Explicación del Índice Flex
¿Qué es un índice Flex? Una de las tareas clave de un motor de base de datos es cómo gestionar eficientemente la búsqueda y recuperación de los datos que contiene. La eficiencia y el equilibrio entre consumo de recursos y rendimiento son los aspectos más críticos de cualquier base de datos. Los distintos tipos de índices de bases de datos, por ejemplo B-Tree, Inverted, Graph y Spatial, etc., están diseñados para satisfacer diferentes requisitos de búsqueda. Aunque los índices son esenciales para el rendimiento de las búsquedas, la elección del tipo de índice adecuado también puede marcar una gran diferencia en su eficacia. Y es que el mejor tipo de índices suele venir dictado por las características del elemento de datos que se indexa.
En Couchbase, el Índice Secundario Global utiliza una estructura de Árbol B para una rápida búsqueda exacta y de rango, y la Búsqueda de Texto Completo utiliza la estructura de índice invertido para proporcionar una búsqueda eficiente de términos. Además de ser altamente escalables, cada uno de estos tipos de índice también ofrece sus propias capacidades únicas. B-Tree es el índice más utilizado para valores de alta selectividad (es decir, más distintivos, como el número de pedido), mientras que los índices invertidos se utilizan mejor para indexar contenido textual, donde es probable que el término buscado tenga una selectividad baja.
Las aplicaciones que interactúan directamente con los usuarios necesitan capacidad de búsqueda y, en la mayoría de los casos, estas aplicaciones requieren tanto búsqueda exacta como búsqueda de texto. Estas capacidades de búsqueda suelen estar disponibles a través de diferentes servicios de búsqueda, y como API de búsqueda independientes, lo que a su vez puede aumentar la complejidad del desarrollo de la aplicación.
Para responder a esta necesidad, Couchbase introdujo la función SEARCH() de N1QL en la versión 6.5. Permite que las consultas N1QL usen tanto predicados SQL para búsquedas exactas y de rango, como SEARCH() para búsquedas de texto, donde los resultados no sólo se predicen por el término de búsqueda, sino también por su puntuación de relevancia. Esto añade un factor de imprecisión a la búsqueda, así como capacidades de conocimiento del idioma.
La función N1QL SEARCH(), por primera vez, permite a las aplicaciones acceder a ambos servicios de búsqueda de consultas desde una única API, utilizando el lenguaje N1QL de Couchbase. Esta integración ofrece muchas ventajas. La principal de ellas es la simplificación del proceso de desarrollo de aplicaciones al no tener que lidiar con diferentes APIs, pero también delegar más del procesamiento de búsqueda a los servicios de back-end.
En Couchbase 6.6, llevamos esta integración N1QL/FTS un paso más allá con Índice Couchbase Flex.
¿Qué es el Índice Flex?
Flex index es una capacidad para que el servicio de consultas de Couchbase aproveche las capacidades de búsqueda, utilizando sólo el predicado estándar de N1QL. Esto significa que no necesitas usar la sintaxis FTS, ni la función SEARCH(), para que tu consulta N1QL aproveche los índices FTS.
El tipo de datos de búsqueda incluye texto, fecha y hora, numérico y booleano. En el caso del texto, sólo se admite la búsqueda por palabra clave.
Búsqueda por palabra clave - se refiere a la forma en que se procesa un campo de texto antes de añadirlo a un índice. El índice FTS utiliza la función estándar analizaría el texto en términos individuales antes de indexarlo, mientras que el analizador palabra clave utiliza todo el texto para el índice.
Para entender cómo funciona Flex Index, supongamos que tiene una consulta con esta condición de búsqueda: Encontrar todas las actividades de un sistema de gestión de actividades de ventas en las que haya participado el cliente "Horizon Communications", que hayan tenido lugar en agosto de 2020 y que hayan tenido lugar durante un evento de marketing en el Moscone Center.
|
1 2 3 4 5 |
SELECCIONE * DESDE crm DONDE tipo=Actividad Y evento.ubicación = Moscone Center Y cuenta.nombre = Horizon Communications Y fecha_acto ENTRE '2020-08-01' Y '2020-08-31' |
Supongamos también que tiene este índice GSI :
|
1 2 3 |
CREAR ÍNDICE adv_account_name_event_site_actdate EN `crm`(`cuenta`.`nombre`,`evento`.`ubicación`,`act_date`) DONDE tipo=Actividad |
Esta consulta, tal y como está escrita, aprovechará el índice GSI anterior porque:
- Todos los predicados de consulta están cubiertos por el índice.
