- Solutions
-
-
Adaptive Applications
Get AI-ready with hyper-personalized apps!
Next level customer experiences require adaptive applications
Learn more
-
-
- Developers
-
-
Developer Playground
-
-
- Resources
-
-
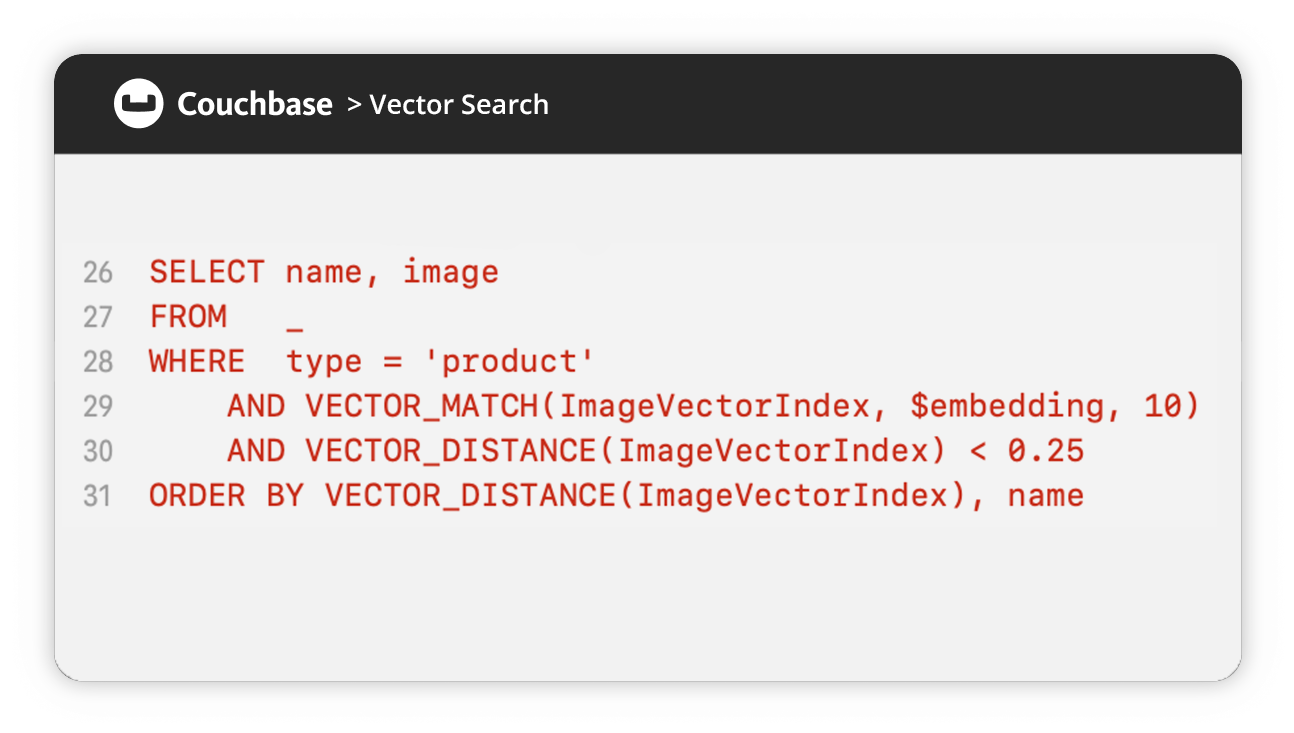
Vector Search
What's Vector Search and why is it important?
Get a quick overview of vectors, vector search, use cases, and key features.
Watch
-
-
Get practical solutions to common problems: O'Reilly JavaScript Cookbook
Overview
To help you better understand NoSQL, this page covers:
NoSQL databases store data in documents rather than relational tables. Accordingly, we classify them as "not only SQL" and subdivide them by a variety of flexible data models. Types of NoSQL databases include pure document databases, key-value stores, wide-column databases, and graph databases. NoSQL databases are built from the ground up to store and process vast amounts of data at scale and support a growing number of modern businesses.
What is NoSQL and what is a NoSQL database?
NoSQL database technology stores information in JSON documents instead of columns and rows used by relational databases. To be clear, NoSQL stands for “not only SQL” rather than “no SQL” at all. This means a NoSQL JSON database can store and retrieve data using literally “no SQL.” Or you can combine the flexibility of JSON with the power of SQL for the best of both worlds. Consequently, NoSQL databases are built to be flexible, scalable, and capable of rapidly responding to the data management demands of modern businesses. The following defines the four most-popular types of NoSQL database:
- Document databases are primarily built for storing information as documents, including, but not limited to, JSON documents. These systems can also be used for storing XML documents, for a NoSQL database example.
- Key-value stores group associated data in collections with records that are identified with unique keys for easy retrieval. Key-value stores have just enough structure to mirror the value of relational databases (as opposed to non-relational databases) while still preserving the benefits of the NoSQL database structure.
- Wide-column databases use the tabular format of relational databases yet allow a wide variance in how data is named and formatted in each row, even in the same table. Like key-value stores, wide-column databases have some basic NoSQL structure while also preserving a lot of flexibility
- Graph databases use graph structures to define the relationships between stored data points. Graph databases are useful for identifying patterns in unstructured and semi-structured information.
Why use NoSQL?
Customer experience has quickly become the most important competitive differentiator and ushered the business world into an era of monumental change. As part of this revolution, enterprises are interacting digitally – not only with their customers, but also with their employees, partners, vendors, and even their products – at an unprecedented scale. This interaction is powered by the internet and other 21st century technologies – and at the heart of the revolution of NoSQL are a company’s big data, cloud, mobile, social media, and IoT applications.
