Faster scaling of database resources is essential for maintaining efficient and performant databases, especially with the increased pressure of data ingestion, growing query demands, and the need to handle failovers seamlessly. As application-driven query traffic is primarily handled by index services, faster scaling of index rebalance services is critical to highly performant applications.
For the index service, the scaling operation (also referred to as rebalance) involves moving individual indexes/replicas/partitions among the available index service nodes in the cluster. The aim is to minimize load imbalances and optimize resource utilization metrics, like CPU and memory, across all nodes.
This article explores the limitations and improvements made to the index rebalance process in Couchbase-Server Version 7.6. It introduces a new rebalance flow based on efficient file transfers, offering significant benefits such as substantial reductions in rebalance time and optimized resource utilization, including lower CPU and memory consumption.
Overview of index service rebalance
At a high level, index service rebalance operates in 3 phases:
Planning
- In the planning phase, the information of all indexes across all nodes in the cluster is gathered, along with their load statistics. Load of an index is derived from various factors like CPU utilization, memory utilization, scan rate, mutation processing rate, disk utilization, etc.
- An optimization algorithm is used to minimize load variance across the cluster. For example, if an index service node experiences significantly higher mutation and scan traffic compared to others, the algorithm redistributes indexes to balance the overall load and reduce variance.
- The optimization algorithm decides the index movements from their existing nodes to new nodes in a simulated environment to arrive at a distribution that minimizes the load variance in the cluster.
Execution phase
- Based on the final plan decided in the planning phase, indexes are moved from their existing nodes to new targets.
- This phase is the most significant contributor to index rebalance time, directly impacted by the movement method and the number of indexes involved.
Dropping indexes on source nodes
- Once the indexes on the new target nodes are fully rebuilt and ready to handle queries, all incoming scan requests for those indexes will be redirected to the new nodes.
- The indexes on the existing source nodes will be removed once the corresponding indexes on the new nodes are ready to serve scan traffic.
The Execution phase, currently relies on rebuilding the indexes that are being moved by re-streaming and re-processing all the documents from the data service. While this scheme works well functionally, it has these drawbacks:
- Increased index rebalance times
- Slower scans
- Slower mutation processing
These drawbacks are mainly due to:
Resource overheads during rebalance
- The data service has to restream all the documents relevant to the index for the purpose of rebuilding the indexes. Often, restreaming all the data requires backfilling from disk, which can lead to additional pressure on disk
- The projector process has to reprocess all the documents to extract data relevant to this index and this can take up additional CPU and memory. These overheads can also create resource contention for incremental traffic to existing indexes.
- For the indexer process as well, index builds add considerable resource overheads on CPU, memory, and disk I/O due to the new incoming mutation traffic. In general, random I/O read operations are required during certain stages of index building which slows down the entire index build pipeline.
Working set disruption
- The memory requirements due to Index rebuild during reduce the memory available for existing indexes
- The working set of existing indexes may be evicted out of memory
- This causes scans and mutation processing to slow down if the relevant data is not available in memory and needs to be fetched from disk
File transfer rebalance
File transfer rebalancing is one approach to reduce the overhead of rebuilding indexes. Instead of rebuilding indexes, the source node directly transfers indexed data files to the target node without interacting with the data service. Once data transfer is complete, the index service will catch up with mutations that occurred during the transfer by streaming them from the data service. Scans and mutations will continue to be processed for existing indexes irrespective of the status of transfer.
The data transfer between source and target nodes occurs via a custom protocol built on top of the HTTP request-response model. The source node contains a client capable of sequentially reading snapshotted indexed data from disk and publishing the data to the target node as multiple small, binary blobs. The data transfer is always encrypted. The target node hosts a server that receives these binary blobs, decrypts them and reconstructs the indexed data during the transfer process. All data received by the server on the target node is persistently stored onto disk.
Upon data transfer completion, the target node recovers the index from disk and rolls back to a valid recovery point available within the transferred data. It then requests the data service to stream mutations that occurred since the generation of that recovery point. Once all necessary mutations are processed, the index becomes scan-ready on the target node and is subsequently dropped from the source node.
