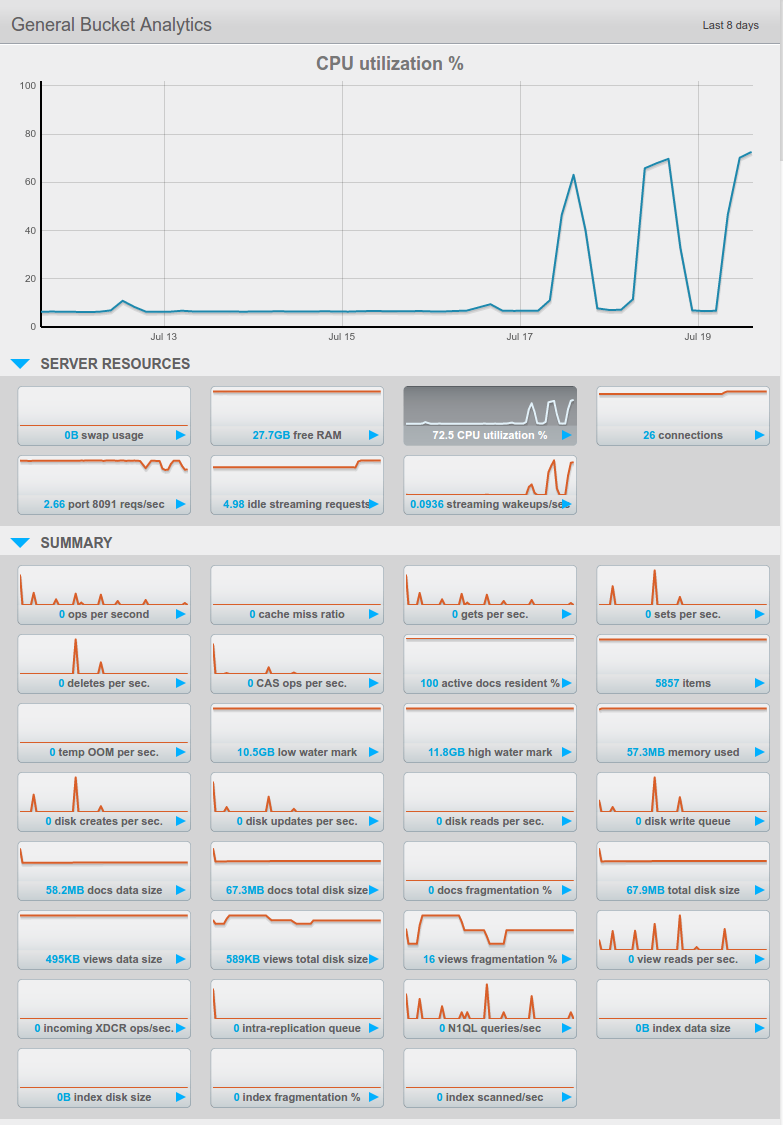
I do have a two node test-cluster running Couchbase community edition and after a few days the CPU usage (only of the second node) dramatically increases for a few hours and then drops down again. I’ve tried:
to delete the cluster and set it up again
to run it on different servers
but the problems keeps reoccurring
The cluster (as it’s test only) does store very little data volume (Data/Disk Usage 173MB / 191MB and 5902 documents)
@qicb,
There is no XDCR but there is 1 view document with 9 views and 1 index for N1QL. But none of the views is particularly complex - they are more like secondary indexes which do emit just hand full of fields.
Even though I’m aware that at least 4 cores are recommended these machines are only dual-core but that shouldn’t be any issue if there is very little load on the system, right?
The machines do have 30 GB of ram whereby 14336 MB are allocated for data and 2048 MB for index. So there should be enough spare RAM for the other processes.
@daschl the cluster is rather simple:
A simple 2 node cluster in the OVH Public Cloud with SP-30 instances (I know 3 nodes are recommended but for testing I decided to use 2 nodes)
Both servers are synchronizing their system time with an NTP server.
I’m using a private network (OVH vRack with the 10.0.0.0/24 IP range)
There is no packet loss on the network connection - the ping is stable and between 0.5 and 2.5 ms
Servers are configured using host names - DNS resolution time shouldn’t be an issue either because I’ve added all host names and IP addresses to the /etc/hosts file
The application accessing Couchbase is situated in the same vRack (so no big delays their either)
Both servers are running all services (Data, Index, Query) and yes, I’m also using N1QL
In case you have any additional questions I’m happy to answer them
I’ve updated to Couchbase Community 4.1 (which was released yesterday) - so far the CPU usage looks much better - I’ll keep an eye on it over the next few days and let you know. As you can see in the screenshot of my original post it was also working fine with 4.0 for a few days.