- La consulta también tiene el predicado
tipo='actividad' que coincide con el filtro del índice. - De hecho, el índice se considerará siempre que la clave principal
cuenta.nombrees uno de los predicados, y que la consulta está restringida atipo='actividad'.
Plan de consulta:

Con Índice Flexahora tiene la opción de solicitar al servicio de consulta que considere el uso del índice FTS para la consulta.
|
1 2 3 4 5 |
SELECCIONAR * DESDE crm UTILICE ÍNDICE (USO DE FTS) DONDE tipo=Actividad Y evento.sitio = Moscone Center Y cuenta.nombre = Horizon Communications Y fecha_acto ENTRE '2020-08-01' Y '2020-08-31' |
La adición del "UTILIZAR ÍNDICE (UTILIZANDO FTS)"sugiere al servicio de consulta que considere el uso de cualquier índice FTS, si hay alguno disponible que pueda ayudar con la consulta.
Y si tiene un índice FTS definido como se indica a continuación:
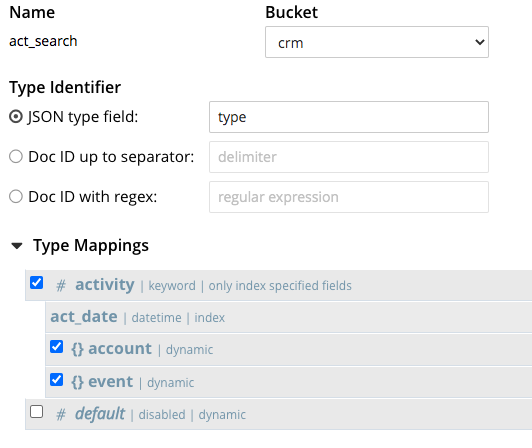
En act_buscar tiene la siguiente definición:
- Tiene un
tipoque restringe el contenido del índice para incluir sólo los documentos detipo= "actividad". - Incluye el campo hijo
fecha_acto. - Incluye las dos asignaciones secundarias para
cuentayeventoobjetos. - Tenga en cuenta que utiliza el
palabra claveanalizador.
En este caso, el actuar_buscar se ajusta perfectamente a la consulta N1QL anterior, y con la función UTILIZAR ÍNDICE (UTILIZANDO FTS) la consulta podrá utilizar la función actuar_buscar Índice FTS.
Plan de consulta:

En pocas palabras, Índice Couchbase Flex ofrece la posibilidad de que N1QL Query con la sintaxis de predicado estándar de N1QL aproveche de forma transparente el índice GSI o FTS sin ninguna modificación de las declaraciones N1QL.
Pero el valor de Flex Index no sólo reside en la sintaxis más sencilla para utilizar FTS, sino también en la versatilidad del índice FTS, algunas de las cuales se describirán en las secciones siguientes.
¿Cuándo utilizar el Índice Flex?
A alto nivel, Índice Flex puede resolver muchos problemas que suelen plantearse en las aplicaciones que ofrecen búsquedas.
- Donde las condiciones de búsqueda de las sentencias N1QL no están predeterminadas, lo que significa que pueden contener un número variado de predicados, a menudo basados en las selecciones del usuario. Y es difícil crear índices que cubran todas las condiciones de búsqueda...
- Aplicaciones que proporcionan capacidades de búsqueda que implican un gran número de predicados, con operadores lógicos, como combinaciones AND/OR en las condiciones de búsqueda.
- Cuando las condiciones de búsqueda implican predicados sobre elementos jerárquicos del documento, como la búsqueda que implica elementos de matriz en una matriz, o en múltiples matrices.
- Cuando las aplicaciones requieren la potencia de FTS, pero también necesitan agregación SQL y JOIN para incluir información relacionada de otros objetos.
