Dear all,
I’m investigating on how can I set up the best configuration for a 4 node cluster, running Enterprise Edition.
We have just 1 bucket and the query we run are always similar; practically, we know the queries will always hit an index.
Moreover, we upsert the documents only 1 time per day in the morning (we update almost the entire bucket), and for the rest of the time we can consider to have only Read operations.
Said that, knowing we can split between Query / Index / Data service on each node, can anybody suggest me how to balance services between nodes?
In a few words, is it better to have:
- each node with Q/I/D services
- some node with just Index and/or Query service?
The following question would be: is it a good practice to replicate the GSI(s) on every machine running the Index service to improve performances?
Any hint would be very appreciated, thank you for your support
Best regards,
Stefano
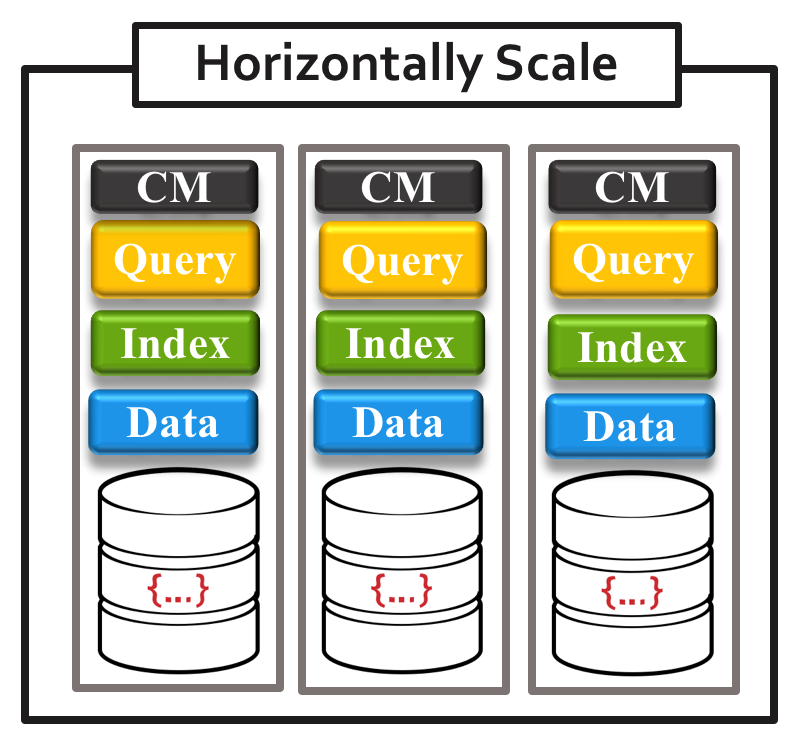
The good thing is that with Couchbase EE you can do work load isolation per node. So before you add a node into the cluster you can specify the service(s) you want to run on the machine.
So in the beginning most people do something like the below and have all there services running on one cluster.
Then as they needs grow for both performance and HA they eventually have a cluster that looks like this.
I think your sorta in the middle between the two.
So you could do 3 data nodes (HA on data) and 1 or 2 node(s) for Query index & Index (better performance on Query/Index). Its more dependent on the total number of indexes you have.
1 Like
Thank you @househippo,
I thought having Query Indexes / Indexes on each node was better for performances
I’ll try with 3 data + 1 query/index as a very first attempt 
Have a nice day!
Stefano
Dear @househippo,
About .NET SDK connection, is it ok to list each node (with no cares about the services installed on them) during the ClusterHelper.Initialize method?
Thank you,
Stefano
Adding the list of nodes is a good practice to follow because CB nodes can go down. You want a list of nodes so that if and when the app also is rebooted it can go to any of nodes in the cluster to auth and get cluster topography.