How are these applications different from legacy enterprise applications like ERP, HR, and financial accounting? Today’s web, mobile, and IoT applications share one or more (if not all) of the following characteristics. They need to:
- Support large numbers of concurrent users (tens of thousands, perhaps millions)
- Deliver highly responsive experiences to a globally distributed base of users
- Be always available – no downtime
- Handle semi- and unstructured data
- Rapidly adapt to changing requirements with frequent updates and new features
Building and running these massively interactive applications has created a new set of technology requirements. The new enterprise NoSQL technology architecture needs to be far more agile than ever before, and requires an approach to real-time data management that can accommodate unprecedented levels of scale, speed, and data variability. Relational databases are unable to meet these new requirements, and enterprises are therefore turning to NoSQL database types.
Global 2000 enterprises are rapidly embracing NoSQL databases to power their mission-critical applications:
- Tesco, Europe’s No. 1 retailer, deploys NoSQL for e-commerce, product catalog, and other applications
- Marriott deploys NoSQL for its reservation system that books $38 billion annually
- Gannett, the No. 1 U.S. newspaper publisher, uses NoSQL for its proprietary content management system, Presto
- GE deploys NoSQL for its Predix platform to help manage the Industrial Internet
Five trends creating new technical challenges that NoSQL DBs address
These companies and hundreds more like them are turning to NoSQL because of five trends that present technical challenges that are too difficult for most relational databases.
These companies and hundreds more like them are turning to NoSQL because of five trends that present technical challenges that are too difficult for most relational databases.
Digital Economy trends |
Requirements |
|---|---|
| 1. More customers are going online |
• Scaling to support thousands, if not millions, of users • Meeting UX requirements with consistent high performance • Maintaining availability 24 hours a day, 7 days a week |
| 2. The internet is connecting everything |
• Supporting many different things with different data structures • Supporting hardware/software updates, generating different data • Supporting continuous streams of real-time data |
| 3. Big data is getting bigger |
• Storing customer generated semi-structured/unstructured data • Storing different types of data from different sources, together • Storing data generated by thousands/millions of customers/things |
| 4. Applications are moving to the cloud |
• Scaling on demand to support more customers, store more data • Operating applications on a global scale – customers worldwide • Minimizing infrastructure costs, achieving a faster time to market |
| 5. The world has gone mobile |
• Creating “offline first” apps – network connection not required • Synchronizing mobile data with remote databases in the cloud • Supporting multiple mobile platforms with a single backend |
What about SQL?
We call some relational databases SQL databases for their reliance on SQL (aka “structured query language”) to retrieve relevant information. First introduced in 1979, SQL is now used by developers and data analysts around the globe to find and report on data stored in relational systems such as Oracle.
Why relational databases fall short
Relational DBMS (database management systems) were born in the era of mainframes and business applications – long before the internet, the cloud, big data, mobile, and today’s massively interactive enterprise. These databases were engineered to run on a single server – the bigger, the better. The only way to increase the capacity of these databases was to upgrade the servers – processors, memory, and storage – to scale up.
NoSQL databases emerged as a result of the exponential growth of the internet and the rise of web applications. Google released the Bigtable research paper in 2006, and Amazon released the Dynamo research paper in 2007. These databases were engineered to meet a new generation of enterprise requirements:
The need to develop with agility, to meet changing requirements, and to eliminate data transformation.
Develop with agility
To remain competitive in today’s experience-focused digital economy, enterprises must innovate – and they have to do it faster than ever before. And because this innovation centers on the development of modern web, mobile, and IoT applications, developers have to deliver applications and services faster than ever before. Speed and agility are both critical because these applications evolve far more rapidly than legacy applications like ERP. Relational databases are a major roadblock because they don’t support agile development very well due to their fixed data model.
Scoping for changing requirements
A core principle of agile development is adapting to evolving application requirements: when the requirements change, the data model also changes. This is a problem for relational databases because the data model is fixed and defined by a static schema. So in order to change the data model, developers have to modify the schema, or worse, request a “schema change” from the database administrators. This slows down or stops development, not only because it’s a manual, time-consuming process, but also because it impacts other applications and services.