- O simplemente desea utilizar la sintaxis de predicado N1QL sobre la sintaxis FTS.
Tenga en cuenta que Flex Index también puede utilizarse retrospectivamente en aplicaciones existentes añadiendo la propiedad use_fts a las llamadas a la API de consulta.
1) Los patrones de búsqueda no están predeterminados
Cuando se trata de proporcionar capacidad de búsqueda a los usuarios finales, el reto siempre ha sido qué permitiría buscar al usuario. Las directrices estándar dictan que la decisión venga determinada por las necesidades de los usuarios. Pero en los sistemas complejos, donde los campos de búsqueda no suelen limitarse a unos pocos campos clave, sino que pueden abarcar todos los campos de un objeto, la decisión sobre la búsqueda suele depender de lo que pueda soportar el sistema de base de datos subyacente.
Las aplicaciones que se basan en el índice B-Tree tradicional para realizar búsquedas rápidas suelen quedarse cortas a la hora de proporcionar un marco flexible para este tipo de requisitos de búsqueda.
Considere este documento:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
"actividad" : { "id": "act1000", "título: "Anunciando Couchbase Flex Index CB6.6", "referencia": "24-i2y5J3928", "dept": "st55", "región": "00528", "notas": " Revisa las 100 consultas N1QL Flex Index que ElasticSQL no puede hacer. El punto importante aquí es que Couchbase ha integrado la capacidad de búsqueda de texto en su N1QL. Mientras que ElasticSearch, relativamente nuevo en SQL, ha añadido SQL a su motor de búsqueda....", "propietario": { "id": "usr24", "nombre": "John Higgins" }, "prioridad": "Medio", "tipo_acto": "Nombramiento", "evento": { "nombre": "Índice N1QL Flex vs. ElasticSQL", "localización": "Moscone Center", "tema": "CouchbaseRed", "vendedor": "Kempinski" }, "cuenta": { "id": "acc134", "nombre": "Horizon Communications" }, "act_date": "2020-08-06", "nombramiento": { "duración": 90, "fecha_inicio": "2020-08-06 11:00:00", "contactos": [ { "id": "contacto2493", "título: "SalesRep", "nombre": "Miranda Sullivan", "email": "msullivan@horizoncell.com", "teléfono": "778-096-1351" } ], "participantes": [ { "rol": "Analista de soporte", "userid": "usr57", "nombre": "Raven Peterson" }, { "rol": "Especialista en productos", "userid": "usr24", "nombre": "John Higgins" } ], "tipo": "actividad" } |
Los 13 campos resaltados son todos los posibles campos que el usuario puede querer buscar. Entonces, ¿cuál sería la estrategia de indexación si se quiere proporcionar a los usuarios la capacidad de búsqueda?
| Estrategia de índices | Pros | Contras |
| Crear 13 índices individuales | 1-Eficaz para la búsqueda en un solo campo. | 1-Si hay más de un campo en la búsqueda, se utilizarán varios índices, lo que dará lugar a búsquedas de intersección que afectarán al rendimiento.
2-Cada vez más ineficiente a medida que se incluyen más campos de búsqueda |
| Crear un índice compuesto para las combinaciones de búsqueda más frecuentes | 1-Tiempo de respuesta rápido | 1-Inflexible, ya que sólo admite determinadas combinaciones de búsqueda.
2-App UI tiene que asegurarse de que la clave principal del índice está presente. |
| Crear un índice compuesto para todas las combinaciones de búsqueda | 1-Tiempo de respuesta más rápido | 1-El número total de índices (¡13!) sería poco práctico |
| Aprovechar el motor de búsqueda - ElasticSearch o Couchbase FTS | 1-Tiempo de respuesta rápido
2-Sólo se necesita un índice |
1-Necesita reescribir la aplicación para aprovechar el motor de búsqueda
2-Código de aplicación más complejo 3-Costes de mantenimiento |
De la lista anterior de opciones, está claro que la capacidad de búsqueda más flexible requerirá el uso de un motor de búsqueda, algo similar a ElasticSearch o Couchbase FTS. Pero a menos que hayas desarrollado tu aplicación específicamente con estos motores de búsqueda en mente, el esfuerzo para convertir la sintaxis de búsqueda y el cambio de API no será trivial.
