please send me examples of Custom
- Character Filter

- Tokenizer

- what is the format of the regular expression?
- How is that regular expression interpreted?
I need to do something like this
![]()
please send me examples of Custom
I need to do something like this
![]()
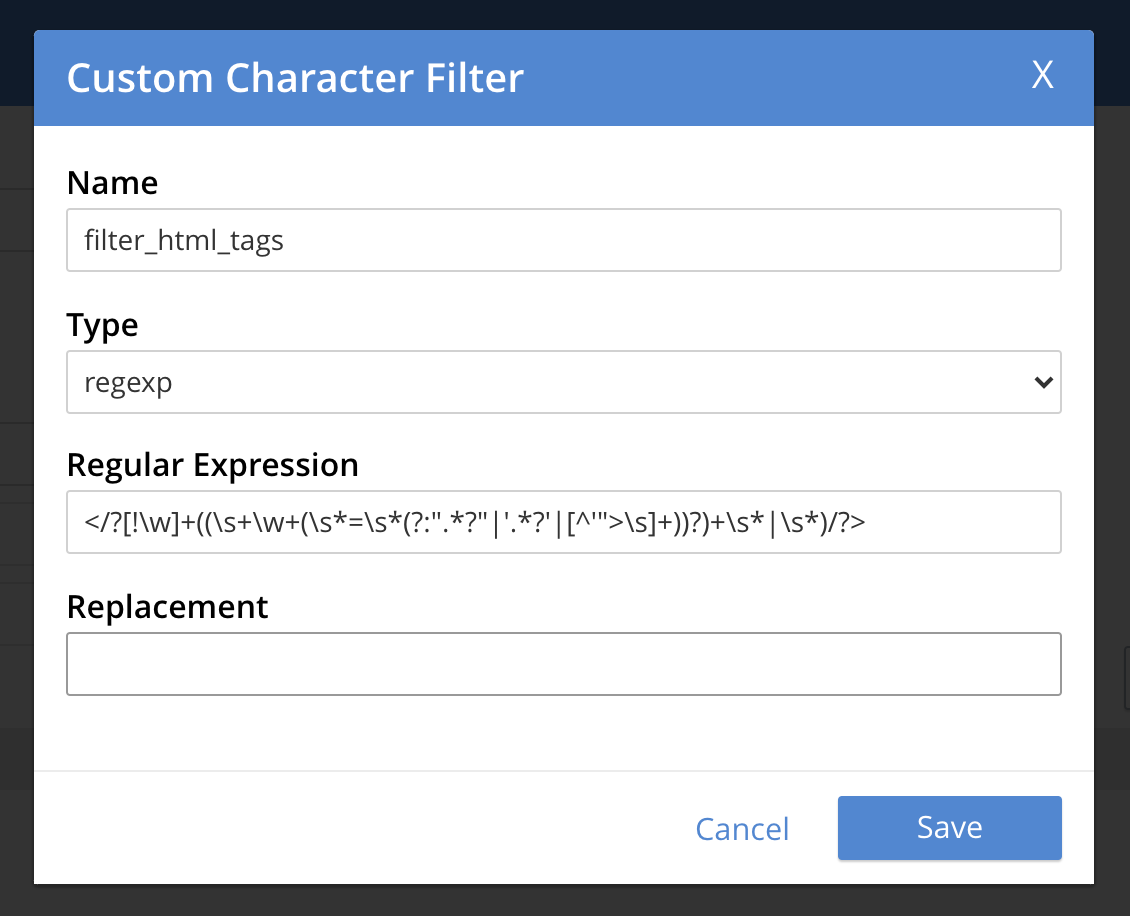
Character filters help one filter out/replace undesired or irrelevant characters from the input stream of character/data bytes.
Regexp-based character filters help users to perform these character matching/replacements efficiently.
For instance, if one wishes to filter out html tags and replace it with a space character from the source document field text, he could set up a character filter like below.
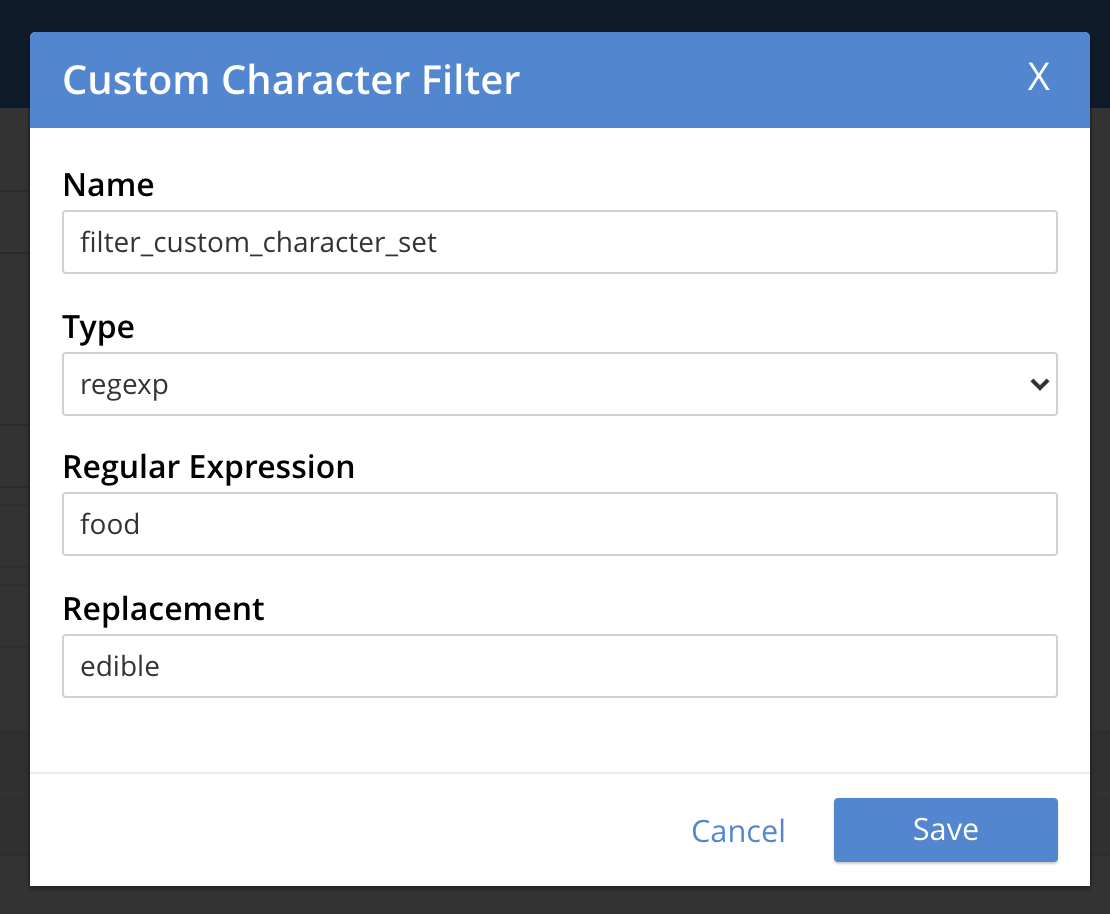
Another sample would be, let’s say if the user wants to replace every occurrence of the token “food” in the source field value with another replacement text like “edible” then he could set up another character filter like below.
Regexp-based tokenisers help users to filter out only the tokens which match the given regular expression.
For instance, if the user wish to tokenize only the domain part of an email address field then they could try something like below.
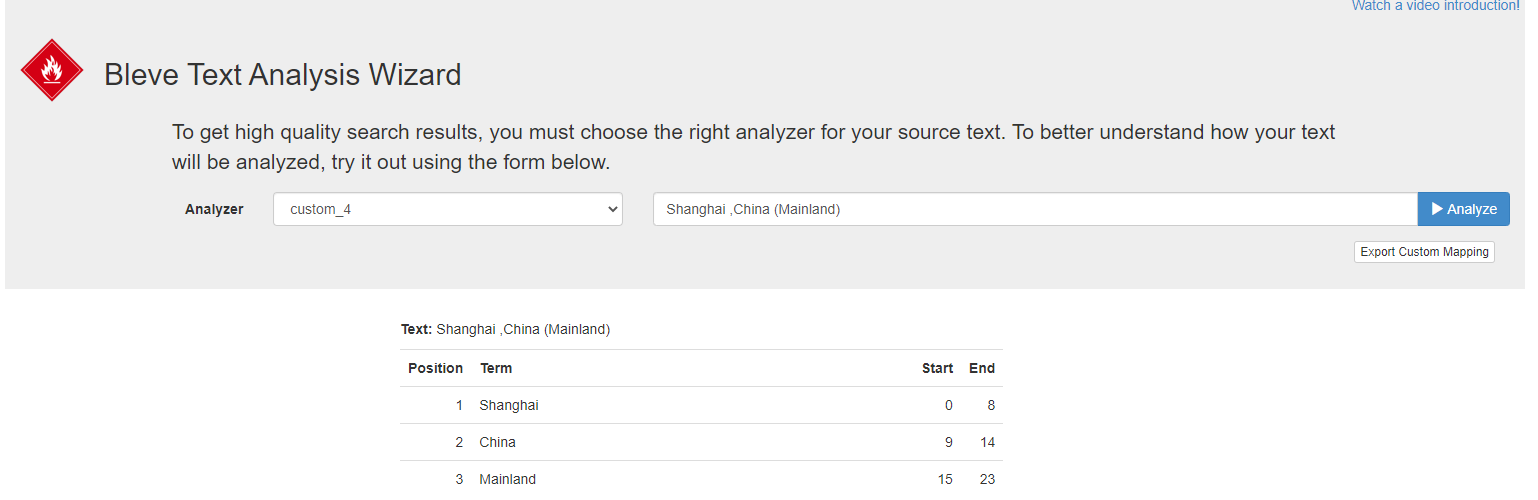
You may explore creating toy analyzers and then outputs with sample texts here - http://bleveanalysis.couchbase.com/