Since most indexed data is directly transferred, bypassing the need for rebuilding, the overhead associated with index rebuilds is eliminated during data transfer. This has significantly improved rebalance speed while reducing associated CPU and memory consumption. As a result, the impact on the working set is also minimal, allowing scans and mutation traffic to be processed at similar rates as before the rebalance.
The only resource overheads incurred with file transfers are those related to data transfer itself and catching up on any mutations that may have occurred during the transfer process. The resource utilization during the data transfer and recovery process can be broken down as follows:
- Disk read bandwidth (source node) – Efficient, due to sequential reads.
- CPU and memory (source node) – Minimal, due to publishing small binary blobs.
- CPU and memory (target node) – Minimal, due to processing small binary blobs.
- Disk write bandwidth (target node) – Efficient, due to primarily sequential writes.
- Disk read bandwidth (recovery, target node) – Minimal, as only a portion of data needs recovery.
To minimize disruptions to critical scan and mutation operations, both source and target nodes restrict disk bandwidth to a configurable value, defaulting to 200MB/sec, during rebalance. This empirically chosen rate ensures balanced efficiency and minimal performance impact, with observed resource consumption of less than 2 CPU cores and tens of MB of memory per node.
Performance results with file transfer rebalance
Benchmark setup
- Cluster setup:
- Data service nodes: 4
- Index nodes: 3
- Data:
- Volume: 1 Billion documents
- Avg. doc size: 230 bytes
- Distribution: Shared across 2 collections in a single bucket
- Indexes:
- Type: Partitioned
- Replication: 1 replica per index
- Number of partitions: 3 per index
- Total instances: 18 (3 indexes * 3 partitions * 2 replicas)
- Avg. secondary index field size: 140 bytes
- Total disk usage: ~710GB (across all instances)
- Index Service Resources:
- Memory quota: 128GB per node