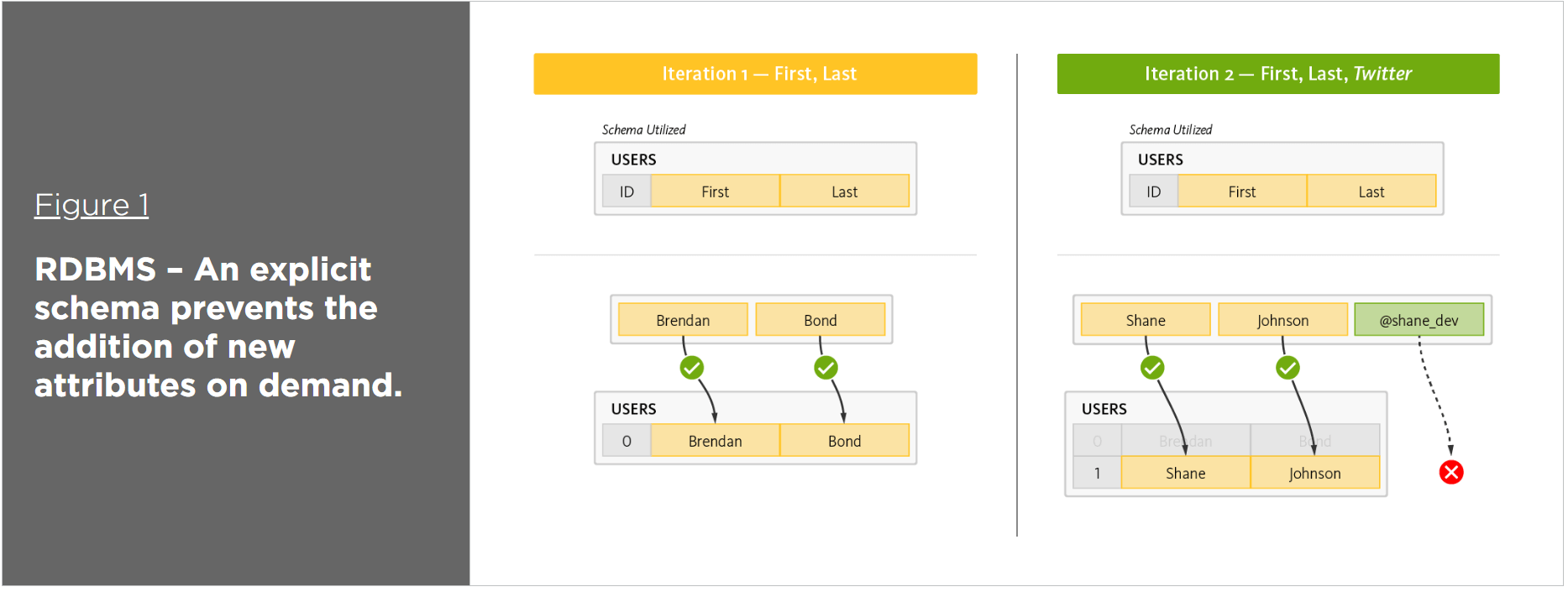
By contrast, a NoSQL database fully supports agile development and does not statically define how the data must be modeled. Instead, NoSQL defers to the applications and services, and thus to the developers as to how data should be modeled. With NoSQL, the data model is defined by the application model. Applications and services model data as objects.
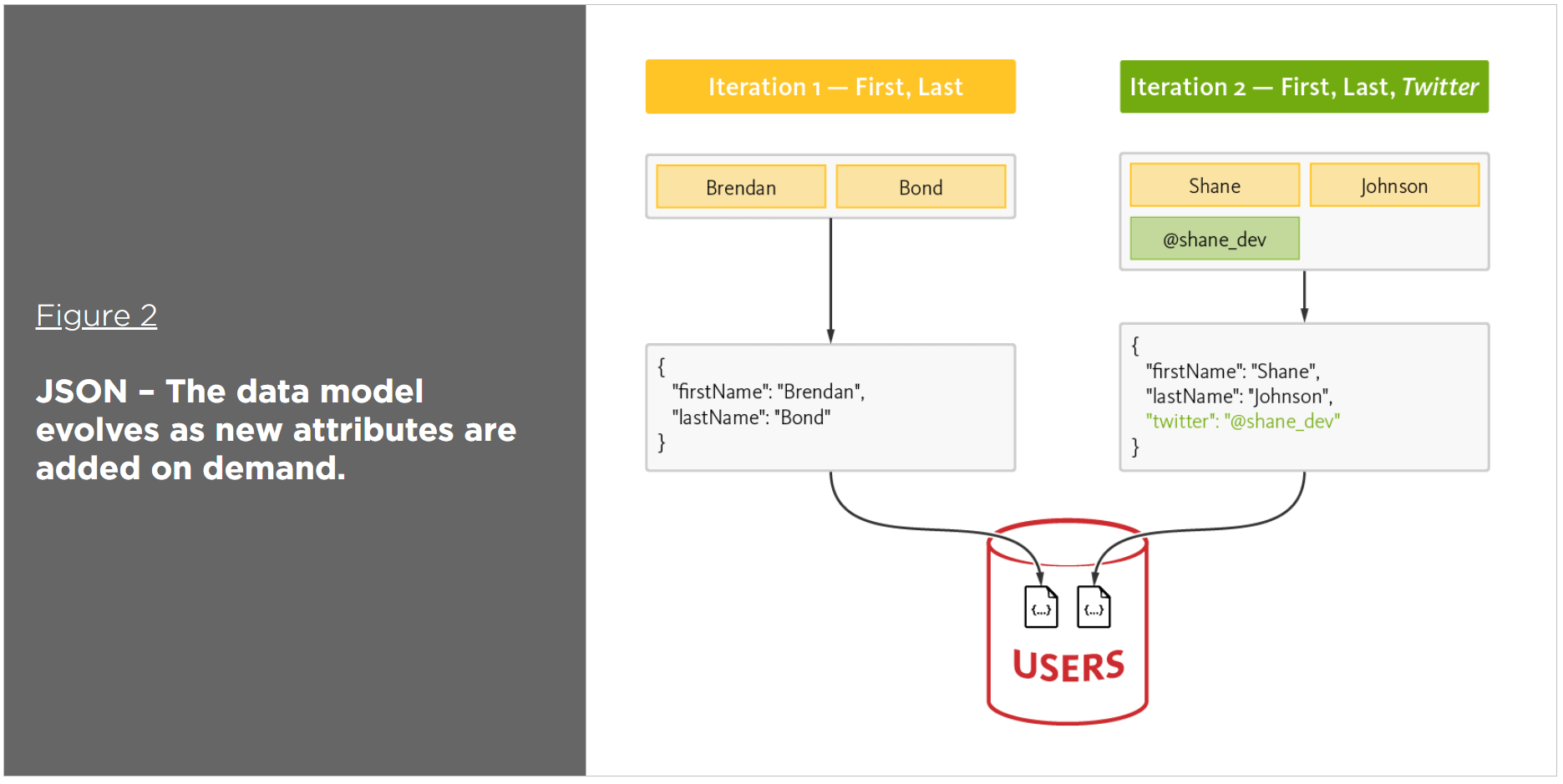
Eliminate data transformation
Applications and services model data as objects (e.g., employee), multi-valued data as collections (e.g., roles), and related data as nested objects or collections (e.g., manager). However, relational databases model data as tables of rows and columns – related data as rows within different tables, and multi-valued data as rows within the same table.
