Hello,
We’ve been having every now and then this issue, which reduces the stability of our cluster a lot…
Basically, the DCP drain rate of our cluster get’s increments slowly up to 10M, which is fairly high, all connected clients send an high amount of bandwidth (~1.5MBps each), and each node in the cluster (4) also sends a lot of traffic (~4MBps each, 12 in one, which is the server seems to be having the problem).
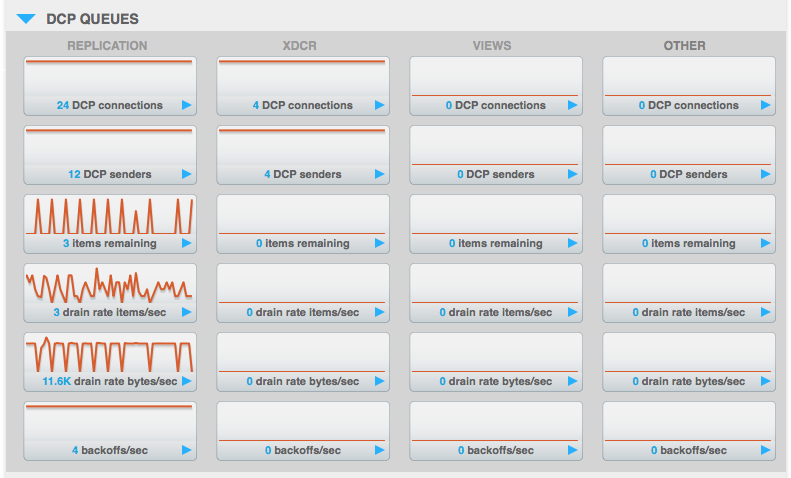
We have about 5GB of data.
Reducing the amount of replicas, reduces the constant amount of 10 to 6 for example… it looks like a bug in DCP and I don’t know how to stop it, it eventually always goes off, but it worries me since it also propagates to XDCR, which means an increased bandwidth bill.
This is a more detailed graph showing how these values evolved.

Also,
I did a rebalance yesterday morning after a planned maintenance from azure, but it shouldn’t interfere since this problem has happened at least three other times in the past.
I’m glad to say you can close this, I found the issue was at the application level!
@kshmir1 Just curious… what was the issue? Others might see the same behavior…
Sure!
We track information of users through a pixel, some visitors abused this and stored too many information. Just one pixel could make the document size go up so much that each request would make a whole lot of network time, none of our monitoring systems realized this was going on sadly.
The only indicator that showed this was an increased usage of network, and the replication rate in couchbase, just 5 or 6 documents were updated every some seconds, but we realized one of those must have been huge, we were right.
This was really hard to track, it took us some months, but thankfully it never made couchbase or our systems fail at all. We use node.js with express and the node sdk with couchbase, all hosted in azure.
1 Like
Cool, glad you tracked it down. Thanks for sharing the war story, always good to hear what people are up to.