- CPU cores: 80 per node
Comparison
This performance benchmark compares two rebalance methods for rebalance times, CPU, and memory utilization for the swap rebalance case:
- Index Rebuild Rebalance (DCP Rebalance) – Rebuilds indexes from scratch during rebalancing.
- File Transfer Rebalance – Directly transfers existing index data files between nodes.
Rebalance-swap
- We begin with 2 index nodes in the cluster, each holding around 355GB of indexed data across 9 index instances on each node.
- We add a new index node and remove an existing one.
- All indexed data from the removed node is transferred to the newly added node.
- Scan traffic continues to hit the initial nodes until the data transfer is complete.
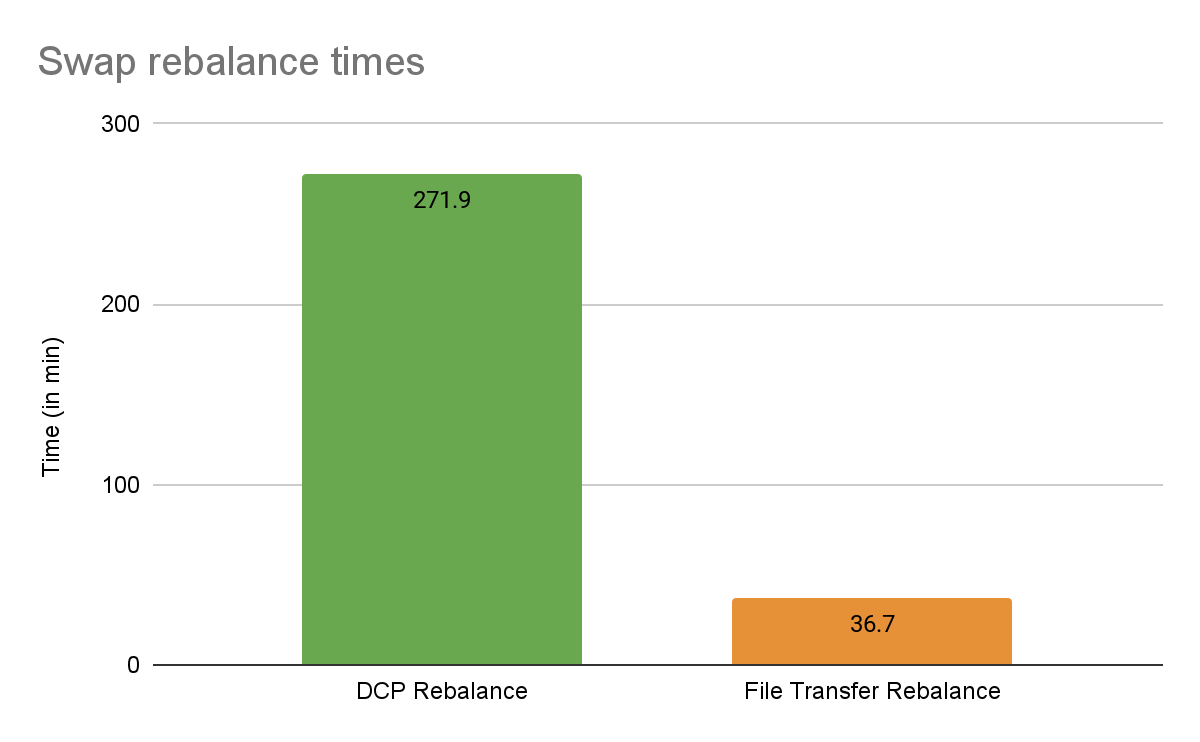
Swap rebalance time comparison
File transfer rebalance completed in just 37 minutes, compared to a staggering 272 minutes with the traditional DCP rebalance method. This represents a 7x improvement in speed! This efficiency is largely due to the direct transfer of