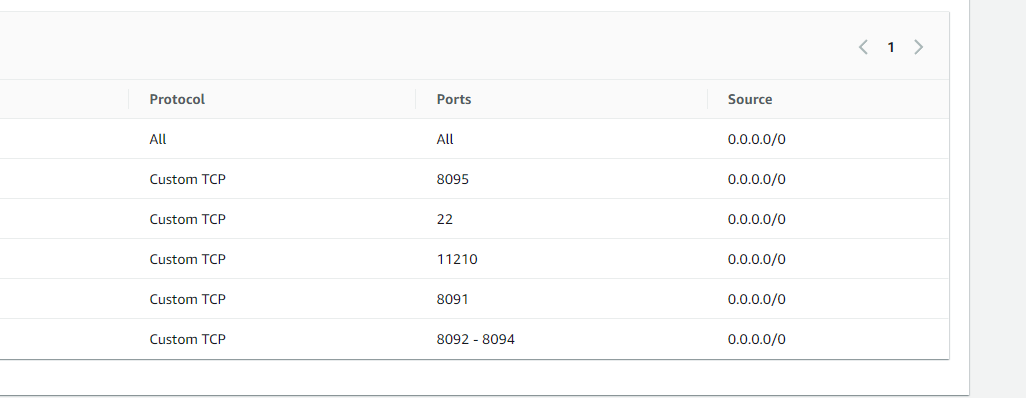
They all eventually succeed, the problem is request time to couchbase it can take longer than a minute with a simple SELECT query. And in that case, the API Gateway will fail with a timeout response
Logs from SDK-Doctor:
19:21:33.010 INFO ▶ Parsing connection string `couchbase://HOST/BUCKET`
19:21:33.010 INFO ▶ Connection string identifies the following CCCP endpoints:
19:21:33.010 INFO ▶ 1. HOST:11210
19:21:33.010 INFO ▶ Connection string identifies the following HTTP endpoints:
19:21:33.010 INFO ▶ 1. HOST:8091
19:21:33.010 INFO ▶ Connection string specifies bucket `BUCKET`
19:21:33.010 WARN ▶ Your connection string specifies only a single host. You should consider adding additional static nodes from your cluster to this list to improve your applications fault-tolerance
19:21:33.010 INFO ▶ Performing DNS lookup for host `HOST`
19:21:33.010 INFO ▶ Attempting to connect to cluster via CCCP
19:21:33.010 INFO ▶ Attempting to fetch config via cccp from `HOST:11210`
19:21:33.018 INFO ▶ Selected the following network type: default
19:21:33.018 INFO ▶ Identified the following nodes:
19:21:33.018 INFO ▶ [0] HOST
19:21:33.018 INFO ▶ indexHttp: 9102, indexStreamCatchup: 9104, indexStreamInit: 9103
19:21:33.018 INFO ▶ kv: 11210, mgmt: 8091, n1ql: 8093
19:21:33.018 INFO ▶ capi: 8092, fts: 8094, ftsGRPC: 9130
19:21:33.018 INFO ▶ indexAdmin: 9100, indexScan: 9101, indexStreamMaint: 9105
19:21:33.018 INFO ▶ projector: 9999
19:21:33.018 INFO ▶ Fetching config from `http://HOST:8091`
19:21:33.026 INFO ▶ Received cluster configuration, nodes list:
[
{
"addressFamily": "inet",
"addressFamilyOnly": false,
"clusterCompatibility": 458753,
"clusterMembership": "active",
"configuredHostname": "127.0.0.1:8091",
"couchApiBase": "http://HOST:8092/",
"cpuCount": 2,
"externalListeners": [
{
"afamily": "inet",
"nodeEncryption": false
}
],
"hostname": "HOST:8091",
"interestingStats": {
"cmd_get": 0,
"couch_docs_actual_disk_size": 10066127,
"couch_docs_data_size": 142759,
"couch_spatial_data_size": 0,
"couch_spatial_disk_size": 0,
"couch_views_actual_disk_size": 0,
"couch_views_data_size": 0,
"curr_items": 50,
"curr_items_tot": 50,
"ep_bg_fetched": 0,
"get_hits": 0,
"index_data_size": 166785,
"index_disk_size": 3702784,
"mem_used": 19090064,
"ops": 0,
"vb_active_num_non_resident": 0,
"vb_replica_curr_items": 0
},
"mcdMemoryAllocated": 6357,
"mcdMemoryReserved": 6357,
"memoryFree": 7498797056,
"memoryTotal": 8333029376,
"nodeEncryption": false,
"nodeHash": 121769150,
"nodeUUID": "ac79d98f916c4fda5362a23ba51aaef5",
"os": "x86_64-pc-linux-gnu",
"otpNode": "ns_1@127.0.0.1",
"ports": {
"direct": 11210,
"distTCP": 21100,
"distTLS": 21150
},
"recoveryType": "none",
"services": [
"fts",
"index",
"kv",
"n1ql"
],
"status": "healthy",
"systemStats": {
"allocstall": 0,
"cpu_cores_available": 2,
"cpu_stolen_rate": 0.2023267577137076,
"cpu_utilization_rate": 2.470126375046816,
"mem_free": 7498797056,
"mem_limit": 8333029376,
"mem_total": 8333029376,
"swap_total": 0,
"swap_used": 0
},
"thisNode": true,
"uptime": "274458",
"version": "7.1.1-3175-community"
}
]
19:21:33.031 INFO ▶ Successfully connected to Key Value service at `HOST:11210`
19:21:33.086 INFO ▶ Successfully connected to Management service at `HOST:8091`
19:21:33.090 INFO ▶ Successfully connected to Views service at `HOST:8092`
19:21:33.093 INFO ▶ Successfully connected to Query service at `HOST:8093`
19:21:33.096 INFO ▶ Successfully connected to Search service at `HOST:8094`
19:21:33.096 WARN ▶ Could not test Analytics service on `HOST` as it was not in the config
19:21:33.111 INFO ▶ Memd Nop Pinged `HOST:11210` 10 times, 0 errors, 0ms min, 1ms max, 1ms mean
Tried to use 3.4.6 version and the issue still occurred.