb–env scope gitlog; collections create commits; cb–env collection commits; query “CREATE PRIMARY INDEX ON `default`:`cbsh`.`gitlog`.`commits`” |
Since cbsh is based on Nushell, the resulting JSON file can be easily opened, turned into a dataframe, transformed in a Couchbase document and inserted like so:
|
1 2 3 4 5 6 7 8 |
👤 Laurent Doguin 🏠 capella in ☁️ cbsh.gitlog.commits > open commitlog.json |wrap content | insert id { |it| echo $it.content.commitHash }| doc upsert ╭───┬───────────┬─────────┬────────┬──────────┬─────────╮ │ # │ processed │ success │ failed │ failures │ cluster │ ├───┼───────────┼─────────┼────────┼──────────┼─────────┤ │ 0 │ 660 │ 660 │ 0 │ │ capella │ │ ╰───┴───────────┴─────────┴────────┴──────────┴─────────╯ |
Let’s get some documents just to see how it worked:
|
1 2 3 4 5 6 7 |
👤 Laurent Doguin 🏠 capella in ☁️ cbsh.gitlog.commits > query “SELECT subject, body FROM `commits` LIMIT 1” ╭───┬──────────────┬──────┬─────────╮ │ # │ subject │ body │ cluster │ ├───┼──────────────┼──────┼─────────┤ │ 0 │ Bump Nushell │ │ capella │ ╰───┴──────────────┴──────┴─────────╯ |
So this is content we could use for RAG. Time to enrich these docs.
Enrich document with an AI model
To enrich the doc you need to have a model configured. Here I am using OpenAI and the enrich-doc cbsh command:
|
1 2 3 4 5 6 7 8 |
👤 Laurent Doguin 🏠 capella in ☁️ cbsh.gitlog.commits > query “SELECT c.*, meta().id as id, c.subject || ‘ ‘ || c.body as text FROM `commits` as c” | wrap content| vector enrich–doc text | doc upsert Embedding batch 1/1 ╭───┬───────────┬─────────┬────────┬──────────┬─────────╮ │ # │ processed │ success │ failed │ failures │ cluster │ ├───┼───────────┼─────────┼────────┼──────────┼─────────┤ │ 0 │ 61 │ 61 │ 0 │ │ capella │ ╰───┴───────────┴─────────┴────────┴──────────┴─────────╯ |
The SELECT clause will return a JSON object with the content of the doc, and additional fields id and text. Text is the subject and body appended into one string. The object is wrapped in a content object and given to the vector enrich-doc command, with text as a parameter, as it is the field that will be transformed in a vector. There should now be a textVector field in each doc.
Vector Search
In order to search through these vectors, we need to create a Vector Search index. It’s doable through the API or UI for something customizable. Here I am happy with default choices so I use cbsh instead:
|
1 2 |
👤 Laurent Doguin 🏠 capella in ☁️ cbsh.gitlog.commits > vector create–index —similarity–metric dot_product commits textVector 1536 |
The index created will use dot_product as a similarity algorithm, vector dimensionality will be 1536, the name of the index is commit and the indexed field is textVector. The bucket, scope and collection are the one selected through cb-env.
