I’ve been looking for documents on how to configure total memory allocation, unsuccessfully.
My setup is I’m running couchbase 4.0.0 inside of a docker container, provided by couchbase. I am running a single node in a cluster.
My cluster config has 2 buckets; one with 256mb of memory, the other with 128.
My cluster ramsize (–cluster-ramsize in couchbase-cli) is 512.
My index ram size is 256.
These are about all of the memory settings I can find to tweak. I’m capping the overall docker container to 2GB total RAM. Each time I load data into this image, RAM usage goes up and up and up until it pierces the ceiling, and blows up the container.
My question is simple - what math should I use to configure total cluster + node RAM, and to keep it below a given ceiling that I can afford to allocate? How can I keep the cluster from growing without bound?
For data service, cluster wide RAM quota restrict how much RAM can be allocated for data service for all buckets. So in your case, one bucket is 256MB, the other bucket is 128MB. It’s smaller than 512MB. So it should be fine.
Index RAM is 256MB. This restricts how much RAM can be given for indexer.
Questions:
Do you have query service running in this node?
Can you please give us a screenshot when you see RAM usage grows out of bound? Which bucket do you see this error and how many documents?
Worth noting is that if I watch the couchbase console while all of this is happening, none of my RAM limits seem approached at all. So total cluster memory usually has a lot unallocated, and buckets individually too look like they’re not pegging their upper limit. Which makes me wonder where all of this memory is going…so far I can only conclude it’s going to somewhere that I can’t configure or don’t know about?
RE: “How many documents” – I start the cluster, I begin a data loading process that loads quite a bit in quite quickly, that’s when the memory is continually growing. How many documents before it blows up? Perhaps about 13,000.
Thank you for the detailed stat and these are very helpful.
Can you please do a top command on this machine?
I’m interested to see the memory usage breakdown between indexer, cbq-engine, memcached, beam.smp, goxdcr etc.
Just some clarification, RAM quota means how much RAM these processes will use to store data but these processes itself may take up memory. And yes, unfortunately, we don’t have a setting to set RAM quota for cbq today.
Check the docs, but IIRC the minimum memory requirement is ~8GB or so. That includes various fixed size overheads on top of the various quotas (Data Server, Index server). The growth shouldn’t be unbounded, but I think the various fixed overheads are too large for the small quota you are giving the container.
For example, the cluster manager (ns_server, shows as beam/smp in ps) doesn’t have an explicit quota, but typically uses up to 1GB, depending on how many buckets / nodes are configured.
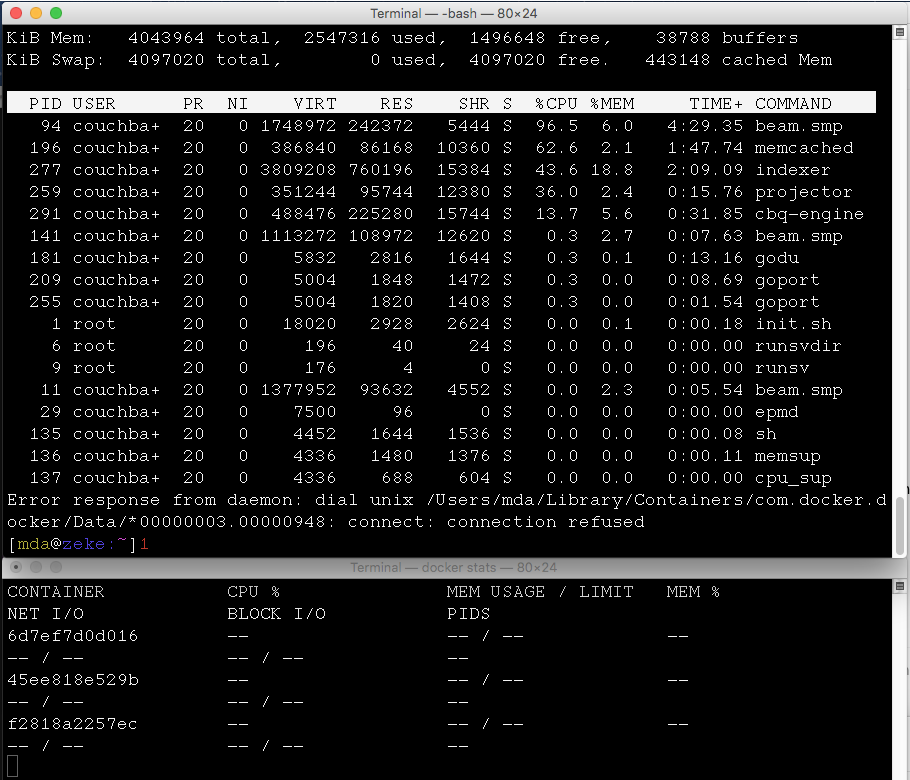
Here are some screenshots the moment before it blows up, and the moment after, showing that I lose my connection to the shell session inside of the container, and docker stats go blank because all of the containers stopped. I put docker stats there so you can see overall across everything that’s in docker-compose at the same moment.
Top just before the blow-up will hopefully provide something useful?
Do you have a doc link? I’ve been reading everything I can find about couchbase memory management, and I haven’t seen an 8GB limit anywhere. That seems a bit high to me; good modern laptops have 16GB of RAM and if 8GB were a practical lower limit that would make it pretty difficult to run couchbase most places in development.
For components of the architecture that don’t have an explicit quota, will they play nice by docker limits? If you containerize couchbase and set the container to have a limit of some certain number of GB, will it live with that, or simply grow until it can’t malloc and then fail?
Yes, on that bucket I have about 2 dozen n1ql indexes. Most are built via Ottoman, which issues a bunch of n1ql CREATE INDEX statements (deferred build) followed by a later BUILD INDEX query.
Here again I’d have a question about allocation – above in my config I clearly capped index RAM, how then does it grow to 760MB? Do I misunderstand what the index RAM configuration item is about, or is couchbase not actually respecting it?
It should respect the limit. It’s possible you’re hitting this issue: Loading... - there’s some suggestions of how to alleviate the problem. If that doesn’t work / it seems to be something different can you raise an issue for this via http://issues.couchbase.com ?
Hi @drigby I cannot unfortunately follow either path you recommend. The settings on the JIRA ticket that were suggested as a tweak aren’t possible, or maybe apply to a different version? When I curl the URL for the settings, I do not see the recommended ones present and when I POST updates to the settings as recommended, and then re-GET the URL, the newly posted params do not show up, suggesting they’re not accepted. Even going through with my DB load afterwards, the same problem persists.
How can I obtain an invite to the couchbase JIRA so that I can report this as an issue? I cannot log in there to report this further.
I also pulled this when the issue occurs – graph stops updating naturally when the node crashes.
This looks to me like the indexer can’t keep up. Note at the bottom consistent growth in the indexer as I push in lots of data quite quickly. 80%+ fragmentation in the index seems…not so great.
4.0 branch is not good with N1QL. There are too many significant changes between 4.0/4.1 and 4.5, so if you use N1QL with 4.0 CE, you better try to build 4.5 CE from source.
And finally, if you still decided to stay with 4.0 + N1QL, then you should know about this: Loading...
Most of reply-posters here are devs/devadvs and they are really trying to help you, but they are tied with their positions while answering “complex” questions.