The problem with relational databases is that data is read and written by disassembling, or “shredding,” and reassembling objects. This is the object-relational “impedance mismatch.” The workaround is transforming data via object-relational mapping frameworks, which are inefficient at best, and problematic at worst. NoSQL databases generally handle data as it is presented.
How does NoSQL work?
How does NoSQL compare? Let’s take a closer look. The following NoSQL tutorial illustrates an application used for managing resumes. It interacts with resumes as an object (i.e., the user object), contains an array for skills, and has a collection for positions. Alternatively, writing a resume to a relational database requires the application to “shred” the user object.
Storing this resume would require the application to insert six rows into three tables, as illustrated in Figure 3.
And, reading this profile would require the application to read six rows from three tables, as illustrated in Figure 4.
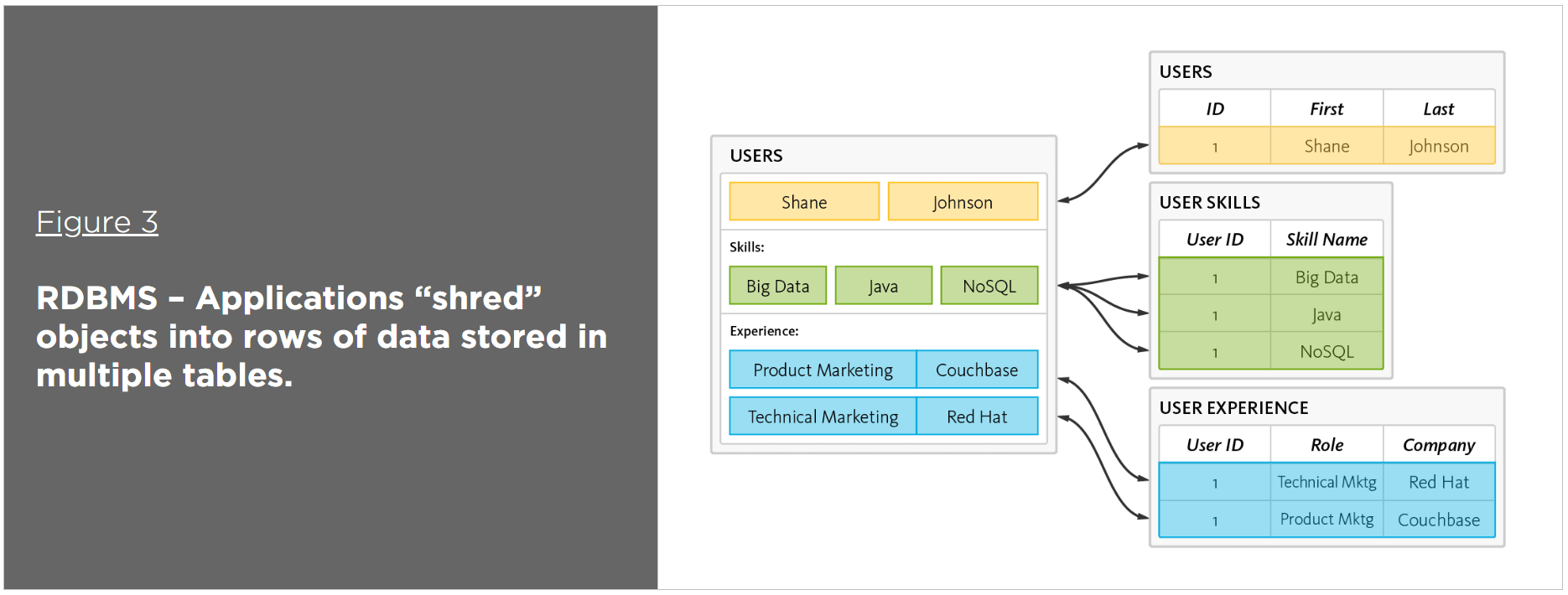
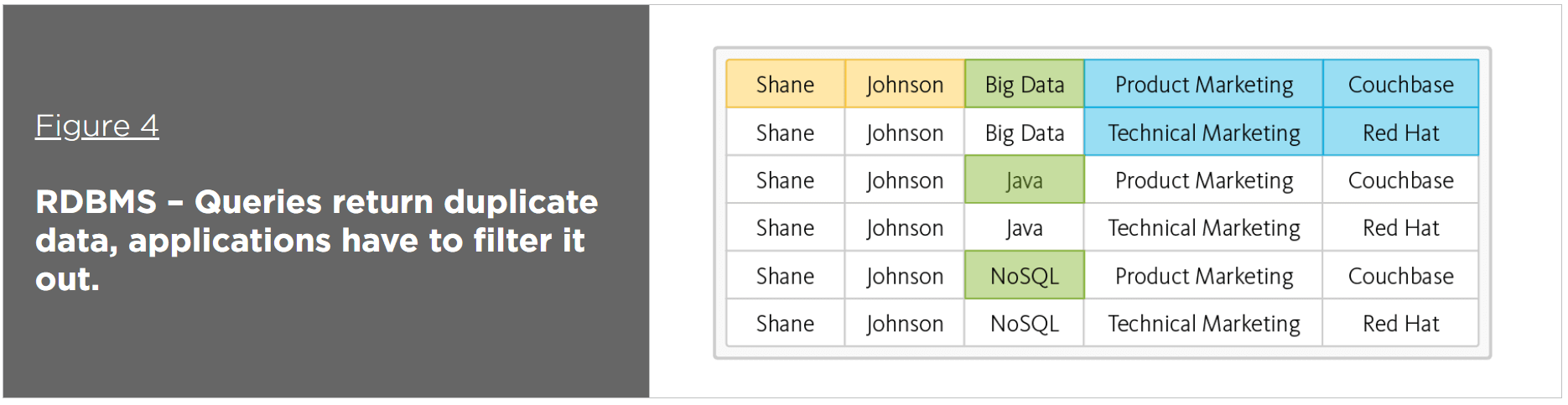
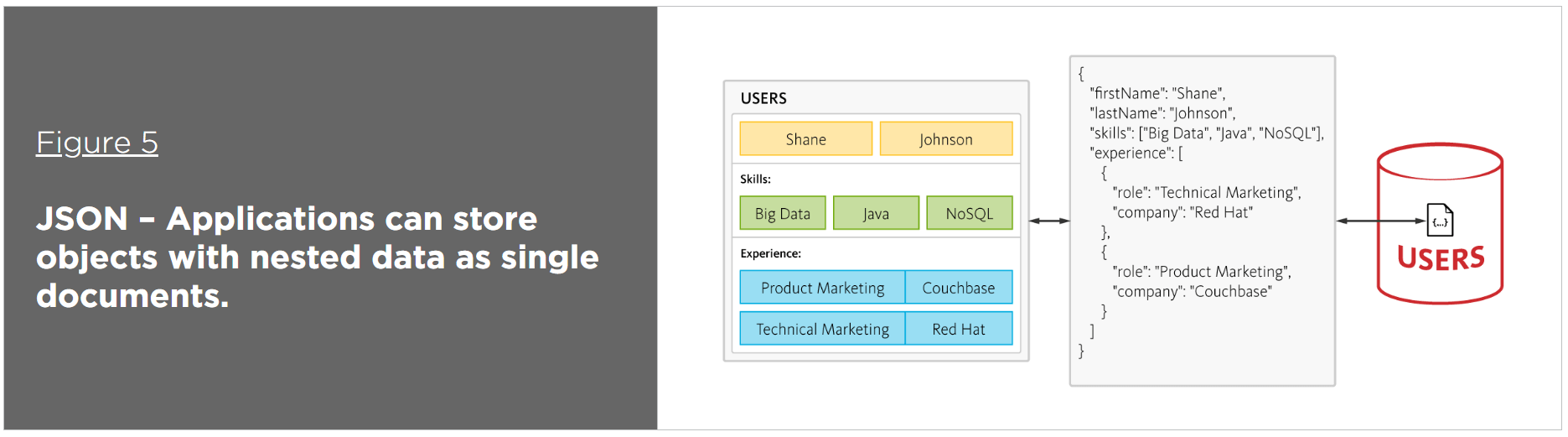
By contrast, in a document-oriented database defined as NoSQL, JSON is the de facto format for storing data – helpfully, it’s also the de facto standard for consuming and producing data for web, mobile, and IoT applications. JSON not only eliminates the object-relational impedance mismatch, it also eliminates the overhead of ORM frameworks and simplifies application development because objects are read and written without “shredding” them (i.e., a single object can be read or written as a single document), as illustrated in Figure 5.
What about querying and SQL?
Some may argue that it’s tougher to query NoSQL databases, but this is a common misconception. The inherent flexibility of document-oriented NoSQL databases makes it possible to handle structured and unstructured data equally well, and new tools allow for faster querying than ever before.