Y aquí es donde el valor de Couchbase Flex Index entra en escena. Esta nueva característica permite a los desarrolladores escribir sentencias N1QL Query usando predicados N1QL estándar, y el servicio Query aprovechará de forma transparente el índice FTS.
2) Consulta con cualquier combinación de predicados
Una de las principales diferencias entre el índice B-Tree de GSI y el índice de texto FTS es cómo se construyen los campos clave. El índice B-Tree de GSI concatena todos los campos clave del índice para formar la clave de nodo, que es la razón principal por la que una clave principal debe estar presente en la consulta antes de que el índice pueda ser considerado. En cambio, el índice FTS crea un índice invertido independiente para cada campo. Este diseño permite considerar un índice FTS para cualquier consulta que tenga al menos uno de los campos indexados.
Consideremos la siguiente consulta que tiene 13 predicados diferentes, así como el predicado tipo='predicado de actividad.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECCIONE * DESDE crm a DONDE a.tipo=Actividad /* 1 */ Y a.título COMO Anuncio de Couchbase Flex Index% /* 2 */ Y a.dept = st55 /* 3 */ Y a.región = '00528' /* 4 */ Y a.prioridad = Alto /* 5 */ Y a.act_date ENTRE '2020-08-01' Y '2020-08-31' /* 6 */ Y a.evento.ubicación = Moscone Center Sur /* 7 */ Y a.evento.nombre = Índice N1QL Flex vs ElasticSQL /* 8 */ Y a.evento.vendedor = Kempskinki /* 9 */ Y a.evento.tema = CouchbaseRed /* 10 */ Y a.id.cuenta = "acc134 /* 11 */ Y a.cuenta.nombre = Horizon Communications /* 12 */ Y a.propietario.id = usr24 /* 13 */ Y a.propietario.nombre = John Higgins |
Para obtener el mejor rendimiento, es necesario tener un índice para la consulta, y el mejor índice que se puede tener es un índice de cobertura como el que ofrece ADVISE:
|
1 2 3 4 5 |
CREAR ÍNDICE adv_idx13 EN crm (`cuenta`.`nombre`,`event`.`vendor`,`account`.`id`,`event`.`ubicación`, `event`.`theme`,`priority`,`propietario`.`nombre`,`dept`,`event`.`nombre`, `propietario`.`id`,`region`,`act_date`,`title`) DONDE `tipo` = Actividad |
Plan de consulta:

Sin embargo, ¿qué pasaría si:
- La consulta no tiene la clave principal
cuenta.nombre? - ¿La consulta tiene una combinación variable de los 13 predicados?
GSI es el mejor índice, siempre que se conozcan los predicados exactos de la consulta. Sin embargo, para las aplicaciones que necesitan dar soporte a consultas ad hoc, en las que el conjunto de predicados no puede predeterminarse, entonces es mejor considerar el uso de FTS.
Consideremos ahora el siguiente índice FTS.
