Could you share your version pls? the behavior has changes in GSI from between versions on this.
There may be a few reasons ;
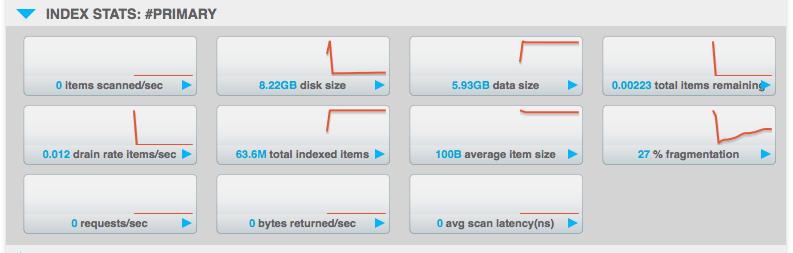
compaction may not have run yet: we have an append only write mode that favors fast sequential writes over space. a process called compaction removes the orphaned pages at an interval. To see the fragmentation ratio, you can look at the index stats for the index under the “% fragmentation” .
maintaining a tree is more expensive than raw data. index has some overhead over data due to the tree structure it maintains either with skiplist or with btree flavors. you can also see the index disk size and index data size (size of data being indexed) for the index under stats (click on bucket name under the data buckets" tab in web console. let me know if you are seeing a discrepency between the stat and what you observe on the filesystem.
thanks
-cihan
I am testing on 4.1.1-5914 Enterprise Edition (build-5914). I had to remove my Node because of disk space issue. I should have another up and running in an hour or 2. I will keep you posted on the index stats.
Thanks. I’d recommend also looking into 4.5 with circular writes.
4.0, 4.1 and 4.5 all provide append only write mode. With 4.5 we have introduced another write mode that eliminates the need for frequent compaction. The write looks for orphaned pages and reuses the space instead of appending all writes to the end of the file. It is now the new default mode when standard GSI storage mode is used.
If you have enough memory to keep your indexes in memory, I’d recommend using memory-optimized indexes as well. The IO overhead and the IO subsystem required is much less demanding when running memory optimized storage mode for indexes. All index maintenance happen in memory thus much faster for scans and index maintenance as well.
You can find the indexing options for n1ql here http://developer.couchbase.com/documentation/server/4.5/indexes/n1ql-in-couchbase.html
@steevebisson,
you definitely should use 4.5.
4.0/4.1 indexes have pretty ugly implementation, or ,“rephrasing politely”, “there a lot of really significant improvements in 4.5”. For 4.1.X take a look at GSI: different sporadic bugs + fragmentation up to 98% there are a lot of fun …