Couchbase Server 4.0 introduced SQL++, a powerful query language that extends SQL to JSON, enabling developers to leverage both the power of SQL and the flexibility of JSON. It not only supports standard SELECT / FROM / WHERE statements, it also supports aggregation (GROUP BY), sorting (SORT BY), joins (LEFT OUTER / INNER), as well as querying nested arrays and collections. In addition, query performance can be improved with composite, partial, covering indexes, and more.
SQL
SELECT RTRIM(p.FirstName) + ' ' + LTRIM(p.LastName) AS Name, d.City
FROM AdventureWorks2016.Person.Person AS p
INNER JOIN AdventureWorks2016.HumanResources.Employee e ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN
(SELECT bea.BusinessEntityID, a.City
FROM AdventureWorks2016.Person.Address AS a
INNER JOIN AdventureWorks2016.Person.BusinessEntityAddress AS bea
ON a.AddressID = bea.AddressID) AS d
ON p.BusinessEntityID = d.BusinessEntityID
ORDER BY p.LastName, p.FirstName;
SQL++
SELECT RTRIM(p.FirstName) || ' ' || LTRIM(p.LastName) AS Name, d.City
FROM AdventureWorks2016.Person.Person AS p
INNER JOIN AdventureWorks2016.HumanResources.Employee e ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN
(SELECT bea.BusinessEntityID, a.City
FROM AdventureWorks2016.Person.Address AS a
INNER JOIN AdventureWorks2016.Person.BusinessEntityAddress AS bea
ON a.AddressID = bea.AddressID) AS d
ON p.BusinessEntityID = d.BusinessEntityID
ORDER BY p.LastName, p.FirstName;
Operate at any scale
Databases that support web, mobile, and IoT applications must be able to operate at any scale. While it’s possible to scale a relational database like Oracle (using, for example, Oracle RAC), doing so is typically complex, expensive, and not fully reliable. With Oracle, for example, scaling out using RAC technology requires numerous components and creates a single point of failure that jeopardizes availability. By contrast, a NoSQL distributed database – designed with a scale-out architecture and no single point of failure – provides compelling operational advantages.