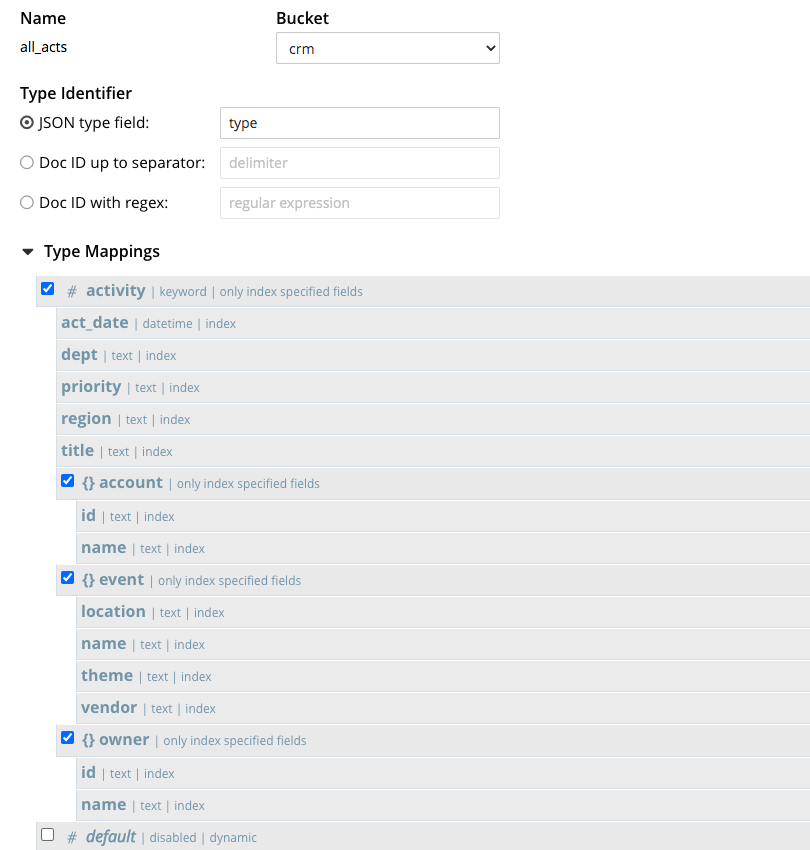
Notas:
- El índice contiene un
tipopara especificar que sólo los documentos con eltipo= 'actividad' se incluirá en el índice. Consulte Asignaciones de tipos FTS para más información. - El índice utiliza el analizador de palabras clave, lo que significa que el valor de los datos se añadirá al índice en su totalidad sin ser analizado en términos individuales.
- Cada campo se indexa individualmente de forma muy similar al índice GSI. Todas las demás opciones están desmarcadas, ya que no son relevantes para la búsqueda de palabras clave. Consulte esta Asignación de niños FTS para más información.

Con este índice FTS en su lugar, la misma consulta anterior, pero con el índice USE INDEX (all_acts USING FTS) indicará al servicio de consulta que considere el uso del índice FTS en su lugar. Tenga en cuenta que el nombre del índice todos_los_actos es opcional.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECCIONE * DESDE crm a DONDE a.tipo=Actividad UTILIZAR ÍNDICE (USO DE FTS) /* 1 */ Y a.título COMO Anuncio de Couchbase Flex Index% /* 2 */ Y a.dept = st55 /* 3 */ Y a.región = '00528' /* 4 */ Y a.prioridad = Alto /* 5 */ Y a.act_date ENTRE '2020-08-01' Y '2020-08-31' /* 6 */ Y a.evento.ubicación = Moscone Center /* 7 */ Y a.evento.nombre = Índice N1QL Flex vs ElasticSQL /* 8 */ Y a.evento.vendedor = Kempinski /* 9 */ Y a.evento.tema = CouchbaseRed /* 10 */ Y a.id.cuenta = "acc134 /* 11 */ Y a.nombre.de.cuenta = Horizon Cellular /* 12 */ Y a.propietario.id = usr24 /* 13 */ Y a.propietario.nombre = John Higgins |
Plan de consulta:

Ejecución de consultas:

Puntos clave: La consulta puede tener cualquier número variable de predicados, y en cualquier combinación de campos, y la consulta debe seguir considerando el índice FTS.
3) Flex Index Query con combinaciones de operadores lógicos - AND/OR
La ventaja del índice FTS con respecto a las combinaciones de predicados también se extiende más allá con la forma en que se crea cada uno de los campos del índice. Dado que cada campo indexado tiene su propia estructura invertida y que la rutina Bleve crea un mapa de bits para cada condición de búsqueda, las combinaciones de predicados como AND/OR/NOT se procesan de forma mucho más eficiente en comparación con el intersect-scan con índice B-Tree.
