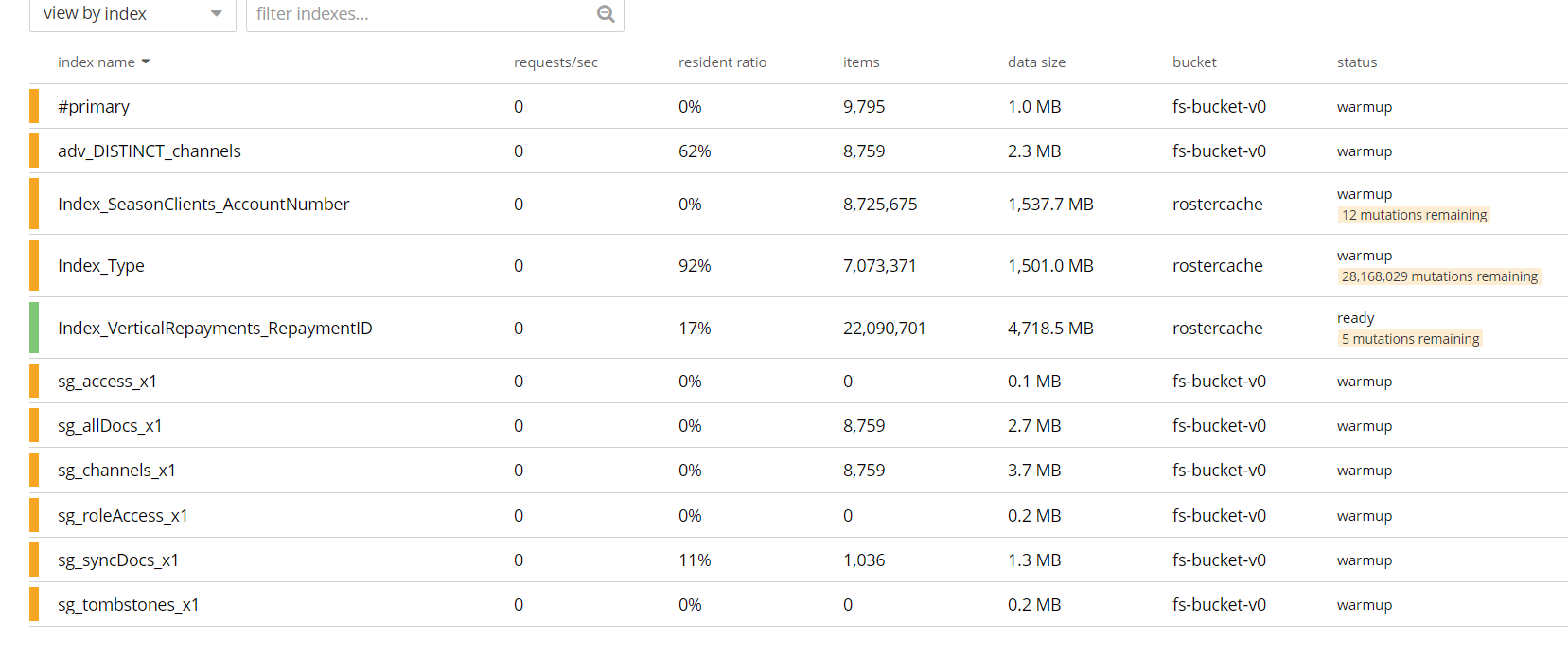
I am attempting to create GSI indexes on a bucket with 38 million items (couchbase 6.6.0 enterprise with plasma storage, hosted on the kubernetes operator version 2.1.0). Currently the cluster is setup with 2 index nodes, both of which have a guaranteed service class with 1.5 CPUs and 4 GBs RAM (with an index quota of 3275 MBs). I’m having trouble creating large indexes on the bucket - I can reliably create 1 or 2 large indexes, but if I try to create too many then almost all of the indexes across all buckets go into “warmup” state until I delete the large index. This screenshot shows the error right as it’s happening, after leaving things in this state for a few hours all the indexes went into the “warmup” state.
I’m seeing a lot of log messages during that time (while a service is attempting to query the indexes in “warmup” state):
Service 'indexer' exited with status 137. Restarting. Messages:
2021-05-05T09:10:00.074+00:00 [Info] SCAN##2 RESPONSE status:(error = Index not ready for serving queries), requestId: 44aa4324-686a-4885-8a4c-ec3bdfbcf626
2021-05-05T09:10:00.085+00:00 [Info] SCAN##3 REQUEST defnId:5791000603602569377, instId:0, index:/, type:scan, partitions:[0], span:<ud>(range (%!s(<nil>),%!s(<nil>) incl:none))</ud>, limit:9223372036854775807, requestId:44aa4324-686a-4885-8a4c-ec3bdfbcf626
2021-05-05T09:10:00.085+00:00 [Info] SCAN##3 RESPONSE status:(error = Index not ready for serving queries), requestId: 44aa4324-686a-4885-8a4c-ec3bdfbcf626
2021-05-05T09:10:18.600+00:00 [Info] ServiceMgr::GetTaskList []
2021-05-05T09:10:18.601+00:00 [Info] ServiceMgr::GetTaskList returns &{[0 0 0 0 0 0 0 1] []}
2021-05-05T09:10:18.601+00:00 [Info] ServiceMgr::GetCurrentTopology []
2021-05-05T09:10:18.601+00:00 [Info] ServiceMgr::GetCurrentTopology returns &{[0 0 0 0 0 0 0 1] [6c2e523d80b121be5fc51b8c65588f0e] true []}
2021-05-05T09:10:18.602+00:00 [Info] ServiceMgr::GetTaskList [0 0 0 0 0 0 0 1]
2021-05-05T09:10:18.602+00:00 [Info] ServiceMgr::GetCurrentTopology [0 0 0 0 0 0 0 1]
Service 'indexer' exited with status 137. Restarting. Messages:
2021-05-05T09:14:06.780+00:00 [Info] ServiceMgr::GetCurrentTopology returns &{[0 0 0 0 0 0 0 1] [6c2e523d80b121be5fc51b8c65588f0e] true []}
2021-05-05T09:14:06.781+00:00 [Info] ServiceMgr::GetTaskList []
2021-05-05T09:14:06.781+00:00 [Info] ServiceMgr::GetTaskList returns &{[0 0 0 0 0 0 0 1] []}
2021-05-05T09:14:06.782+00:00 [Info] ServiceMgr::GetCurrentTopology [0 0 0 0 0 0 0 1]
2021-05-05T09:14:06.782+00:00 [Info] ServiceMgr::GetTaskList [0 0 0 0 0 0 0 1]
2021-05-05T09:14:11.284+00:00 [Info] fs-bucket-v0/sg_allDocs_x1/Backstore#13579134874878103257:0 Plasma: Enable page eviction before reaching quota.