Elasticity for performance at scale
Applications and services have to support an ever-increasing number of users and data – hundreds to thousands to millions of users, and gigabytes to terabytes of operational data. At the same time, they have to scale to maintain performance, and they have to do it efficiently.
The database has to be able to scale reads, writes, and storage.
This is a problem for relational databases that are limited to scaling up (i.e., adding more processors, memory, and storage to a single physical server). As a result, the ability to scale efficiently, and on demand, is a challenge. It becomes increasingly expensive because enterprises have to purchase bigger and bigger servers to accommodate more users and more data. In addition, it can result in downtime if the database has to be taken offline to perform hardware upgrades.
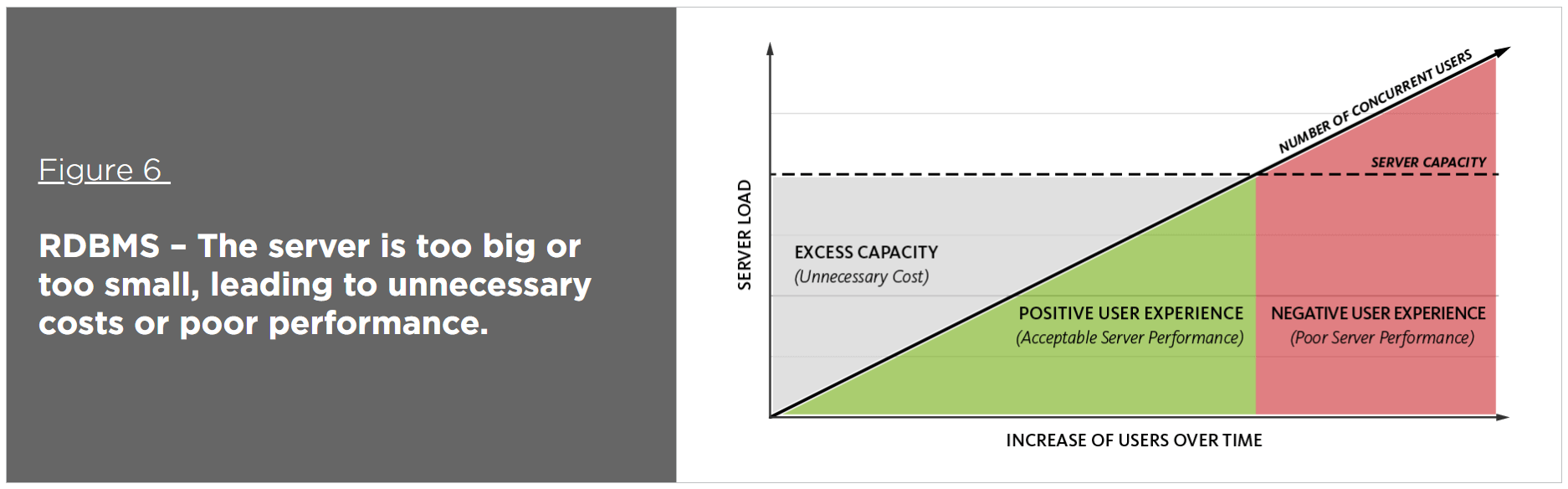
A distributed NoSQL database, however, leverages commodity hardware to scale out – i.e., add more resources simply by adding more servers. The ability to scale out enables enterprises to scale more efficiently by (a) deploying no more hardware than is required to meet the current load; (b) leveraging less expensive hardware and/or cloud infrastructure; and (c) scaling on demand and without downtime.

In addition to being able to scale effective and efficiently, distributed NoSQL databases are easy to install, configure, and scale. They were engineered to distribute reads, writes, and storage, and they were engineered to operate at any scale – including the management and monitoring of clusters small and large.
Availability for always-on, global deployment
As more and more customer engagements take place online via web and mobile apps, availability becomes a major, if not primary, concern. These mission-critical applications have to be available 24 hours a day, 7 days a week – no exceptions. Delivering 24×7 availability is a challenge for relational databases that are deployed to a single physical server or that rely on clustering with shared storage. If deployed as a single server and it fails, or as a cluster and the shared storage fails, the database becomes unavailable.