El ejemplo siguiente muestra que, aunque hay varios operadores lógicos OR en la consulta, el operador todos_los_actos Se sigue considerando el índice FTS.
|
1 2 3 4 5 6 7 8 9 10 |
SELECCIONE * DESDE crm a UTILIZAR ÍNDICE (USO DE FTS) DONDE a.tipo=Actividad Y ( a.dept = "iA88 O a.región > '59416' ) Y a.prioridad = Alto Y ( a.act_date ENTRE '2018-01-01' Y '2018-08-31' O a.evento.ubicación = Moscone Center ) Y ( a.id.cuenta = acc100 O a.propietario.nombre = Amanda Morrison) LÍMITE 10 |
Plan de consulta:

Ejecución de consultas:
![]()
4) La consulta incluye varios predicados de matriz
La versatilidad del índice FTS no se limita a su capacidad para utilizar el índice con sólo un subconjunto de los campos indexados en la condición de búsqueda, o su capacidad para combinar eficazmente los resultados de la búsqueda con operadores lógicos. Sino también la forma en que el índice FTS maneja los elementos de array, lo que permite que la consulta N1QL tenga cualquier número de predicados de array.
Ahora vamos a ampliar la consulta con predicados de matriz:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECCIONE * DESDE crm a DONDE a.tipo=Actividad UTILIZAR ÍNDICE (USO DE FTS) /* 1 */ Y a.título COMO Anuncio de Couchbase Flex Index% /* 2 */ Y a.dept = st55 /* 3 */ Y a.región = '00528' /* 4 */ Y a.prioridad = Alto /* 5 */ Y a.act_date ENTRE '2020-08-01' Y '2020-08-31' /* 6 */ Y a.evento.ubicación = Moscone Center Sur /* 7 */ Y a.evento.nombre = Índice N1QL Flex vs ElasticSQL /* 8 */ Y a.evento.vendedor = Kempskinki /* 9 */ Y a.evento.tema = CouchbaseRed /* 10 */ Y a.id.cuenta = "acc134 /* 11 */ Y a.nombre.de.cuenta = Horizon Cellular /* 12 */ Y a.propietario.id = usr24 /* 13 */ Y a.propietario.nombre = Binh Le /* 14 */ Y CUALQUIER pa EN a.participantes SATISFACE nombre.pa COMO Randy% FIN /* 15 */ Y CUALQUIER co EN a.cita.contactos SATISFACE co.título COMO Sistema Arch% FIN |
Debe añadir las dos matrices al índice como asignaciones secundarias, como se indica a continuación.
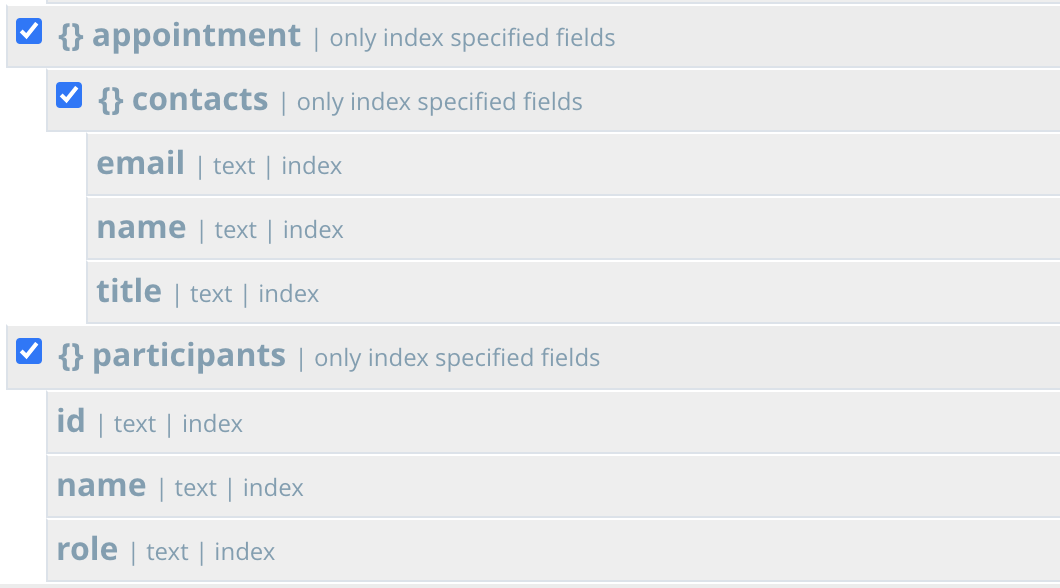
5) La sintaxis de búsqueda de diferencias
Se trata de un caso de uso en el que se utiliza FTS principalmente para la búsqueda por palabras clave y se prefiere una sintaxis de predicado de búsqueda más sencilla, similar a la de SQL.

