Author
-

Speed, Context, and Savings: Mastering Caching in the Capella AI Model Service
In the rapidly evolving landscape of generative AI, organizations face a persistent “triple threat”: high latency, unpredictable costs, and the loss of conversational context. Every redundant call to a large language model (LLM) is…
-
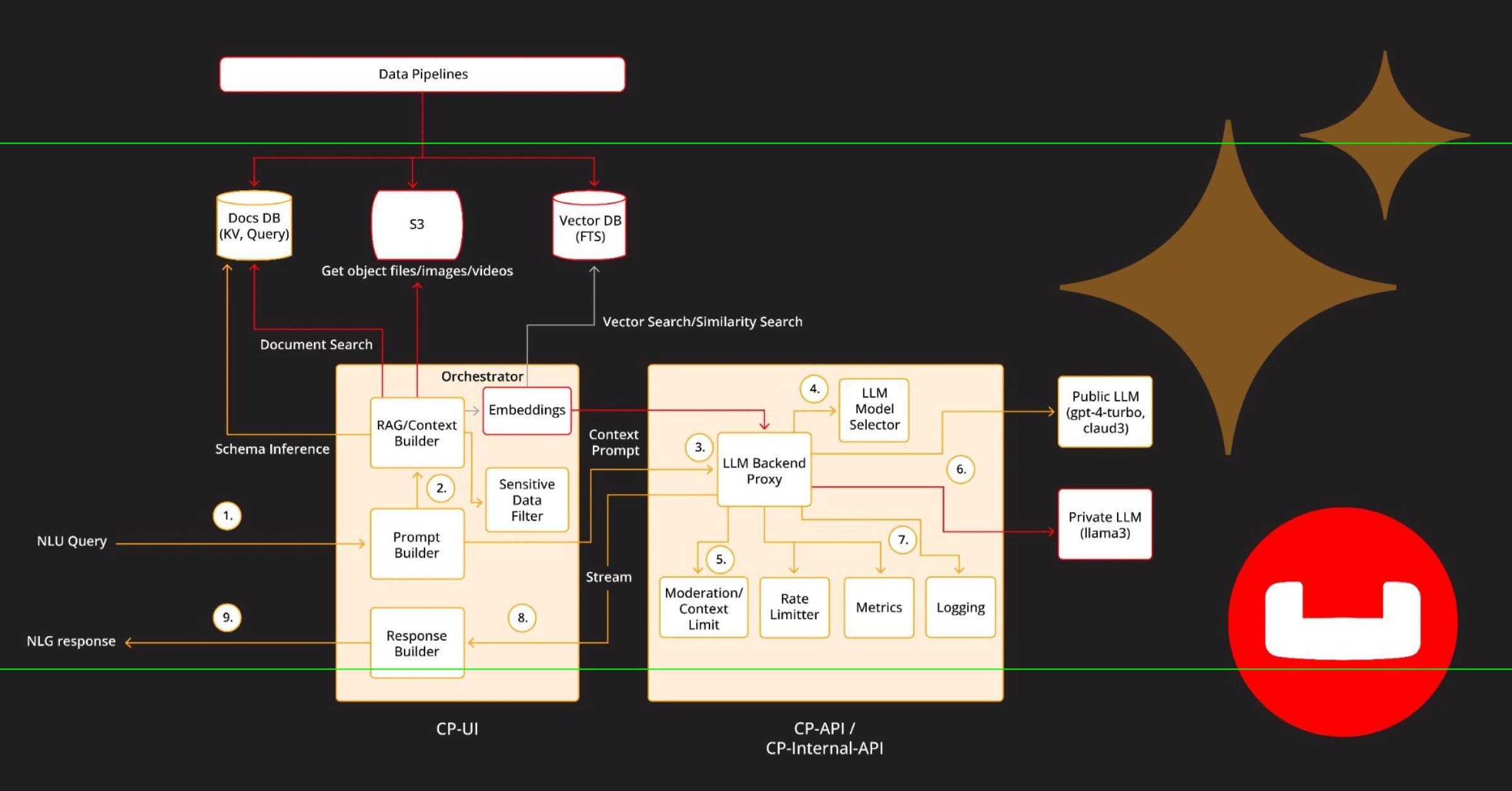
Building Gen AI Applications with Couchbase Capella
Capella iQ reference architecture In the rapidly evolving landscape of Artificial Intelligence (AI), the integration of advanced database solutions with generative AI models represents a significant stride forward. This blog presents the architecture of…
-

How to Update Python 2 to Python 3 & The Differences Between Them
Introduction The last major Python upgrade — to version 3 — arrived in Dec. 2008, nearly 12 years ago. And yet there is a good chance that you are still working on the Python…