data files, instead of rebuilding them entirely. While the data transfer itself would theoretically take around 29.6 minutes (assuming a sustained 200MB/sec), the overall rebalance time aligns well with the actual end-to-end rebalance time (including planning and catchup phases).
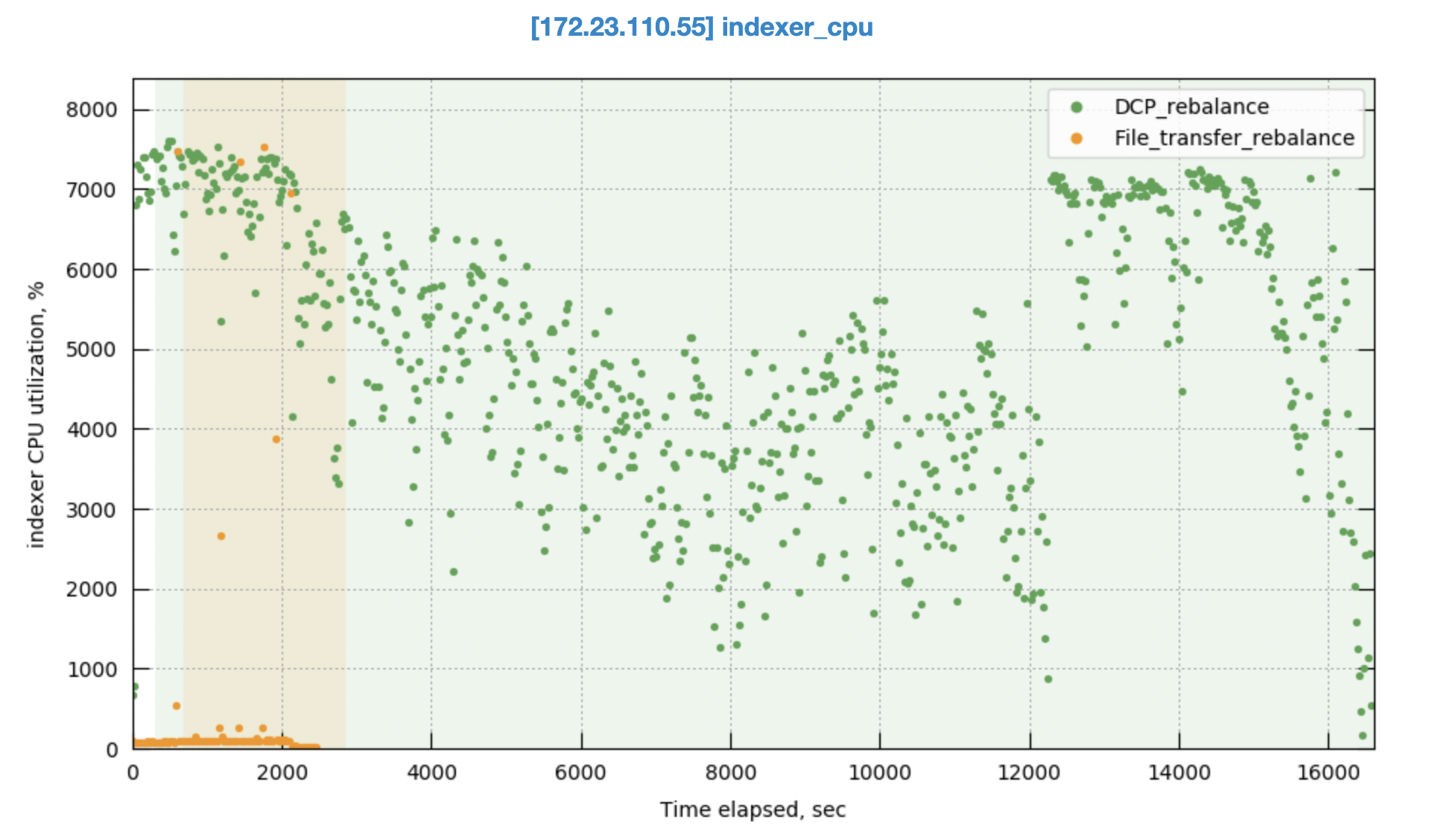
Rebalance CPU comparison
DCP rebalance consumes significantly more CPU resources compared to file transfer rebalance. This is because the indexer process needs to rebuild all the mutations streamed from the data service, which is a computationally intensive process. In contrast, file transfer rebalance has very less CPU consumption with occasional spikes in CPU usage during the catchup phase after the data transfer.
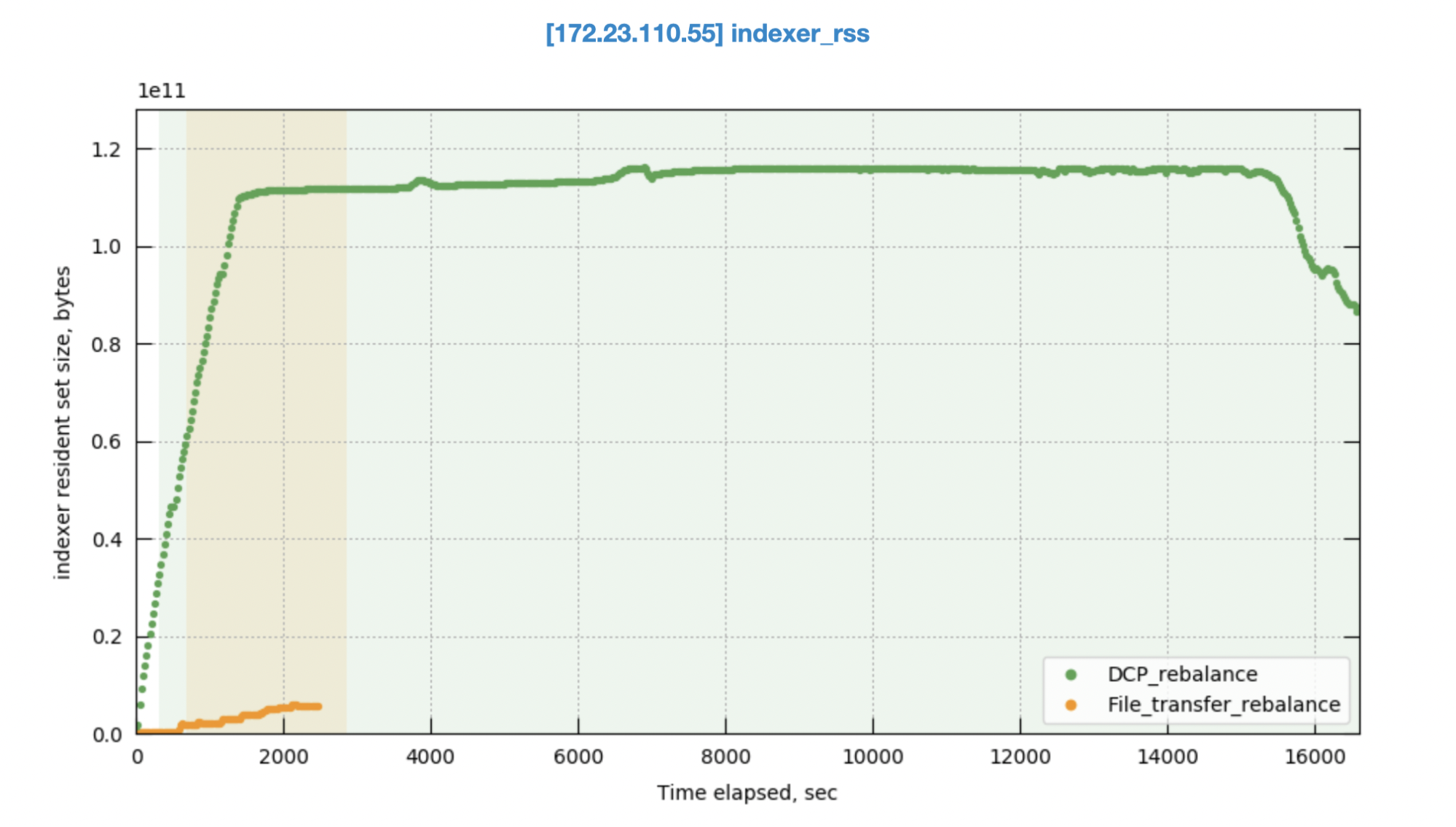
Rebalance memory comparison
DCP rebalance also demands much more memory compared to file transfer rebalance. During the rebuild process, the indexer process needs to constantly allocate and manage memory for all the incoming mutations, leading to