N1QL y Búsqueda sin limitaciones
Las aplicaciones empresariales modernas requieren tanto una búsqueda exacta como una búsqueda de texto. Para la búsqueda exacta, la mayoría de los RDBMS proporcionan índices basados en B-Tree para satisfacer las necesidades. Los requisitos de búsqueda de texto han aumentado la popularidad de los motores de búsqueda basados en Lucene, como ElasticSearch y Solr.
- Oracle NoSQL dispone ahora de integración con ElasticSearch: https://docs.oracle.com/en/database/other-databases/nosql-database/18.1/full-text-search/index.html#NSFTL-GUID-E409CC44-9A8F-4043-82C8-6B95CD939296
- Las aplicaciones basadas en Oracle Enterprise RDBMS también ofrecen la capacidad de ElasticSearch como opción mediante el conjunto de aplicaciones CX. https://www.oracle.com/webfolder/technetwork/tutorials/tutorial/cloud/r13/wn/engagement/releases/20B/20B-engagement-wn.htm
Pero adoptar la funcionalidad de ElasticSearch en un modelo de datos RDBMS altamente normalizado conlleva una serie de retos.
- Los requisitos de recursos para configurar ElasticSearch, así como los requisitos de almacenamiento para ingerir los datos RDBMS para la base de datos ElasticSearch.
- La necesidad de desnormalizar ampliamente el modelo de datos, ya que la búsqueda basada en Lucene no admite JOIN de bases de datos.
- El esfuerzo de desarrollo para implementar la búsqueda utilizando las API de ElasticSearch.
El esfuerzo para los clientes que quieren utilizar ElasticSearch es una de las razones clave por las que hemos visto la adopción de SQL en estas bases de datos NoSQL.
- Elasticsearch con SQL. https://www.elastic.co/what-is/elasticsearch-sql
- Opendistro para Elasticsearch con SQL. https://opendistro.github.io/for-elasticsearch/features/SQL%20Support.html
- MongoDB ha añadido la búsqueda a MQL utilizando Lucene en su oferta Atlas. https://www.mongodb.com/atlas/search
Pero las implementaciones SQL de estas bases de datos vienen con una larga lista de limitaciones.
- Limitaciones de ElasticSQL: https://www.elastic.co/guide/en/elasticsearch/reference/current/sql-limitations.html
- No admite operaciones de conjuntos, uniones, etc.
- Sin funciones de ventana.
- La integración de búsqueda de MQL de MongoDB viene con una larga lista de limitaciones.
- Disponible sólo en el servicio de búsqueda Atlas, no en el producto local.
- La búsqueda sólo puede ser la PRIMERA operación dentro de la cadena aggregate().
- Disponible sólo dentro de la cadena de agregación (aggregate()), lo que significa que no puede utilizarse con actualizaciones o eliminaciones como predicado.
Couchbase, por otro lado, ha tenido N1QL y Full Text Search durante muchos años. El lenguaje de consulta soporta todas las operaciones que esperarías ver en una base de datos madura, soportando uniones tipo RDBMS, agregaciones, optimización de consulta basada en reglas y basada en costes. Lo más importante son las construcciones adicionales, como las operaciones NEST, UNNEST y ARRAY, que permiten al lenguaje N1QL trabajar de forma nativa con documentos JSON.
El punto importante sobre Couchbase N1QL con respecto a las capacidades de búsqueda es que Couchbase Full Text Search está perfectamente integrado en su lenguaje N1QL.
- Función de búsqueda N1QL de Couchbase 6.5. https://docs.couchbase.com/server/current/n1ql/n1ql-language-reference/searchfun.html
- Couchbase 6.6 Flex Index (el tema de este artículo). https://docs.couchbase.com/server/6.6/n1ql/n1ql-language-reference/flex-indexes.html
Flex Index con la potencia de N1QL
A continuación se muestra un ejemplo de consulta N1QL para un requisito de analizar i) cuánto tiempo ha dedicado el equipo de ventas a trabajar con todos los clientes por industriay también ii) devuelve los tres primeros competencias de los miembros del equipo de ventas que han trabajado con estos clientes.
