@btburnett3 and @jmorris
Thanks for your help!
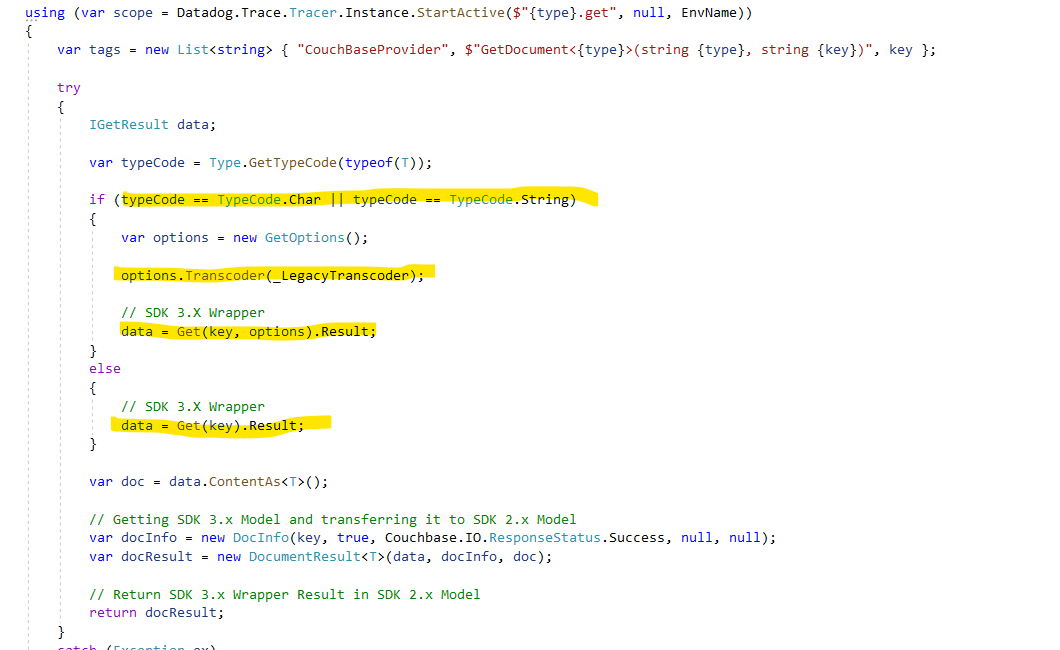
I think I got it figured out on what to do, this so far seems to be working.