significant strain on available resources. However, file transfer rebalance operates differently. Since it directly transfers data files to disk instead of rebuilding everything in memory, it only requires minimal memory for processing, significantly reducing overall memory demands.
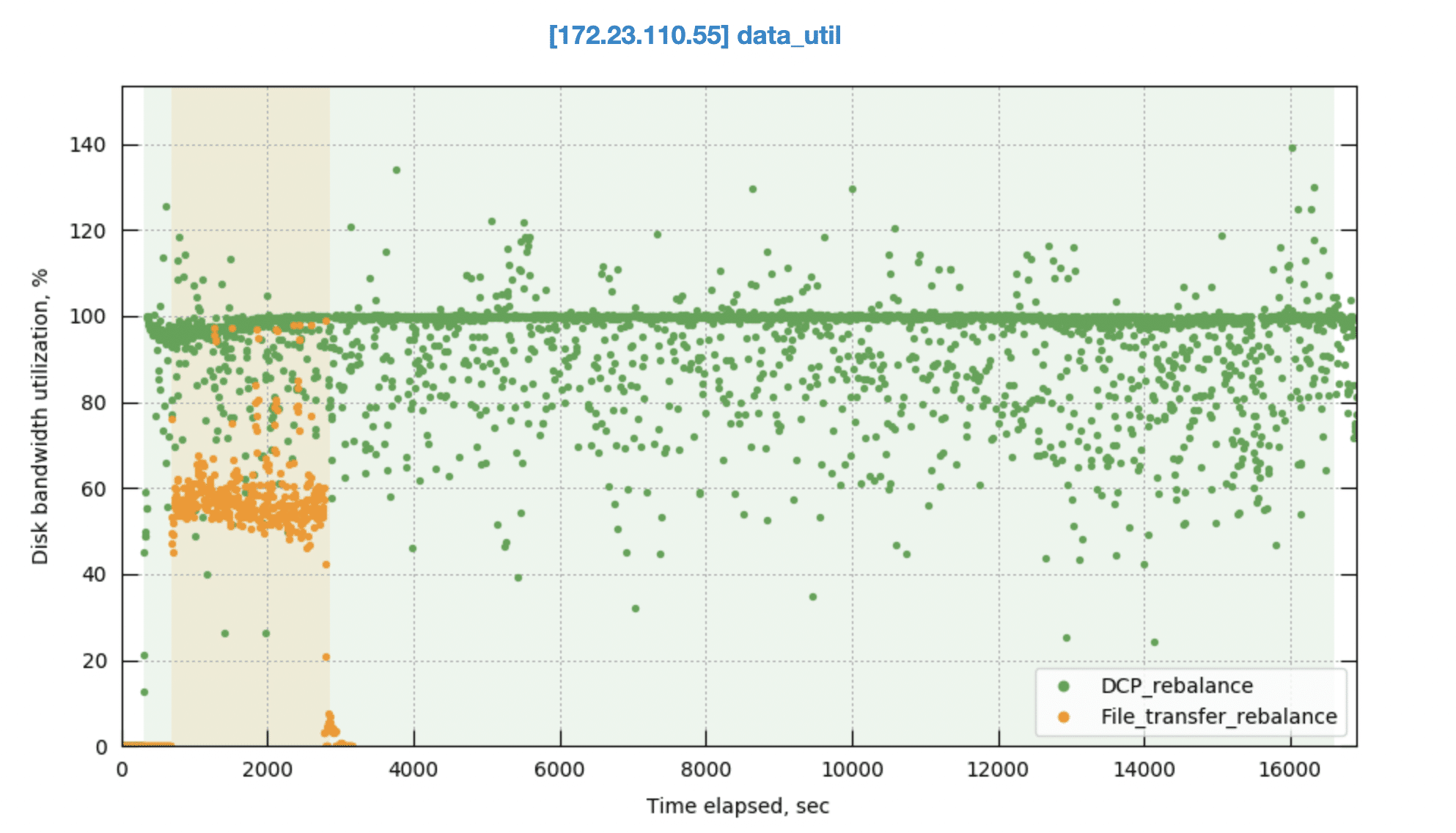
Rebalance time disk I/O utilization
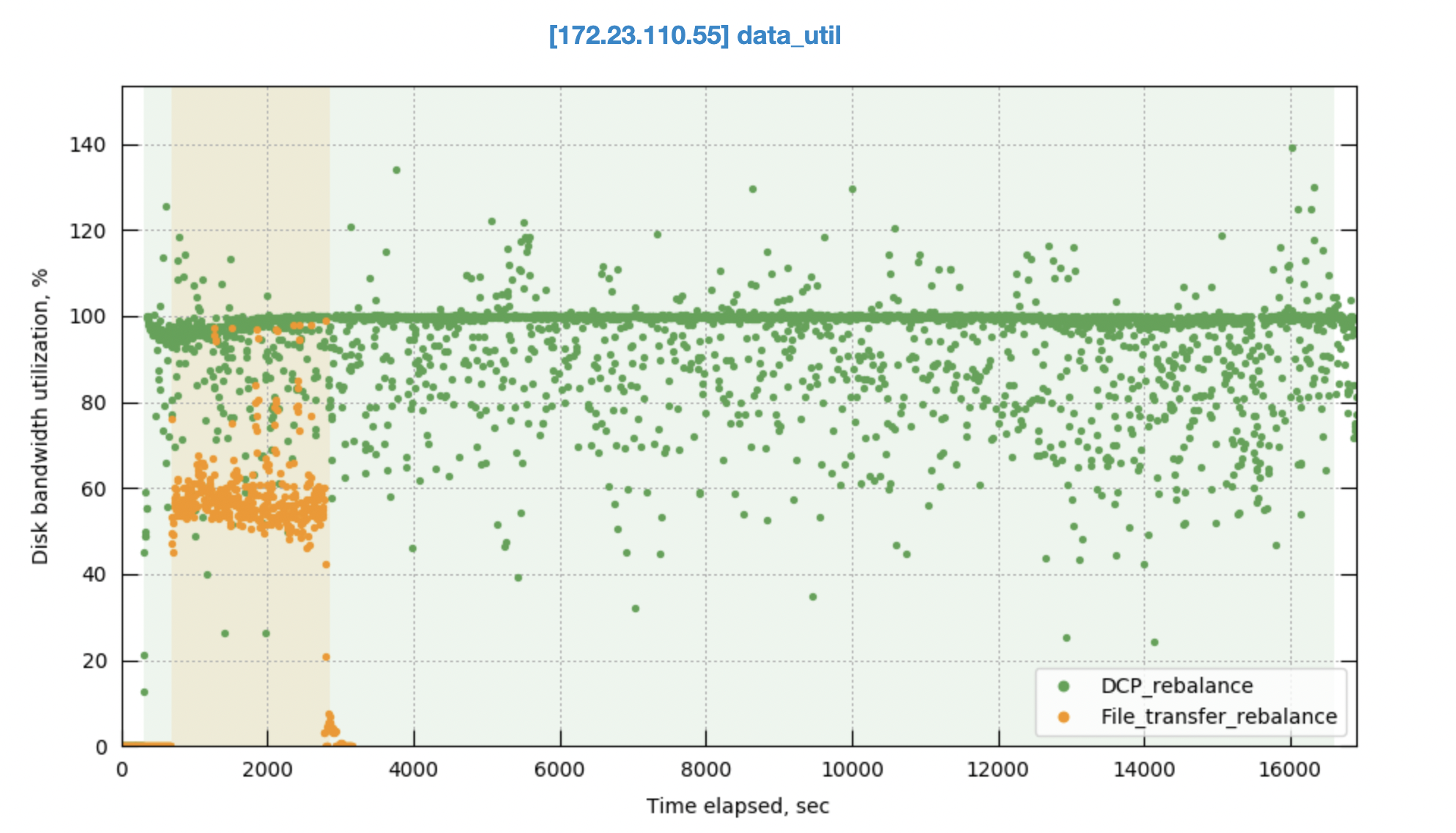
File transfer rebalance maintains a steady disk I/O rate throughout the process, thanks to the controlled transfer speed. This throttling ensures balanced efficiency and minimizes performance impact. Occasional spikes might occur during the catchup phase where mutations are processed, but overall, disk I/O remains stable. In contrast, DCP rebalance suffers from near-constant disk I/O saturation due to its rebuild-heavy approach, potentially leading to performance bottlenecks.
Rebalance transfer bandwidth on source node
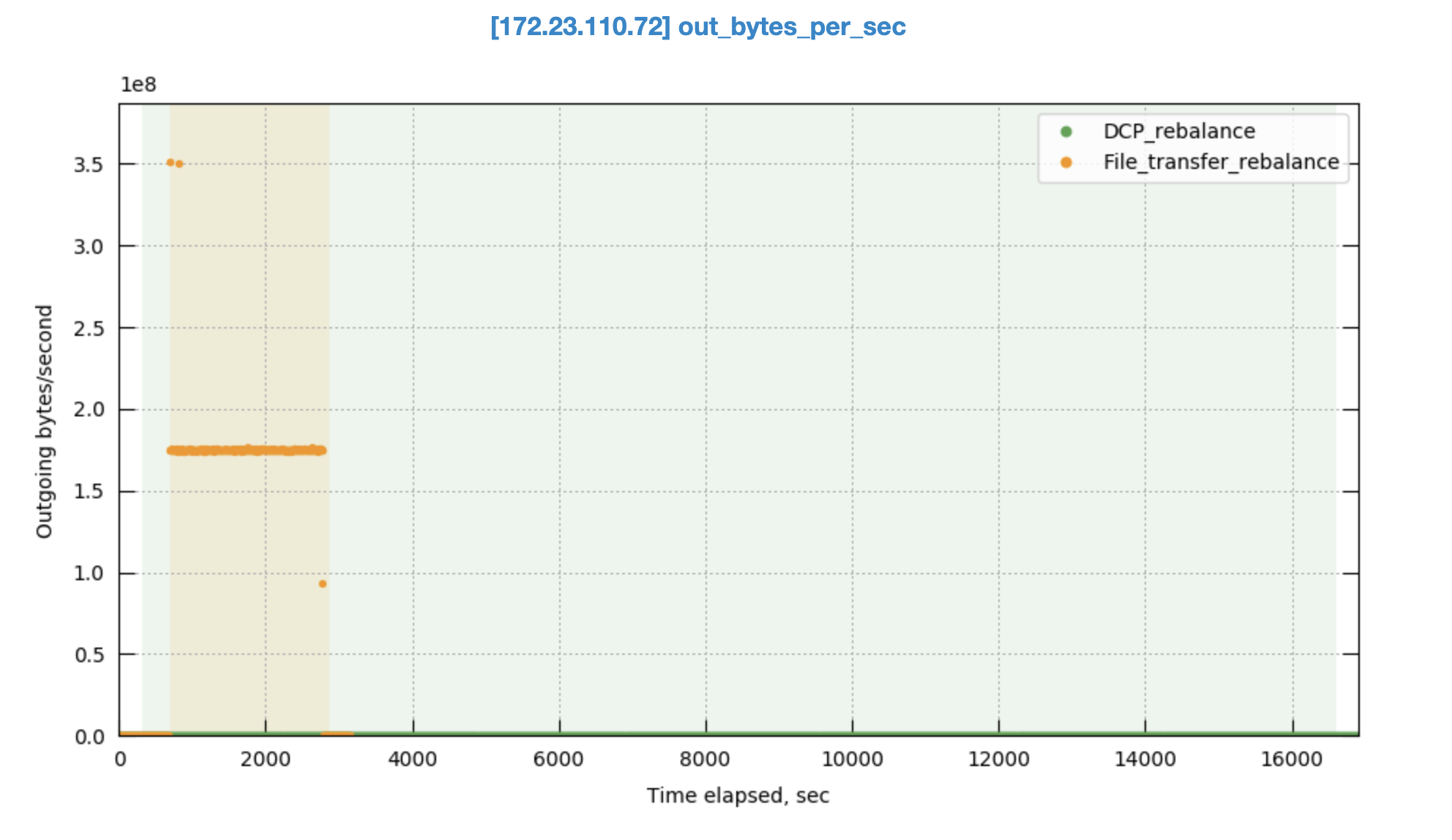
