We have a cluster with 4 data nodes, 4 query nodes, and 5 index nodes. When I submit a high volume of N1QL queries using the Java SDK, the CPU usage on one of my query nodes is very high while the others are nearly idle. It would seem that queries aren’t be load balanced.
Are there any specific things that need to be done to get this to work or is there something else going on here?
In this case we’re running 1000’s of N1QL queries per second. The host in question is only running the query service as are 3 other hosts in the cluster. The high one is >90% CPU usage while the others are <10%. When we stop running our test all hosts are idle.
If this is not expected behavior I will open a support ticket.
Yes, please do open a support ticket, the expected behavior is that the request be spread out to query nodes evenly. even if some can use up more CPU than others, 90% CPU vs 10% CPU seems like a pretty unbalanced ratio.
@tcoates one other thing I’d like you to investigate is the number of n1ql queries/s broken down per node, you can drill down on the metric in the UI. The reason I’m asking because CPU usage might be because of a different reason not related to the query distribution itself.
Can you check how many queries/s are executed against which node? Also, are you executing the same query over and over again or is it a mixture, also in terms of complexity?
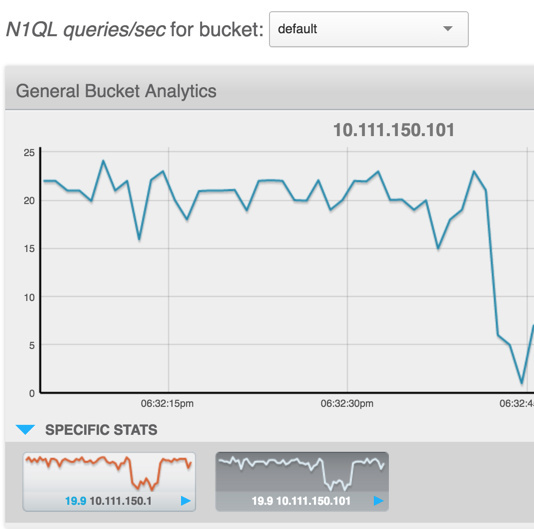
I checked the breakdown of queries by server as you suggested and there is a huge imbalance even with a smaller load. The first node sees about 300 requests per second and the other only spike to about 40. I’ve attached a screen shot of the console showing this.
Are there any ideas about this? I have a different issue open with support right now and I don’t want to confuse the two so I haven’t created a second ticket yet. Is that my only course of action?
I just tried to reproduce this since I hadn’t tried in a few weeks and now things seem to be distributed properly. We did add a few additional query nodes to our cluster so perhaps that had some impact?
I wonder if this balancing problem would also increase the frequency of the timeout issue that you have reported to support. Have you seen any correlation there?
I haven’t noticed any correlation, but I haven’t been actively testing with the Java SDK for N1QL queries lately due to the timeout problem. If I see anything of interest related to the balancing and the timeouts I’ll let you know.
As you’re likely aware, the issue I was seeing with timeouts has been resolved. I’ve been testing with the verification sdk that was provided to me as part of that support ticket and I am now able to reproduce the load balancing issue again.
I used my test application (same one as for the other issue) and submitted 100k queries against my cluster in a loop waiting for each batch of 100k to return before sending the next:
you can see that the first query node in my cluster (s1tk-cbd12) has a much different pattern than the others. Looking at the actual numbers, that node averages nearly 3k query requests per second while the others only see about 1.5k.
I can reproduce this easily at this point. Are there other data points that I can capture that would make debugging this easier? Should I open a support ticket to address this instead?
the pattern is strange… the other nodes seem to display a dent that would correspond to the end of each batches, but the cbd12 node doesnt, am I interpreting this right?
do you think you’d be able to capture some traffic on that particular node, eg. limit it to traffic coming in on port 8093, and see if another component in the cluster isn’t making additional requests to that node?
@geraldss can you think of something that could explain that difference in pattern? The SDK sends queries to the nodes in the cluster in a round-robin fashion.
@tcoates do you have multiple query endpoints configured in the SDK? and you’re now on 2.3.3 right? (GA was released last week)
I’ll try to get a capture done later this afternoon when my test environment frees up again.
I did run this particular test with 20 query endpoints although I’m fairly certain I’ve seen the same behavior with the default (I think 1?) We’re running a fully non-blocking application and saw much better throughput by increasing this setting during load testing.
I’ll run a quick test without the queryEndpoint setting as well and verify that the result is similar.
First, I wanted to confirm that we’re now testing with the 2.3.3 GA version. I don’t see any behavior differences after moving away from the test version we had before.
Second, I re-ran my test with queryEndpoints=20 and with no queryEndpoints setting. With 20 endpoints, I see the same pattern as I did in the most recent screen capture - the first query node in the cluster averages about 3000 queries/sec and the others are either 1k or 1.5k/sec. These rates stay consistent and I can’t account for why they would vary to such a degree, even between the 1k and 1.5k nodes. The exact same query against an empty bucket returning an empty result set is used for every call.
The test with no queryEndpoint override had some interesting results. The overall query rate was much slower. It seemed that about half of the query nodes received about 300 queries/sec and the other half was 500-600 queries/second. The first node in the cluster was in the slow group this time.
I can run a tcpdump, but wanted to confirm what you wanted me to capture. Would you like to see what happens during a run with queryEndpoints=20 or something else?
ah, interesting thing to note with regards to query endpoints: prior to 2.3.3 (or was it 2.3.2 ), when you had multiple query endpoints they would be selected using a RandomStrategy. Now they should also be selected using a RoundRobinStrategy…
but that still doesn’t explain the pattern we see.
as for the capture, let’s go with a very short run with queryEndpoints=20. short as to not contain millions of events we’re only interested in HTTP requests going to a port 8093, so maybe you can try to limit your capture accordingly?
I did a packet capture on s1tk-cbd10 of just port 8093 while running a test. I let the test cycle through 3 batches of 100k queries before I shut it down.
One suggestion to help determine where the problem might be, if you change the application workload to emit a steady number of queries and just ignore the results (or check them on a separate thread), then we’d be assured that the load should distribute evenly.
Also, it’s entirely possible that some of the “requests” being processed are not related to this workload. Maybe there’s something internal? @vsr1 may have an idea?
Thanks for that @tcoates. The forums here don’t carry the same SLA as you receive under an Enterprise Subscription. To make sure the right folks are involved there, can you open a case at support.couchbase.com? We’re happy to help on the forums as time allows, but you’ll be able to get more oversight on this through support.



 ), when you had multiple query endpoints they would be selected using a
), when you had multiple query endpoints they would be selected using a  we’re only interested in HTTP requests going to a port 8093, so maybe you can try to limit your capture accordingly?
we’re only interested in HTTP requests going to a port 8093, so maybe you can try to limit your capture accordingly?