2021-05-05T09:14:11.284+00:00 [Info] fs-bucket-v0/sg_allDocs_x1/Mainstore#13579134874878103257:0 Plasma: Enable page eviction before reaching quota.
2021-05-05T09:14:11.389+00:00 [Info] fs-bucket-v0/sg_syncDocs_x1/Mainstore#17284487810525332057:0 Plasma: Enable page eviction before reaching quota.
2021-05-05T09:14:11.484+00:00 [Info] fs-bucket-v0/sg_syncDocs_x1/Backstore#17284487810525332057:0 Plasma: Enable page eviction before reaching quota.
Service 'indexer' exited with status 137. Restarting. Messages:
2021-05-05T09:15:16.416+00:00 [Info] PeriodicStats = {"cpu_utilization":100.16666666666667,"index_not_found_errcount":0,"indexer_state":"Warmup","memory_free":6946410496,"memory_quota":3434086400,"memory_rss":1593073664,"memory_total":33676562432,"memory_total_storage":0,"memory_used":0,"memory_used_queue":0,"memory_used_storage":0,"needs_restart":false,"num_connections":0,"num_cpu_core":8,"storage_mode":"plasma","timestamp":"1620206116416462577","timings/stats_response":"72 7724012 889244961924","uptime":"1m2.294666563s"}
2021-05-05T09:15:17.296+00:00 [Info] ServiceMgr::GetTaskList []
2021-05-05T09:15:17.296+00:00 [Info] ServiceMgr::GetTaskList returns &{[0 0 0 0 0 0 0 1] []}
2021-05-05T09:15:17.297+00:00 [Info] ServiceMgr::GetCurrentTopology []
2021-05-05T09:15:17.297+00:00 [Info] ServiceMgr::GetCurrentTopology returns &{[0 0 0 0 0 0 0 1] [6c2e523d80b121be5fc51b8c65588f0e] true []}
2021-05-05T09:15:17.297+00:00 [Info] ServiceMgr::GetTaskList [0 0 0 0 0 0 0 1]
2021-05-05T09:15:17.298+00:00 [Info] ServiceMgr::GetCurrentTopology [0 0 0 0 0 0 0 1]
Service 'indexer' exited with status 137. Restarting. Messages:
2021-05-05T09:02:13.518+00:00 [Info] rostercache/Index_Type/Backstore#5194750392116224388:0 Plasma: checkpoint recovery replayOffset:8631005184 startOffset:8087875811, endOffset:11201191936, recoverTime:1.518611296s
2021-05-05T09:02:42.670+00:00 [Info] ServiceMgr::GetCurrentTopology []
2021-05-05T09:02:42.670+00:00 [Info] ServiceMgr::GetCurrentTopology returns &{[0 0 0 0 0 0 0 1] [6c2e523d80b121be5fc51b8c65588f0e] true []}
2021-05-05T09:02:42.671+00:00 [Info] ServiceMgr::GetTaskList []
2021-05-05T09:02:42.671+00:00 [Info] ServiceMgr::GetTaskList returns &{[0 0 0 0 0 0 0 1] []}
2021-05-05T09:02:42.671+00:00 [Info] ServiceMgr::GetCurrentTopology [0 0 0 0 0 0 0 1]
2021-05-05T09:02:42.672+00:00 [Info] ServiceMgr::GetTaskList [0 0 0 0 0 0 0 1]
2021-05-05T09:03:02.108+00:00 [Info] fs-bucket-v0/sg_roleAccess_x1/Mainstore#8459312647145716814:0 Plasma: Enable page eviction before reaching quota.
2021-05-05T09:03:02.108+00:00 [Info] fs-bucket-v0/sg_roleAccess_x1/Backstore#8459312647145716814:0 Plasma: Enable page eviction before reaching quota.
I’ve enabled “full ejection” on the buckets that are having the problem, this did not help. I had assumed that GSI indexes could fit into a relatively small RAM size, is this not the case? If so, what is the minimum amount of RAM required for a GSI index? From the documentation, it seems that 256 MB should be sufficient to run GSI indexes - but in practice 4 GB per node doesn’t seem to be enough:
https://docs.couchbase.com/server/current/install/sizing-general.html#sizing-index-service-nodes
Other documentation indicates that partial indexes can help (What Is Database Indexing? – Best Practices and Examples), does this mean that a large number of small partial indexes will fit even if a single large GSI will not?