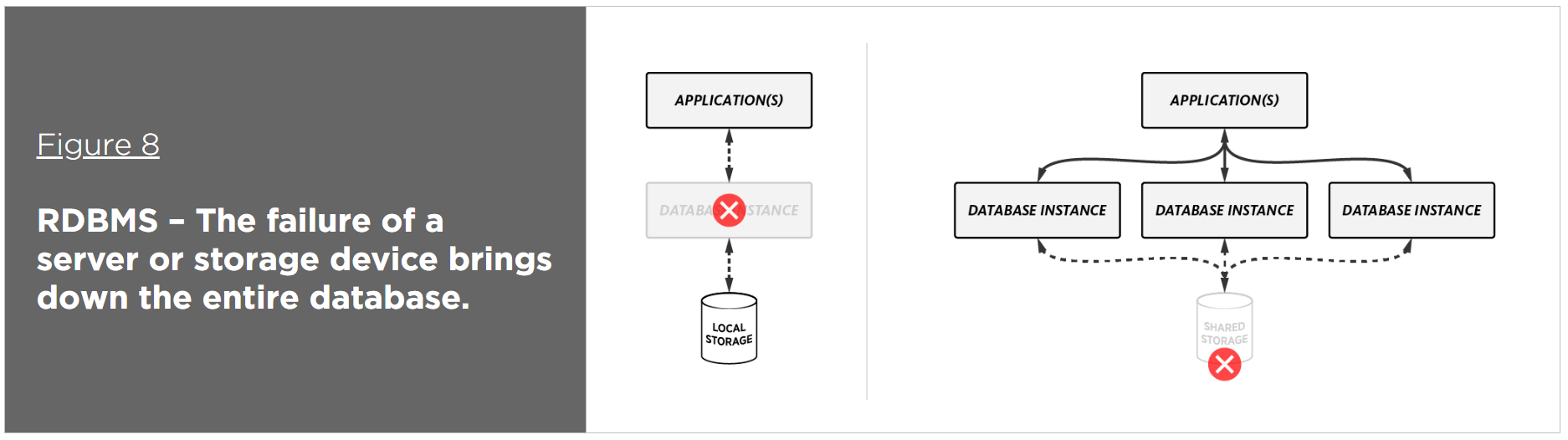
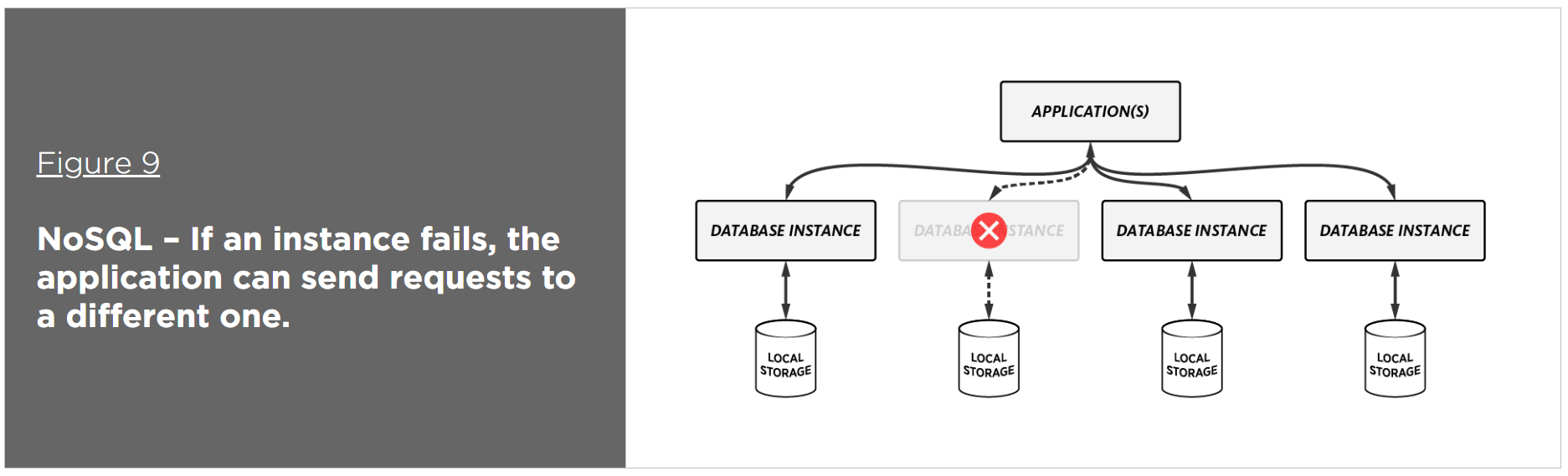
In contrast to relational technology, a distributed, NoSQL database partitions and distributes data to multiple database instances with no shared resources. In addition, the data can be replicated to one or more instances for high availability (intercluster replication). While relational databases like Oracle require separate software for replication (e.g., Oracle Active Data Guard), NoSQL databases do not – it’s built in and it’s automatic. In addition, automatic failover ensures that if a node fails, the database can continue to perform reads and writes by sending the requests to a different node.
As customer engagements move online, the need to be available in multiple countries and/or regions becomes critical. While deploying a database to multiple datacenters increases availability and helps with disaster recovery, it also has the benefit of increasing performance, because all reads and writes can be executed on the nearest datacenter, thereby reducing latency.
Ensuring global availability is difficult for relational databases in cases where the requirement of separate add-ons increases complexity (e.g., Oracle requires Oracle GoldenGate to move data between databases) – or when replication between multiple datacenters can only be used for failover because only one datacenter is active at a time. Also, when replicating between datacenters, applications built on relational databases can experience performance degradation or find that the datacenters are severely out of sync.
