So, I did XDCR, this is the “before” cluster with 10 nodes, it also had 150G in metadata and 550G of data in ram, cluster size is about 900G, 0 cache miss ratio 0 reads from disk
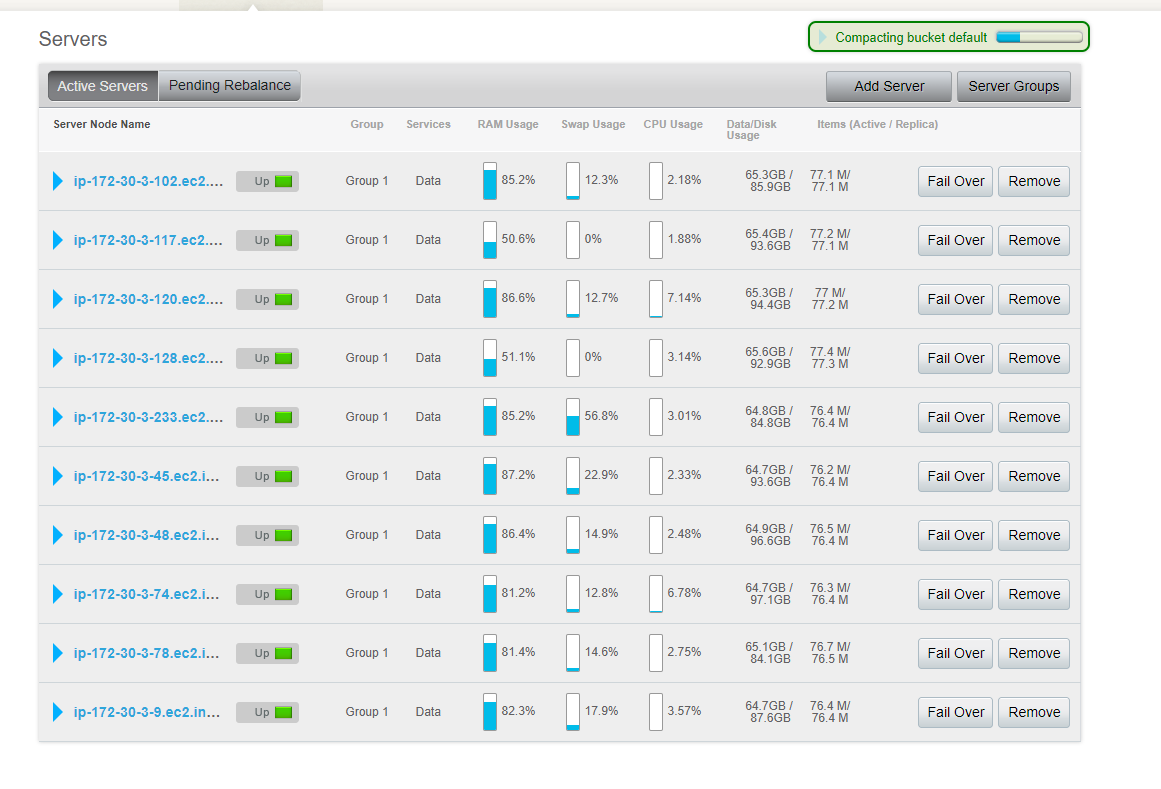
this is the “after” 150G metadata 450G in data ram, cluster size is the same, 0 cache miss rarion 0 reads from disk,
the ram didn’t exceed the 70G that it was allocated during the XDCR as expected, now this is an healty cluster I hope and expected next time i rebalance it the ram will not be affect and allow smooth process.
