We updated our .NET application with the latest SDK (2.5.0) and we switched to the TAD paradigm.
I think we correctly followed the guidelines on async / await, but we are experiencing some unexpected behaviours in using UpsertAsync() method.
In short, this is our implementation:
public async Task<IDocumentResult<ICouchBaseCatalogEntity>[]> UpsertCatalogEntitiesBulk(List<ICouchBaseCatalogEntity> list)
{
List<IDocument<ICouchBaseCatalogEntity>> data = new List<IDocument<ICouchBaseCatalogEntity>>();
foreach (ICouchBaseCatalogEntity o in list)
{
data.Add(new Document<ICouchBaseCatalogEntity>()
{
Id = o.ID,
Content = o
});
}
var result = await this.Context.UpsertAsync<ICouchBaseCatalogEntity>(data);
//var result = await this.Context.UpsertAsync<ICouchBaseCatalogEntity>(data, ReplicateTo.Three, PersistTo.Three);
return result;
}
Once the execution flows after the await operation (so, we are at the “return result” exit line), we notice in Couchbase we have only around 1/3 of the documents upserted. In our case, the data collection contains around 70k documents and the bucket is filled up only with 23k docs.
We tried with using overloads with ReplicateTo, PersistTo parameters to no avail. Note we have a 4-nodes cluster, with 3 nodes running the data service and 1 running Index+Query service.
I may be completely out of my mind, but it seems that we are upserting 1/3 of the total data because we have 3 Data nodes.
How can we fix this issue? Feel free to ask me anything about the cluster configuration.
Edit:
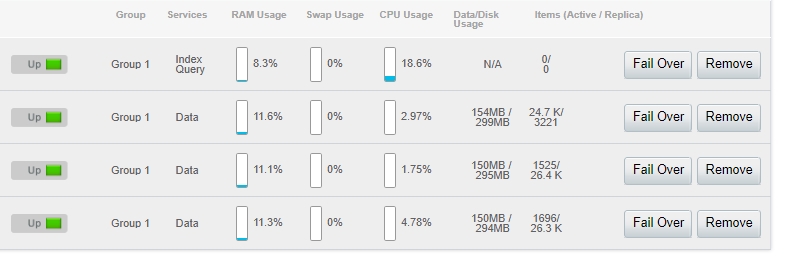
This is the dashboard status after upserting 70201 docs. As you can see, except for the first node (Index+Query services) we have an unexpected distribution of documents for the 3 Data-serviced nodes.
You can iterate through the result array and check each IDocumentResult<ICouchbaseCatalogEntity> for the Status, Success and Exception fields, you should see what is happening for each individual operation. That should help determine what is happening to the (assumed) failed operations.
I did some tests both on application side and server side, so I’m splitting my comment in steps to be as clear as possible.
STEP 1
I re-configured our bucket to only 2 nodes: one for DATA and one for INDEX+QUERY. Moreover, I changed my console application not use use ASYNC keywords but waiting for task.Result in this way:
var task = this.Context.UpsertAsync<ICouchBaseCatalogEntity>(data);
IDocumentResult<ICouchBaseCatalogEntity>[] result = task.Result;
With this configuration, with just 1 node for DATA, the application uploads all the 70k documents, so it’s correct! Moreover, the upsert is really FAST and, obviously, I have a Success status on each of the 70k IDocumentResult.
As a result, in the admin panel I’m seeing for the DATA node 70k active items (and 0 replicas, obviously).
STEP 2
After that, I added the other 2 DATA-nodes again. Note that I switched off Replica for the desired bucket.
So, at this point I have 3-DATA-nodes with replica switched off.
After rebalancing the documents have been sharded across the 3 nodes (approx 26k each active itmes, 0 replica items).
I flushed the bucket in order to re-run the application ensuring the 70k documents will be uploaded from scratch.
I run the console application again with this server configuration and the problem is facing again: only 23.5k item count; all 23.5k documents on the first node, the other 2 nodes are empty
Moreover, the same console application used in STEP 1 never reaches the end, I can’t even get IDocumentResult because it is stuck on the UpsertAsync command.
Where is the real problem here, in the SDK or is it the server configuration?
Also, do you use any virtualisation for your cluster nodes? Maybe it works with a single node because it’s reachable, but has trouble communicating with the other nodes? Enabling logging in the client will help diagnose connectivity issues.
We may have an incorrect network setup between nodes.
Running the same console application as for STEP 1 from another machine seems to work flawlessly.
We will investigate on it.
Anyway, it may be nice to have some evidence of failure in the upsert operations from the UpsertAsync() method in those cases, if possible
Good to hear you’ve found the issue. This page describes what ports are required to run Couchbase, including internal ports the cluster uses and external ones an application would use.
The operation should timeout once the limit had been reached and the result would indicate it was unable to communicate with the host.
This is what we find in the log, after setting up the CB logger (thank you for the hint about logging ) :
2017-09-27 16:25:42,165 [1] DEBUG Couchbase.Core.ClusterController - Trying to bootstrap with Couchbase.Configuration.Server.Providers.CarrierPublication.CarrierPublicationProvider.
2017-09-27 16:25:42,175 [1] DEBUG Couchbase.Configuration.Server.Providers.ConfigProviderBase - Getting config for bucket products
2017-09-27 16:25:42,184 [1] DEBUG Couchbase.Configuration.Server.Providers.ConfigProviderBase - Bootstrapping with XX.XX.XX.XX:11210
2017-09-27 16:25:42,197 [1] DEBUG Couchbase.IO.SharedConnectionPool`1[[Couchbase.IO.MultiplexingConnection, Couchbase.NetClient, Version=2.5.0.0, Culture=neutral, PublicKeyToken=05e9c6b5a9ec94c2]] - Trying to acquire new connection! Refs=0
2017-09-27 16:25:43,243 [1] DEBUG Couchbase.Configuration.Server.Providers.ConfigProviderBase - Bootstrapping with XX.XX.XX.XX:11210 failed.
XX.XX.XX.XX is one of the two DATA nodes I added in STEP 2, so this may be the problem causing the unwanted behaviour. Unfortunately this is a mistake of the company who provide us with the machines/nodes… We already told em to ensure ports were opened but it seems they didn’t.
Thank you for your help, I’ll keep you updated. My best regards,