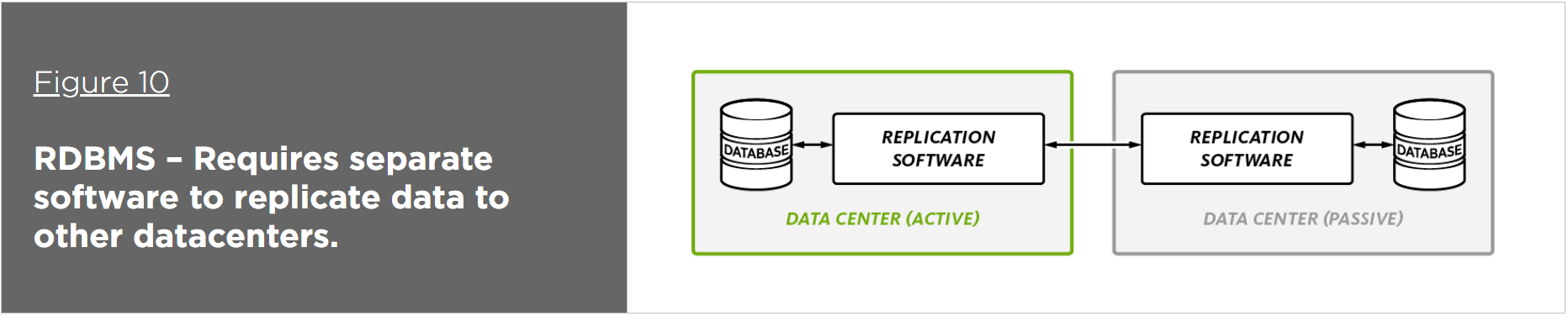
A distributed, NoSQL database includes built-in replication between datacenters – no separate software is required. In addition, some include both unidirectional and bidirectional replication enabling full active-active deployments to multiple datacenters, which allow the database to be deployed in multiple countries and/or regions and to provide local data access to local applications and their users. This not only improves performance, it also enables immediate failover via hardware routers – applications don’t have to wait for the database to discover the failure and perform its own failover.
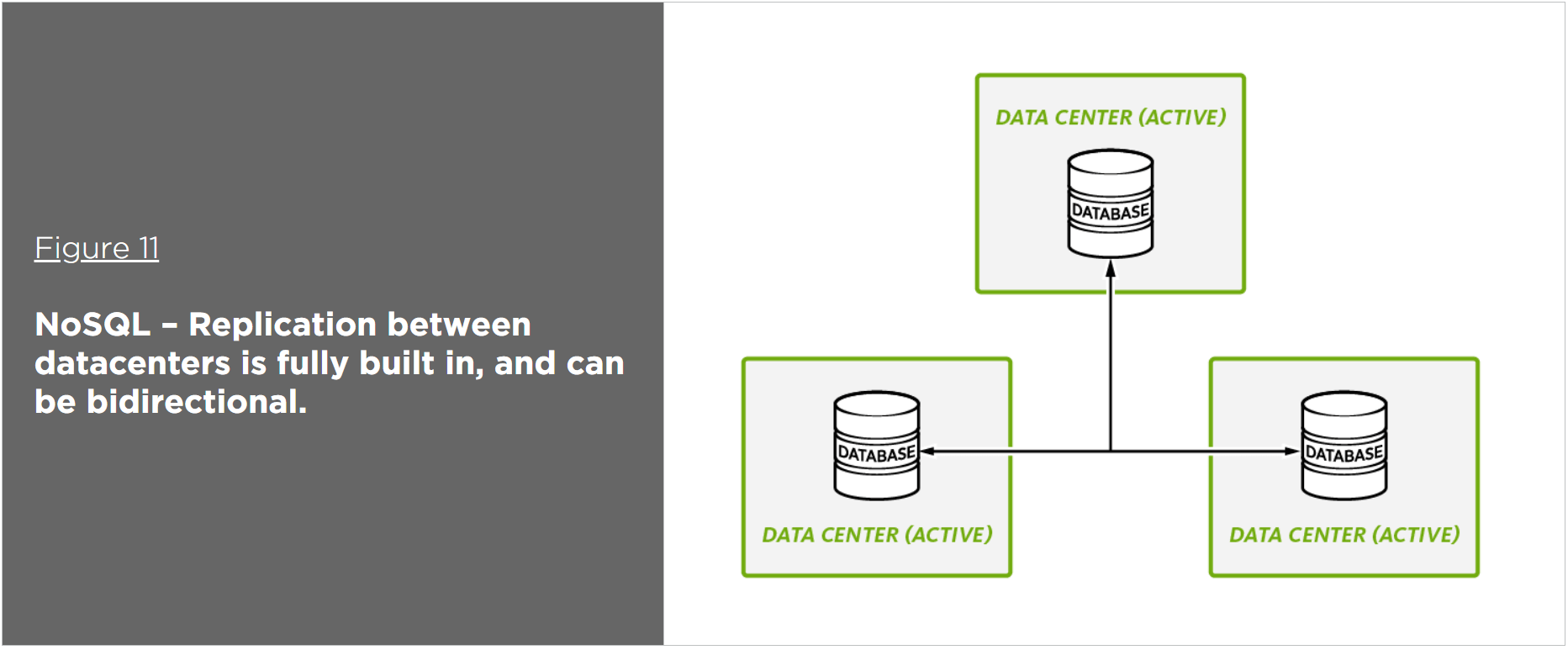
Conclusion
So what are NoSQL databases and why do they matter now? As enterprises shift to the Digital Economy – enabled by cloud, mobile, social media, and big data technologies – developers and operations teams have to build and maintain web, mobile, and IoT applications faster and faster, and at greater scale. Flexible, high-performance NoSQL is increasingly the preferred database technology to power today’s web, mobile, and IoT applications.
Hundreds of Global 2000 enterprises, along with tens of thousands smaller businesses and startups, have adopted NoSQL. For many, the use of NoSQL started with a cache, proof of concept, or a small application, then expanded to targeted mission-critical applications, and is now the foundation for all application development.
With NoSQL databases, enterprises are better able to both develop with agility and operate at any scale – and deliver the performance and availability required to meet the demands of Digital Economy businesses.