While DCP leverages a pull approach where target nodes retrieve data directly, file transfer relies on the source node actively pushing data outwards. This results in a markedly higher out_bytes_per_second metric (data pushed out) for the source node during file transfer rebalance. In DCP rebalance, this metric dips close to zero if no scans are actively running, as data pulls only occur on demand.
Other rebalance time comparisons
We previously discussed the impressive time savings achieved during rebalance swap operations (moving data directly between nodes being added and removed). We’re happy to report similar gains for two other scenarios: rebalance-in (adding new index nodes and redistributing indexes to them) and rebalance-out (removing index nodes and redistributing their indexes to remaining nodes). The table below summarizes the overall rebalance time improvements observed in a setup similar to the one described earlier.
| Rebalance type | DCP rebalance time (min) | File transfer rebalance time (min) |
| Rebalance-in (2 nodes → 3 nodes) | 123.6 min | 12.3 min |
| Rebalance-out (3 nodes → 2 nodes) | 144.7 min | 36.3 min |
Enabling file transfer rebalance
File transfer rebalance is enabled by default on Capella deployments. For self-hosted deployments, it has to be manually enabled by the end user (either from the UI or using command line requests). More details are available in the rebalancing documentation.
Summary
The traditional Couchbase Index Service rebalance method suffers from high resource usage and long rebalance times due to index rebuilding. The new file transfer rebalance tackles this problem by directly transferring data files between nodes, significantly reducing resource overhead (CPU, memory, disk I/O) and rebalance times. The index rebalance times have improved by up to 7 times in some cases, like rebalance swap. This translates to faster scaling, improved application performance, and more efficient cluster resource utilization.
- Read about more Couchbase Server 7.6 new features.
Deja un comentario
Lo siento, debes estar conectado para publicar un comentario.