To test vector search, the search query has to be turned in a vector, than piped to the search:
0
It returns 3 rows by default. Let’s extend it to see the content of the document. I am adding reject -i textVector to remove the vector field, because no one needs a 1536 lines field in their terminal output:
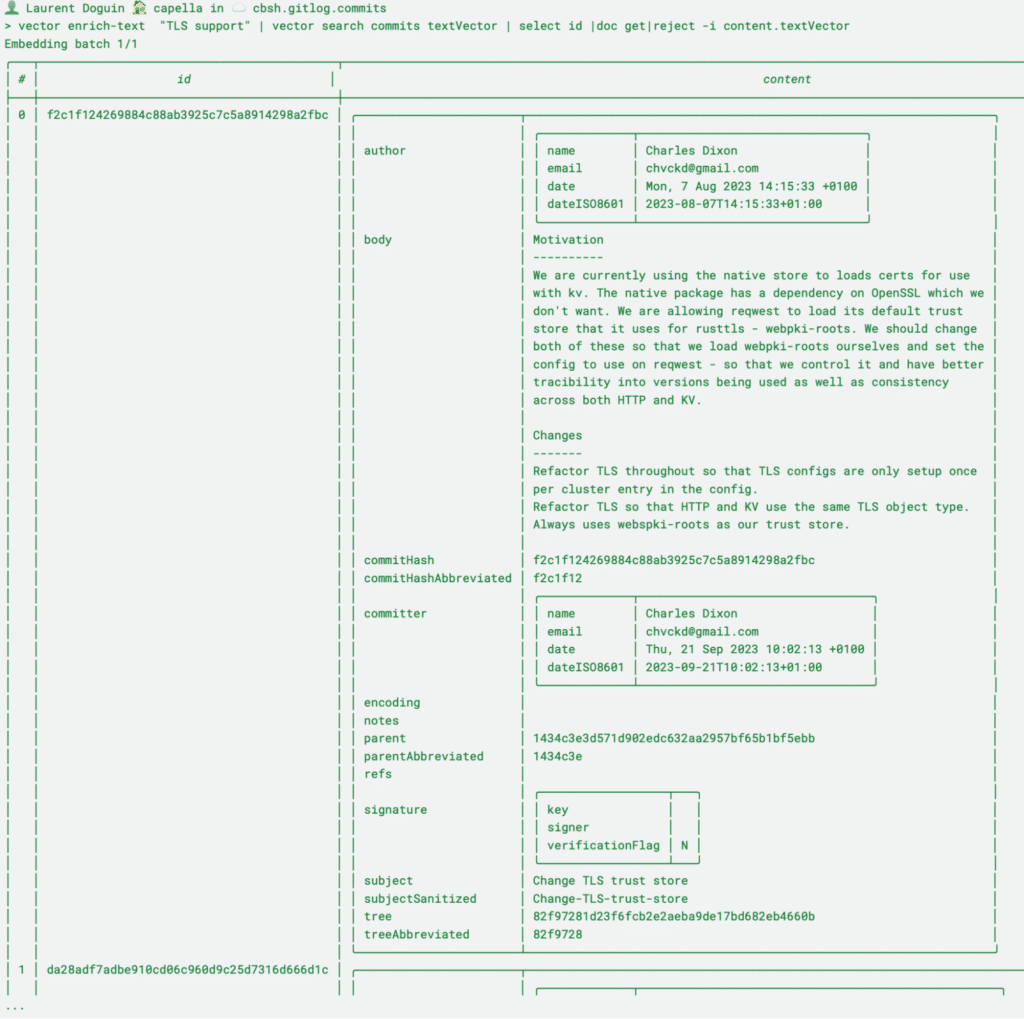
Ask your Git Repository
From here you have all the commits of a Git repository stored in Couchbase, enriched with an AI model, and all indexed and searchable. The last thing to do is call the model to run a query with RAG. It starts by a turning a question into a vector, pipe it to a vector search, get the full document from the return IDs, select the content object without the vector field, turn each object in a JSON doc (this way we can send the content and its structured metadata), wrap the jsonText in a table and finally pipe it to the ask command:
1
Asking the LLM when Gemini support was introduced. We get a date and a commit hash. It’s then easy to verify using git show. There is a bit of repetition here so you can declare a variable for your question and reuse it:
2
And now we all know why the client crate had to be rewritten. It may not answer your own questions, but now you know how to get answers from any repo!
- Get started with Capella for free
- Read our Guide for LLM Embeddings
- Read more of my developer blogs on vector search and more
- Try Couchbase Shell today

Author
2개의 응답
-
Very cool. It would be interesting to include the full changelog, to give the LLM more context.
-
Yeah I was thinking about Github PR as well. Plenty of potential!
-
댓글 남기기
댓글을 달기 위해서는 로그인해야합니다.