La consulta muestra que Couchbase Flex Index se puede utilizar con la combinación de cualquier característica de N1QL.

Consideraciones sobre el índice Flex
El debate hasta ahora ha ilustrado con ejemplos cómo la función de índice Flex puede aprovechar un único índice FTS de campos múltiples para satisfacer todos los diferentes tipos de combinaciones de predicados y consultas con múltiples matrices, mientras que con GSI necesitaría tener varios índices. Pero, ¿cuál sería el impacto en el tamaño del índice de utilizar un índice FTS en lugar de GSI? La siguiente tabla muestra los tamaños de índice en mi configuración local de Couchbase.
Tamaño del índice
La siguiente tabla muestra un ejemplo del tamaño del índice basado en el conjunto de datos del modelo de actividad crm.
Tamaño del documento: 1.5K. Recuento de documentos: 500K
| Opciones de índice | Índice GSI Tamaño | Tamaño del índice FTS | Diferencia de almacenamiento |
| Índice de 13 campos | 205 MB | 252 MB | +25% |
| 13 campos + todos elementos de ambas matrices | N/A | 357 MB | – |
El propósito de la tabla anterior no es proporcionar un tamaño exacto de los dos tipos de índices, sino más bien las diferencias de tamaño relativas entre ellos.
- El índice FTS tiene un tamaño aproximadamente 25% mayor que el índice GSI. Esta cifra refleja los datos de la muestra y la distribución de los campos indexados.
- Se ahorra mucho cuando intervienen elementos de matriz.
- El índice FTS puede incluir todos los elementos de ambas matrices en un único índice.
Rendimiento de las consultas
Tanto Couchbase Indexing como Indexación de la búsqueda de texto completo han sido diseñados para escalar con Multi Dimensional Scaling, y Alta Disponibilidad. Dicho esto, estos servicios están diseñados para cumplir objetivos diferentes. El servicio de indexación funciona mejor para requisitos de alta latencia y alto rendimiento. Se espera que las condiciones de búsqueda para estas consultas estén bien definidas con conjuntos de resultados pequeños. El servicio FTS, por su parte, se diseñó con un analizador avanzado para añadir un elemento de imprecisión, teniendo en cuenta el lenguaje, así como para proporcionar una puntuación de relevancia para cada resultado.
- Las consultas que se basan en Flex Index siempre incluirán un
buscaren el procesamiento de la consulta. Esto se debe a que el servicio de consulta seguirá realizando elfiltrofase. - La optimización del rendimiento de las consultas, como la agregación push-down al índice, sólo está disponible con GSI, y no con Flex Index.
- Las consultas de índices cubiertos sólo están disponibles con GSI.
- Con Flex Index, la paginación de consultas se realiza a nivel de consulta, ya que la paginación no se puede transferir a FTS.
- Para las consultas JOIN, sólo los campos que se pueden utilizar en una consulta de búsqueda FTS se pasarán a Flex Index.
Resumen
Mientras que muchas bases de datos NoSQL están tratando de mejorar sus lenguajes de consulta, ya sea imitando SQL indirectamente con MQL, o directamente con SQL en ElasticSQL, para proporcionar la capacidad de realizar búsqueda de coincidencia exacta, así como búsqueda de texto. Sólo Couchbase N1QL Flex Index proporciona ambos tipos de búsqueda sin problemas con N1QL SEARCH(), y ahora con predicados estándar disponibles en N1QL Flex Index. Tu conocimiento de SQL es todo lo que necesitas para desarrollar una aplicación que aproveche ambos tipos de búsqueda. Además, la búsqueda de texto también puede combinarse con todas las características de N1QL, JOIN/Agregación/CTE y Funciones de Ventana Analítica avanzadas, y NEST/UNNEST/ARRAY para sus documentos JSON.
Referencias
- El conjunto de datos de muestra del Modelo de Datos de Gestión de Actividades utilizado en este artículo. https://couchbase-sample-datasets.s3.us-east-2.amazonaws.com/crm.tar
Explorar los recursos de Couchbase Server 6.6