Now, coming back to your example for token_seperators, there is already a built-in tokenizer called “letter” which does something similar.
It creates tokens by breaking input text into subsets that consist of letters only: characters such as punctuation marks and numbers are omitted. The creation of a token ends whenever a non-letter character is encountered. For example, the text Reqmnt: 7-element&phrase would return the following tokens: Reqmnt , element , and phrase .
Let us know if this fits your requirements.
Thk @sreeks. The format of regular expression is in format Java languaje?
https://docs.oracle.com/javase/7/docs/api/java/util/regex/Pattern.html
Couchbase FTS is implemented in golang, and this is the package we use to compile regular expressions - regexp package - regexp - pkg.go.dev
Believe it does conform to the format used in Java.

I place a blank space, and the UI eliminates it in field replace

Here if it worked
Is there any way to create the index through the API? To take the blank space in the field replace
@nelsonxx1 Looks like a UI limitation (bug) that needs fixing.
Once you’ve put together your entire index definition on the UI (and not hit “CREATE INDEX” yet), follow these steps …
"char_filters": {
"filter_typesense": {
"regexp": "[,.()/&]*",
"replace": " ",
"type": "regexp"
}
}
curl -xPUT -h "Content-type:application/json" -u <username>:<password>
http://<ip>:8094/api/index/<indexName> -d @index.json